Object Detection and Recognition
Overview
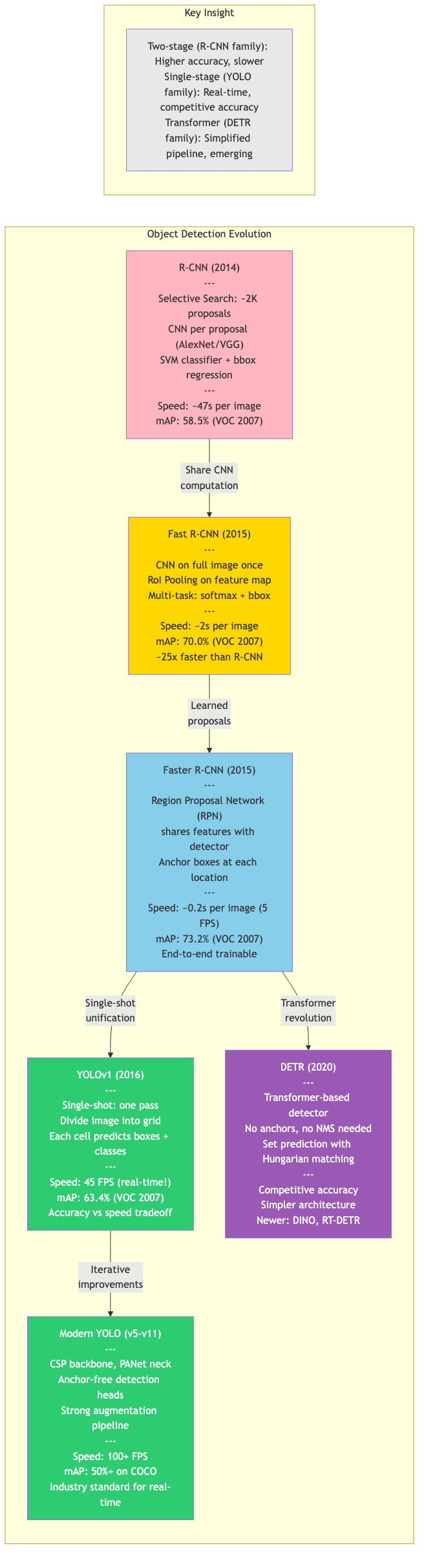
Object detection localizes and classifies objects in images, producing bounding boxes with class labels and confidence scores. The field has evolved from handcrafted features to deep learning, and from two-stage to single-shot and transformer-based architectures.
Classical Detection
HOG + SVM
Histogram of Oriented Gradients (Dalal & Triggs, 2005):
- Compute gradients: magnitude and direction at each pixel
- Cell histograms: divide image into cells (8x8 pixels), compute 9-bin orientation histogram per cell
- Block normalization: group cells into overlapping blocks (2x2 cells), L2-normalize each block's concatenated histograms
- Classification: concatenate all block descriptors into a feature vector, train linear SVM
Sliding window: scan image at multiple scales and positions, classify each window.
Deformable Parts Model (DPM): extends HOG with a root filter and deformable part filters, trained with latent SVM. Dominated detection benchmarks pre-deep learning.
Two-Stage Detectors
R-CNN (Regions with CNN features)
- Generate ~2000 region proposals (Selective Search)
- Warp each proposal to fixed size, extract CNN features (AlexNet/VGG)
- Classify with per-class SVMs
- Refine boxes with bounding box regression
Slow: CNN runs independently on each proposal.
Fast R-CNN
- Run CNN once on entire image to get feature map
- RoI Pooling: project proposals onto feature map, max-pool to fixed size
- Multi-task loss: classification (softmax) + box regression (smooth L1) in single network
- 10x faster than R-CNN at training, 150x at inference
Faster R-CNN
Replaces Selective Search with a Region Proposal Network (RPN):
- Shares convolutional features with detection network
- At each spatial location, predicts K anchor boxes (multiple scales and aspect ratios)
- Outputs objectness score + box refinement for each anchor
- NMS on proposals, top-N fed to detection head
Anchor design: typically 3 scales x 3 aspect ratios = 9 anchors per location.
