Software Project Management & Team Dynamics
Diagrams
Software project management is the discipline of planning, organizing, and directing the work of engineering teams to deliver software systems on time, within scope, and at acceptable quality. Team dynamics -- the behavioral patterns and interpersonal forces that shape how people collaborate -- are inseparable from project management because even the most rigorous process will fail if the humans executing it cannot communicate, trust each other, and resolve conflict effectively. This topic covers the methodologies, estimation techniques, metrics, and collaboration patterns that distinguish high-performing engineering organizations from dysfunctional ones.
Concepts
Agile Methodologies
Agile is not a single methodology but a family of frameworks united by the values expressed in the Agile Manifesto (2001): individuals and interactions over processes and tools, working software over comprehensive documentation, customer collaboration over contract negotiation, and responding to change over following a plan. The three most widely adopted frameworks are Scrum, Kanban, and Extreme Programming.
Scrum
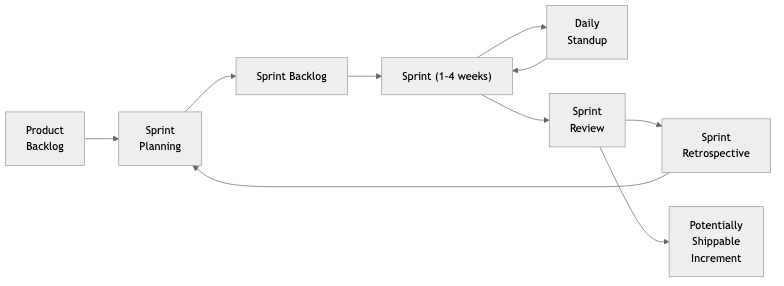
Scrum organizes work into fixed-length iterations called sprints, typically lasting one or two weeks. Each sprint begins with a planning ceremony where the team selects items from a prioritized product backlog. A daily standup (15 minutes maximum) synchronizes the team. At the end of the sprint the team holds a review (demonstrating completed work to stakeholders) and a retrospective (inspecting the process itself). Three roles define accountability: the Product Owner owns the backlog and prioritization, the Scrum Master facilitates the process and removes impediments, and the Development Team executes the work. The Sprint Backlog is the team's commitment for the iteration, and the Definition of Done codifies what "complete" means for every item.
Scrum works best when requirements are uncertain, stakeholder feedback is frequent, and teams are co-located or have strong asynchronous communication habits. It struggles when work is heavily interrupt-driven (e.g., production support) or when items cannot be meaningfully decomposed into sprint-sized increments.
Kanban
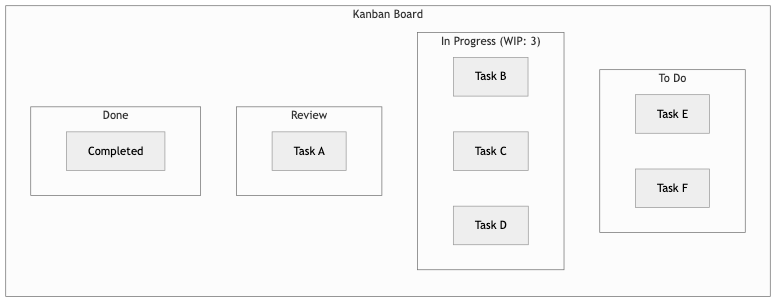
Kanban originates from Toyota's manufacturing system and emphasizes continuous flow rather than time-boxed iterations. Work items move through a visual board with columns representing stages (e.g., To Do, In Progress, Review, Done). The central mechanism is the work-in-progress (WIP) limit: each column has a maximum number of items allowed at any time. When a column reaches its limit, upstream work must wait, which exposes bottlenecks and forces the team to finish existing work before starting new work.
Kanban does not prescribe roles, ceremonies, or estimation. Teams measure cycle time (how long an item takes from start to finish) and throughput (how many items complete per unit of time). These metrics enable probabilistic forecasting without requiring story-point estimation. Kanban is well-suited for teams handling a mix of planned and unplanned work, such as platform teams, DevOps groups, and support organizations.
Extreme Programming (XP)
XP is the most prescriptive of the three frameworks. It mandates specific engineering practices: pair programming, test-driven development (TDD), continuous integration, collective code ownership, simple design, refactoring, and small releases. XP also prescribes planning games (a form of iterative planning), on-site customers (embedding a business representative with the team), and sustainable pace (no chronic overtime).
