Storage Engines
Overview
Storage engines determine how databases physically store, retrieve, and manage data on disk and in memory. The choice of storage engine profoundly affects write throughput, read latency, space efficiency, and crash recovery characteristics.
LSM Trees (Log-Structured Merge Trees)
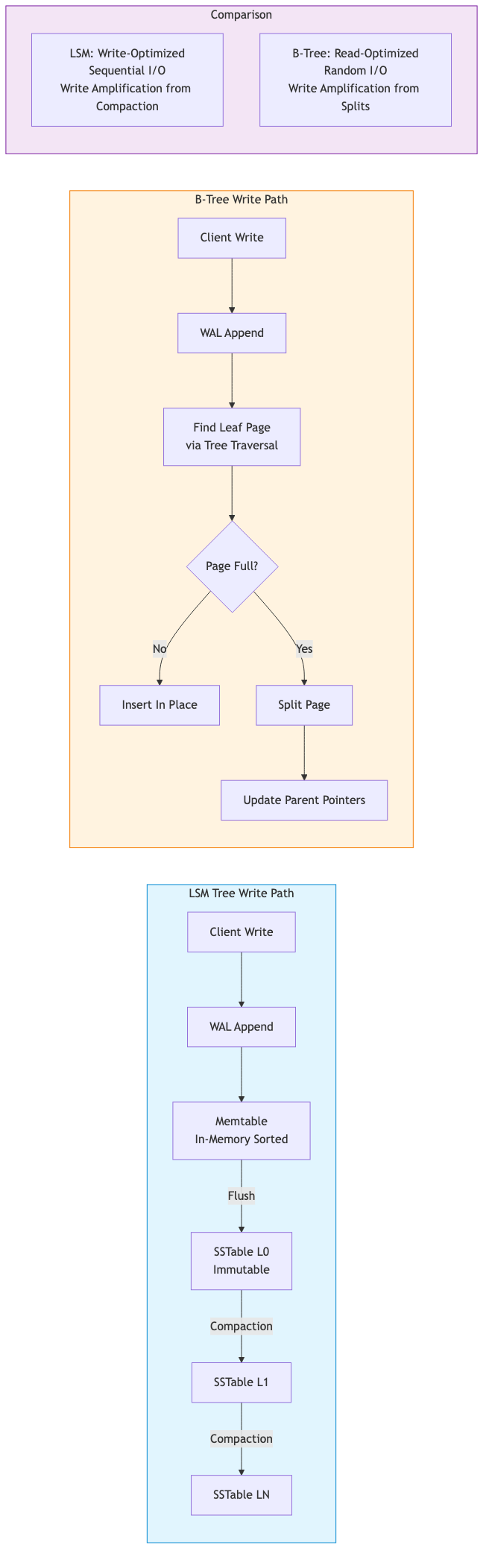
LSM trees optimize for write-heavy workloads by buffering writes in memory and periodically flushing sorted runs to disk.
Architecture
Write Path:
Client Write -> WAL (append) -> Memtable (in-memory sorted structure)
|
v (flush when full)
SSTable L0 (immutable, sorted)
|
v (compaction)
SSTable L1 ... LN
Memtable
The memtable is an in-memory sorted data structure (typically a skip list or red-black tree) that accumulates writes before flushing to disk.
# Simplified memtable with skip list semantics
class Memtable:
def __init__(self, size_limit=4 * 1024 * 1024): # 4MB default
self.entries = sortedcontainers.SortedDict()
self.size = 0
self.size_limit = size_limit
def put(self, key, value):
self.entries[key] = value
self.size += len(key) + len(value)
def get(self, key):
return self.entries.get(key)
def is_full(self):
return self.size >= self.size_limit
def flush_to_sstable(self, path):
# Write sorted key-value pairs sequentially
with SSTableWriter(path) as writer:
for key, value in self.entries.items():
writer.add(key, value)
writer.write_index() # sparse index at end
SSTable (Sorted String Table)
SSTables are immutable, sorted files on disk. Each contains a data block region, an index block, and optionally a bloom filter.
SSTable Layout:
+------------------+
| Data Block 0 | <- sorted key-value pairs
| Data Block 1 |
| ... |
| Data Block N |
+------------------+
| Meta Block | <- bloom filter, statistics
+------------------+
| Index Block | <- sparse index: key -> block offset
+------------------+
| Footer | <- offsets to index and meta blocks
+------------------+
Compaction Strategies
Size-Tiered Compaction (STCS): Merges SSTables of similar size. Good write amplification but higher space amplification and read amplification.
Tier 0: [T1] [T2] [T3] [T4] -> merge when count threshold met
Tier 1: [ T1-merged ]
Tier 2: [ T2-merged ]
Leveled Compaction (LCS): Each level has a size limit (typically 10x the previous). L0 SSTables are merged into L1, overlapping ranges in L1 are merged into L2, and so on. Better read and space amplification at the cost of higher write amplification.
L0: [a-z] [a-m] [n-z] # overlapping allowed
L1: [a-d] [e-k] [l-r] [s-z] # no overlap within level
L2: [a-b] [c-d] ... [y-z] # 10x size of L1, no overlap
B-Tree Storage
B-trees are the dominant storage structure for read-heavy and transactional workloads (PostgreSQL, MySQL/InnoDB, SQL Server).