XP's strength is that it directly addresses code quality and technical risk. Its weakness is cultural resistance: pair programming and TDD require significant behavioral change and organizational buy-in. Many teams adopt XP practices selectively rather than wholesale.
Estimation Techniques
Story Points
Story points are a relative measure of effort, complexity, and uncertainty. Rather than estimating in hours, teams assign a point value to each user story by comparing it to a reference story. The Fibonacci sequence (1, 2, 3, 5, 8, 13, 21) is commonly used because the increasing gaps reflect the growing uncertainty of larger items. Teams typically estimate using Planning Poker, where each member privately selects a card and all cards are revealed simultaneously to avoid anchoring bias. Discrepancies trigger discussion, and the team converges on a consensus.
Velocity -- the number of story points completed per sprint -- stabilizes over several sprints and becomes the primary input for forecasting. If a team's velocity averages 30 points per sprint, a 120-point epic should take roughly four sprints. The precision of this forecast depends on consistent estimation habits and stable team composition.
T-Shirt Sizing
T-shirt sizing (XS, S, M, L, XL, XXL) is a coarser estimation method used for early-stage roadmap planning when detailed requirements are unavailable. Each size maps to a rough range of effort. T-shirt sizing is faster than story points and reduces arguments over whether something is a 5 or an 8. Teams often use T-shirt sizing for quarterly planning and convert to story points once items are refined for sprint planning.
Monte Carlo Simulation
Monte Carlo simulation uses historical throughput data to generate probabilistic forecasts. The method repeatedly samples from past sprint data (how many items were completed per sprint) and simulates thousands of possible futures. The output is a probability distribution: for example, "there is an 85% chance this project will be done in 6 sprints or fewer." Monte Carlo forecasting does not require story-point estimation at all -- it only needs a count of items and historical throughput. This makes it especially attractive for Kanban teams and for organizations skeptical of estimation accuracy.
Technical Debt Prioritization
Technical debt is the accumulated cost of shortcuts, deferred maintenance, and suboptimal design decisions. Not all technical debt is equal. A useful framework classifies debt along two axes: impact (how much it slows the team or risks production) and effort (how expensive it is to remediate).
High-impact, low-effort debt should be addressed immediately. High-impact, high-effort debt requires dedicated initiatives or progressive remediation. Low-impact debt may be acceptable indefinitely. The key discipline is making debt visible: maintaining a tech debt backlog, tagging debt items in the issue tracker, and regularly reviewing them alongside feature work. Many teams allocate a fixed percentage of each sprint (10-20%) to debt reduction to prevent accumulation from becoming unmanageable.
Strategies for managing tech debt include the Boy Scout Rule (leave code better than you found it), scheduled refactoring sprints, "fix-it" weeks, and embedding debt reduction into the Definition of Done for related features.
Engineering Metrics
Metrics are necessary for managing what you cannot directly observe, but poorly chosen metrics create perverse incentives. The DORA (DevOps Research and Assessment) metrics are the most rigorously validated set of software delivery performance indicators:
- Deployment Frequency: How often the team deploys to production. High performers deploy on demand, multiple times per day.
- Lead Time for Changes: The time from code commit to running in production. High performers measure this in less than one day.
- Change Failure Rate: The percentage of deployments that cause a failure requiring remediation. High performers keep this below 15%.
- Mean Time to Restore (MTTR): How quickly the team recovers from a failure. High performers restore service in less than one hour.
Beyond DORA, teams commonly track sprint velocity, cycle time, code review turnaround time, and escaped defect rates. The SPACE framework (Satisfaction, Performance, Activity, Communication, Efficiency) provides a broader lens that includes developer experience alongside delivery metrics.
A critical principle is Goodhart's Law: "When a measure becomes a target, it ceases to be a good measure." Metrics should inform conversations, not drive individual performance evaluations. Using lines of code, commit count, or pull request volume as productivity proxies almost always leads to gaming and toxic behavior.
Cross-Functional Collaboration
Modern software development requires collaboration among engineers, product managers, designers, data scientists, QA specialists, security engineers, and site reliability engineers. Cross-functional teams -- where all necessary skills are represented within a single team -- reduce handoffs, shorten feedback loops, and increase ownership.
Effective cross-functional collaboration depends on shared context. Techniques include:
- Joint discovery sessions: Engineers participate in user research and customer interviews alongside product managers and designers.
- Three Amigos: Before development begins, a developer, a tester, and a product representative review each story to clarify requirements and identify edge cases.
- Design reviews: Engineers review UX mocks and prototypes early, flagging feasibility concerns before design is finalized.
- Blameless postmortems: After incidents, all involved parties reconstruct the timeline and identify systemic improvements without assigning blame.
Technical Writing: RFCs and Design Documents
Written communication scales better than verbal communication. Two document types are especially important in engineering organizations:
RFCs (Requests for Comments) are proposals for significant changes -- new systems, architectural shifts, process changes, or deprecations. An RFC typically includes the problem statement, proposed solution, alternatives considered, risks, and an open questions section. The RFC is circulated for asynchronous review, and stakeholders leave comments. After a review period (often one to two weeks), the author addresses feedback and the RFC is either approved, rejected, or revised. RFCs create a durable record of design decisions and their rationale, which is invaluable for future engineers who need to understand why a system was built a certain way.
Design documents (sometimes called tech specs) are more detailed than RFCs and focus on implementation. They typically include system architecture diagrams, data models, API contracts, failure modes, rollout plans, and testing strategies. Design docs are reviewed by peers and senior engineers before implementation begins, catching design flaws when they are cheapest to fix.
Both document types depend on a culture that values writing. Organizations that invest in technical writing standards, templates, and review norms consistently produce better-aligned teams and fewer costly misunderstandings.
Business Value
Software project management and team dynamics directly affect the bottom line in ways that are measurable but often underappreciated until something goes wrong.
Predictability enables business planning. When engineering teams can forecast delivery dates with reasonable confidence, product marketing can plan launches, sales can set customer expectations, and finance can model revenue. Unpredictable delivery undermines trust between engineering and the rest of the organization, leading to padding, micromanagement, and adversarial relationships.
Reduced waste translates to cost savings. Poor project management leads to building the wrong thing (wasted features), building the right thing poorly (rework), and building things in the wrong order (missed market windows). Studies consistently show that 40-60% of features in enterprise software are rarely or never used. Better prioritization and tighter feedback loops reduce this waste significantly.
Developer retention depends on team dynamics. The cost of replacing a software engineer is estimated at 50-200% of annual salary when factoring in recruiting, onboarding, lost productivity, and knowledge drain. Teams with healthy dynamics -- psychological safety, clear expectations, autonomy, and growth opportunities -- retain engineers far longer than teams plagued by dysfunction, burnout, or mismanagement.
Technical debt has compounding costs. Like financial debt, technical debt accrues interest. A study by Stripe estimated that developers spend 33% of their time dealing with technical debt. At scale, this represents billions of dollars in lost productivity across the industry. Proactive debt management preserves velocity and reduces the risk of catastrophic system failures.
Engineering metrics drive continuous improvement. Organizations that measure and act on DORA metrics consistently outperform those that do not, not just in software delivery but in organizational performance broadly. The correlation between software delivery performance and business outcomes (profitability, market share, customer satisfaction) has been validated across thousands of organizations.
Real-World Examples
Spotify's Squad Model
Spotify popularized a team topology that organized engineers into autonomous "squads" (small cross-functional teams), grouped into "tribes" (collections of squads working in related areas), with "chapters" (functional groupings like backend or QA) and "guilds" (interest-based communities) providing cross-cutting alignment. The model emphasized team autonomy, alignment through mission rather than directives, and minimal process overhead. While influential, Spotify itself later acknowledged that the model was aspirational rather than fully realized, and many organizations that copied it struggled because they adopted the structure without the underlying culture of trust and experimentation. The lesson is that organizational models are not transferable without the cultural substrate that makes them work.
Google's Project Aristotle
In 2012, Google launched Project Aristotle to determine what makes teams effective. After studying 180 teams across the company, researchers found that the single most important factor was psychological safety -- the belief that one can take interpersonal risks without fear of punishment. Teams with high psychological safety were more likely to harness diverse perspectives, admit mistakes, ask questions, and experiment. The other factors, in order of importance, were dependability (team members complete work on time and at quality), structure and clarity (clear roles, plans, and goals), meaning (the work is personally important), and impact (the team believes its work matters). Notably, team composition factors (seniority, tenure, co-location) were far less predictive than these behavioral norms.