Page Structure
B-trees operate on fixed-size pages (typically 4KB-16KB). Internal pages contain keys and child pointers; leaf pages contain keys and values (or row pointers).
Internal Page: Leaf Page:
+---+---+---+---+---+ +------+------+------+
| P0|K1 |P1 |K2 |P2 | | K1:V1| K2:V2| K3:V3|
+---+---+---+---+---+ +------+------+------+
| | | prev <-| |-> next
v v v
[<K1] [K1,K2] [>K2]
Write-Ahead Log (WAL)
Before modifying any B-tree page, the change is first recorded in the WAL to ensure crash recovery.
WAL Record Format:
+--------+--------+--------+----------+-----------+
| LSN | TxnID | PageID | OldValue | NewValue |
+--------+--------+--------+----------+-----------+
Recovery: replay WAL from last checkpoint forward
- REDO: apply committed changes not yet on disk
- UNDO: roll back uncommitted transactions
Buffer Pool Management
The buffer pool caches disk pages in memory. Eviction policies determine which pages to discard under memory pressure.
LRU-K
LRU-K tracks the last K references to each page. A page is evicted based on the backward K-distance (time since the Kth most recent access). LRU-2 is common in practice.
LRU-2 Example:
Page A: accesses at t=1, t=5 -> K-distance = 5-1 = 4
Page B: accesses at t=2, t=8 -> K-distance = 8-2 = 6
Page C: accesses at t=3 (only 1) -> K-distance = infinity
Eviction order: C first (infinite), then B (6), then A (4)
Clock Sweep (PostgreSQL)
A circular buffer with a "usage count" per page. The clock hand sweeps, decrementing counts. Pages with count 0 are evicted.
Clock hand sweeps:
[Page1: 2] [Page2: 0] [Page3: 1] [Page4: 0]
^
Decrement Page1 -> 1, move on
Page2 is 0 -> evict and replace
Page Layout: Slotted Pages
Slotted pages allow variable-length records within fixed-size pages.
+-----------------------------------------------+
| Header | Slot 0 | Slot 1 | Slot 2 | ... |
+-----------------------------------------------+
| Free Space |
+-----------------------------------------------+
| ... | Record 2 data | Record 1 data | Rec 0 |
+-----------------------------------------------+
Slot Array: [offset, length] pairs growing forward
Records: grow backward from end of page
Indirection: moving a record only updates its slot pointer
Column Storage
DSM (Decomposition Storage Model)
Each column stored in a separate file. Excellent for analytical queries touching few columns.
Row Store: Column Store (DSM):
| id | name | age | id_col: [1, 2, 3, 4]
| 1 | Alice| 30 | name_col: [Alice, Bob, Carol, Dave]
| 2 | Bob | 25 | age_col: [30, 25, 35, 28]
| 3 | Carol| 35 |
| 4 | Dave | 28 | Query: SELECT AVG(age) -> reads only age_col
PAX (Partition Attributes Across)
A hybrid: each page contains all columns but organized column-wise within the page. Preserves spatial locality for full-row access while enabling column-oriented scans within a page.
PAX Page:
+------------------------------------------+
| Page Header |
| id minipage: [1, 2, 3, 4] |
| name minipage: [Alice, Bob, Carol, Dave] |
| age minipage: [30, 25, 35, 28] |
+------------------------------------------+
Compression Techniques
Dictionary Encoding
Replace repeated values with integer codes. Highly effective for low-cardinality columns.
Original: [USA, Canada, USA, USA, Canada, Mexico]
Dictionary: {USA: 0, Canada: 1, Mexico: 2}
Encoded: [0, 1, 0, 0, 1, 2] <- stored as bit-packed integers
Run-Length Encoding (RLE)
Store consecutive identical values as (value, count) pairs. Effective on sorted columns.
Original: [A, A, A, B, B, C, C, C, C]
RLE: [(A,3), (B,2), (C,4)]
Delta Encoding
Store differences between consecutive values. Ideal for timestamps and monotonically increasing sequences.
Original: [1000, 1002, 1005, 1007, 1010]
Deltas: [1000, 2, 3, 2, 3] <- base + small deltas (fewer bits)
LZ4 and Zstandard
General-purpose block compression applied after columnar encoding.
| Algorithm | Compression Ratio | Decompress Speed | Use Case |
|---|---|---|---|
| LZ4 | ~2-3x | ~4 GB/s | Hot data, real-time queries |
| Zstandard | ~3-5x | ~1.5 GB/s | Warm/cold data, archival |
Comparison: LSM vs B-Tree
| Aspect | LSM Tree | B-Tree |
|---|---|---|
| Write throughput | High (sequential I/O) | Moderate (random I/O) |
| Read latency | Higher (multiple levels) | Lower (single tree) |
| Space amplification | Varies by compaction | Low (in-place updates) |
| Write amplification | High (compaction) | Moderate |
| Use cases | RocksDB, Cassandra | PostgreSQL, MySQL |
Applications
- RocksDB uses LSM with leveled compaction, prefix bloom filters, and column family separation
- InnoDB uses clustered B-tree indexes with a buffer pool and doublewrite buffer for crash safety
- ClickHouse uses columnar storage with LZ4/ZSTD compression and sparse primary indexes on sorted data
- SQLite uses a single B-tree per table with WAL mode for concurrent readers