Amazon's Two-Pizza Teams and Working Backwards
Amazon structures engineering around "two-pizza teams" (small enough to be fed by two pizzas, typically 6-10 people) that own a service end-to-end. This model enforces small blast radius, clear ownership, and minimal cross-team coordination. Amazon's "Working Backwards" process requires teams to write a press release and FAQ before building anything, forcing clarity on customer value before engineering effort begins. The six-page narrative memo, read silently at the start of meetings, replaces slide decks and ensures deep engagement with ideas. These practices embed project management discipline into the culture without heavy process overhead.
Microsoft's Shift to Engineering Metrics
Under Satya Nadella's leadership, Microsoft transformed its engineering culture from one infamous for stack ranking (forced curve performance reviews that pitted employees against each other) to one centered on growth mindset and collaborative metrics. The company adopted DORA metrics, invested in developer experience measurement, and shifted performance evaluation from individual output to team impact and learning. This cultural shift correlated with dramatic improvements in Azure's reliability, Visual Studio Code's rapid iteration, and the company's overall market performance. The transformation demonstrated that changing how you measure and manage people can have outsized effects on technical outcomes.
Common Mistakes & Pitfalls
1. Treating Agile as a Set of Ceremonies Rather Than a Mindset
Organizations frequently adopt the rituals of Scrum (standups, sprints, retrospectives) without internalizing the values. The result is "Cargo Cult Agile" -- teams go through the motions but continue to work in a waterfall mindset with fixed scope, fixed timeline, and no genuine adaptation. Standups become status reports to managers rather than synchronization among peers. Retrospectives generate action items that are never followed up on. The fix is to evaluate whether the team is actually inspecting and adapting, not merely performing the rituals.
2. Using Velocity as a Performance Metric
Velocity is a planning tool, not a performance measure. When management uses velocity to compare teams or evaluate individuals, teams respond by inflating estimates. A story that was a "3" becomes a "5," and velocity appears to increase while actual output remains constant. This destroys the usefulness of velocity for forecasting and creates a toxic dynamic where teams optimize for the metric rather than for delivery. Velocity should only be visible to the team and used solely for sprint planning.
3. Ignoring Technical Debt Until It Becomes a Crisis
Teams under delivery pressure consistently defer maintenance, leading to a gradual degradation of the codebase. The debt is invisible to non-technical stakeholders until it manifests as escalating bug rates, slowing velocity, or a major outage. By that point, remediation is far more expensive. The antidote is making debt visible through tracking, allocating regular capacity for debt reduction, and educating stakeholders about the long-term cost of deferral.
4. Over-Indexing on Individual Productivity
Measuring individual output (commits, pull requests, stories completed) incentivizes local optimization at the expense of team outcomes. An engineer who writes the most code but never reviews others' work, refuses to mentor juniors, or builds systems that only they can maintain is a net negative despite impressive individual metrics. Healthy organizations measure team-level outcomes and evaluate individuals on collaboration, knowledge sharing, and system-level impact.
5. Skipping Design Documents for "Move Fast" Culture
Startups and growth-stage companies often view design documents as bureaucratic overhead. The result is that critical architectural decisions are made in Slack threads that disappear, in meetings with no notes, or implicitly through code that embeds assumptions no one else understands. When the original author leaves, the organization loses the rationale behind key decisions. Even lightweight design documents -- a single page covering the problem, approach, and key trade-offs -- provide enormous long-term value relative to their cost.
6. Conducting Blameful Postmortems
When incident reviews focus on finding the person who "caused" the outage, engineers learn to hide mistakes, avoid risky improvements, and cover their tracks. Blameful cultures suppress the information flow that is essential for systemic improvement. Blameless postmortems, by contrast, assume that the humans involved were acting rationally given the information available to them, and focus on identifying the systemic conditions (tooling gaps, unclear runbooks, insufficient monitoring) that allowed the failure to occur. The goal is learning, not punishment.
Trade-offs
| Dimension | Scrum | Kanban | XP | |---|---|---|---| | Planning cadence | Fixed sprints (1-4 weeks) | Continuous flow | Short iterations (1-2 weeks) | | Estimation required | Yes (story points typical) | No (throughput-based forecasting) | Yes (ideal days or story points) | | Roles prescribed | Product Owner, Scrum Master, Dev Team | None prescribed | Coach, Customer, Programmer, Tester | | WIP management | Implicit (sprint capacity) | Explicit (WIP limits per column) | Implicit (pair programming limits parallelism) | | Engineering practices | Not prescribed | Not prescribed | Heavily prescribed (TDD, pairing, CI) | | Best for | Product development with regular stakeholder feedback | Mixed planned and unplanned work, operations | Teams willing to commit to disciplined engineering practices | | Overhead | Medium (ceremonies take 10-15% of sprint) | Low (minimal required meetings) | High (pairing and TDD have significant upfront cost) | | Adoption difficulty | Moderate | Low | High |
| Estimation Method | Speed | Precision | Requires Historical Data | Best Context | |---|---|---|---|---| | Story points | Medium | Medium | No (but velocity needs history) | Sprint planning for established teams | | T-shirt sizing | Fast | Low | No | Roadmap planning, early-stage estimation | | Monte Carlo simulation | Slow (setup), fast (ongoing) | High (probabilistic) | Yes | Forecasting delivery dates with confidence intervals | | Time-based estimation (hours) | Slow | Deceptively precise | No | Contractor billing, regulatory compliance |
| Metric Category | Measures | Risk of Misuse | Recommended Use | |---|---|---|---| | DORA metrics | Delivery performance | Low (team-level, outcome-oriented) | Organizational benchmarking, continuous improvement | | Velocity | Sprint capacity | High (easily gamed if used for evaluation) | Team-internal planning only | | Lines of code | Nothing useful | Very high | Never use as a performance metric | | Cycle time | Flow efficiency | Low | Identifying bottlenecks, process improvement | | Code review turnaround | Collaboration health | Medium (can incentivize rubber-stamping) | Team retrospectives, identifying review bottlenecks |
When to Use / When Not to Use
When to Adopt Formal Agile Frameworks
Use when:
- The team has more than three or four people and needs coordination mechanisms beyond informal conversation.
- Requirements are evolving and stakeholder feedback is frequent.
- The organization is willing to invest in the cultural changes that Agile requires (transparency, team autonomy, iterative delivery).
- Delivery predictability matters to the business.
Do not use when:
- The team is very small (two or three people) and communicates constantly -- lightweight ad hoc coordination may suffice.
- The work is well-defined, sequential, and unlikely to change (e.g., regulatory compliance implementations with fixed specifications). In such cases, a structured plan-driven approach may be more appropriate.
- The organization is unwilling to change its management culture. Imposing Agile ceremonies on a command-and-control organization produces frustration without benefit.
When to Invest in Estimation
Use when:
- Stakeholders need delivery forecasts for business planning (launches, contracts, budgets).
- The team needs to make scope decisions (what fits in a release).
- Historical data is available to calibrate estimates.
Do not use when:
- The team is in pure exploration mode (research spikes, prototyping) where the goal is learning rather than delivery.
- The cost of estimation exceeds its value. For small tasks (less than a day of work), the overhead of formal estimation is not justified.
- The team has strong throughput data and can use Monte Carlo methods instead.
When to Write RFCs and Design Documents
Use when:
- The change affects multiple teams or systems.
- The decision is difficult to reverse (data model changes, API contracts, infrastructure migrations).
- The team has more than five or six engineers and implicit knowledge transfer is insufficient.
- There is a history of misaligned expectations between stakeholders and engineers.
Do not use when:
- The change is small, well-understood, and easily reversible.
- The team is very small, co-located, and already has strong shared context.
- The document would be written purely for compliance rather than to drive genuine alignment (though even then, a lightweight version is usually worthwhile).
When to Prioritize Technical Debt Reduction
Use when:
- Velocity is declining sprint over sprint and the team attributes it to codebase friction.
- Incident frequency is increasing due to fragile or poorly understood systems.
- Onboarding time for new engineers is growing because the codebase is difficult to navigate.
- A planned feature requires building on top of a poorly designed subsystem.
Do not use when:
- The debt is in a system that is scheduled for decommission.
- The team is in a genuine time-critical sprint toward a hard external deadline and the debt does not affect the current work.
- The debt is cosmetic (naming conventions, code style) rather than structural, and automated tooling can address it incrementally.
Key Takeaways
-
Process serves people, not the other way around. Agile frameworks are tools, not religions. Adopt the practices that help your team deliver better software and discard those that create overhead without value. The best process is the one that the team continuously improves through honest retrospection.
-
Estimation is about communication, not precision. The purpose of estimation is not to predict the future accurately but to create shared understanding of scope, complexity, and risk. A conversation about why two engineers estimated differently is often more valuable than the number they converge on.
-
Psychological safety is the foundation of team performance. Google's research and decades of organizational psychology confirm that teams where members feel safe to speak up, disagree, and admit mistakes consistently outperform teams where fear suppresses information flow. Leaders build psychological safety through modeling vulnerability, responding constructively to bad news, and separating learning from punishment.
-
Metrics should inform, not govern. Measure what matters (delivery performance, customer outcomes, developer experience), use metrics to identify trends and prompt investigation, but never optimize for the metric itself. Goodhart's Law is not a theoretical concern -- it is a reliable prediction of human behavior under measurement pressure.
-
Technical debt is a strategic decision, not a moral failing. Taking on debt to meet a market window is rational. Failing to track, communicate, and eventually repay that debt is negligent. The discipline is in making debt conscious and visible rather than pretending it does not exist.
-
Written communication compounds in value. RFCs, design documents, postmortem reports, and decision logs cost hours to write but save weeks of misalignment, rework, and archaeological expeditions through old code. Organizations that write well build better software because they think more clearly before they build.
-
Cross-functional collaboration reduces waste at the boundaries. Most defects, delays, and misunderstandings originate at the interfaces between disciplines -- between product and engineering, between design and implementation, between development and operations. Techniques that bring these disciplines together early (Three Amigos, joint discovery, embedded SREs) eliminate waste that no amount of downstream process can recover.
Further Reading
Books
-
"Accelerate: The Science of Lean Software and DevOps" by Nicole Forsgren, Jez Humble, and Gene Kim. The definitive research-backed treatment of software delivery performance, DORA metrics, and their correlation with organizational outcomes. Essential reading for engineering leaders.
-
"Team Topologies: Organizing Business and Technology Teams for Fast Flow" by Matthew Skelton and Manuel Pais. A practical framework for designing team structures that optimize for software delivery, covering stream-aligned teams, platform teams, enabling teams, and complicated-subsystem teams.
-
"The Mythical Man-Month" by Frederick Brooks. First published in 1975 and still relevant. Brooks's law ("adding manpower to a late software project makes it later") and the distinction between essential and accidental complexity remain foundational concepts.
-
"An Elegant Puzzle: Systems of Engineering Management" by Will Larson. A modern treatment of engineering management covering team sizing, organizational design, technical debt management, and career development. Practical and grounded in real experience.
-
"Thinking in Systems: A Primer" by Donella Meadows. Not specific to software but essential for understanding feedback loops, delays, and emergent behavior in complex systems -- all of which apply directly to software teams and processes.
-
"The Five Dysfunctions of a Team" by Patrick Lencioni. A leadership fable that identifies absence of trust, fear of conflict, lack of commitment, avoidance of accountability, and inattention to results as the five cascading dysfunctions that undermine team performance.
-
"Scrum: The Art of Doing Twice the Work in Half the Time" by Jeff Sutherland. Written by one of Scrum's co-creators, this book provides both the theory and practical guidance for implementing Scrum effectively.
Articles and Papers
-
"The New New Product Development Game" by Hirotaka Takeuchi and Ikujiro Nonaka (Harvard Business Review, 1986). The original article that inspired Scrum, describing how cross-functional teams using overlapping development phases outperform sequential approaches.
-
"Measuring and Managing Technical Debt" by Philippe Kruchten, Robert Nord, and Ipek Ozkaya. A systematic treatment of technical debt taxonomy, measurement approaches, and management strategies.
-
State of DevOps Reports (DORA/Google Cloud). Published annually, these reports provide the latest research on software delivery performance, team culture, and organizational capabilities. The data set now spans over 39,000 professionals across thousands of organizations.
-
"How to Write a Good RFC" -- multiple versions exist from companies including Oxide Computer, Uber, and HashiCorp. Studying how different organizations structure their RFC processes provides practical templates and cultural insights.
-
"No Silver Bullet: Essence and Accidents of Software Engineering" by Frederick Brooks (1986). A seminal essay arguing that there is no single technique that will yield an order-of-magnitude improvement in software productivity, and that the essential difficulty of software lies in the complexity of the problem domain rather than in tooling.
-
"The SPACE of Developer Productivity" by Nicole Forsgren et al. (ACM Queue, 2021). Proposes a multidimensional framework for understanding developer productivity that goes beyond simplistic activity metrics to include satisfaction, performance, communication, and efficiency.