Two-stage process: RPN proposes, detection head classifies and refines.
Feature Pyramid Network (FPN)
Multi-scale feature extraction via top-down pathway with lateral connections:
P5 = Conv1x1(C5)
P4 = Conv1x1(C4) + Upsample(P5)
P3 = Conv1x1(C3) + Upsample(P4)
P2 = Conv1x1(C2) + Upsample(P3)
Each level detects objects at different scales. Standard backbone for modern detectors.
Single-Shot Detectors
SSD (Single Shot MultiBox Detector)
- Multi-scale detection from multiple feature map layers (VGG-based)
- Default boxes (anchors) at each location on each feature map
- Directly predicts class scores + box offsets for each default box
- Hard negative mining: 3:1 negative-to-positive ratio
- Faster than Faster R-CNN but less accurate on small objects
YOLO Family
YOLOv1 (You Only Look Once):
- Divide image into SxS grid
- Each cell predicts B bounding boxes + confidence + C class probabilities
- Single regression problem: image pixels to boxes + classes
- Extremely fast but coarse localization
YOLOv2/v3: multi-scale detection, anchor boxes, Darknet backbone, feature pyramid.
YOLOv4: bag of freebies (data augmentation, label smoothing) + bag of specials (SPP, PAN, Mish activation). CSPDarknet backbone.
YOLOv5-v8 (Ultralytics): engineering improvements, anchor-free (v8), decoupled head, task-specific variants (detection, segmentation, pose).
YOLOv9: Programmable Gradient Information (PGI) + Generalized ELAN architecture.
YOLOv10/v11: NMS-free training with consistent dual assignments, further architectural refinements.
RetinaNet and Focal Loss
Key problem: extreme foreground-background class imbalance in single-shot detectors. Most anchors are easy negatives that dominate the loss.
Focal Loss:
FL(p_t) = -alpha_t * (1 - p_t)^gamma * log(p_t)
where p_t = p if y=1, else 1-p.
gamma = 0: standard cross-entropygamma = 2(typical): down-weights easy examples by factor(1-p_t)^2alpha_t: class balancing weight
Example: if p_t = 0.9 (easy example), focal loss is 100x smaller than CE.
Architecture: ResNet + FPN backbone, two subnetworks (classification + regression) applied to each FPN level. Matched two-stage detector accuracy with single-shot speed.
Anchor-Free Detectors
Eliminate the need for predefined anchor boxes.
CenterNet (Objects as Points)
- Predict object center as a heatmap peak (one channel per class)
- At each center, regress width, height, and optional offset
- Keypoint estimation formulation using corner pooling or center pooling
- No NMS needed (peaks are already local maxima, extracted via max-pooling)
- Simple, fast, and effective
FCOS (Fully Convolutional One-Stage)
- Per-pixel prediction: at each location, predict distances to four box sides
(l, t, r, b) - Centerness branch: suppresses low-quality predictions far from object center
centerness = sqrt(min(l,r)/max(l,r) * min(t,b)/max(t,b)) - Multi-level prediction with FPN (assign objects to levels by size)
- No anchors, no hyperparameter tuning for anchor shapes
Transformer-Based Detection
DETR (Detection Transformer)
End-to-end detection without anchors, NMS, or hand-designed components:
Architecture:
- CNN backbone extracts features
- Transformer encoder processes flattened feature map with positional encoding
- Transformer decoder takes N learned object queries and attends to encoder output
- FFN heads predict class + box for each query
Bipartite matching loss: Hungarian algorithm finds optimal 1-to-1 assignment between predictions and ground truth:
L_match = lambda_cls * L_cls + lambda_L1 * L_box + lambda_giou * L_GIoU
Properties:
- No NMS post-processing
- Learns to suppress duplicates through self-attention
- Slow convergence (500 epochs vs 36 for Faster R-CNN)
- Struggles with small objects
Deformable DETR
Addresses DETR's limitations:
- Deformable attention: attends to a small set of sampling points around a reference (not all spatial locations)
- Multi-scale deformable attention across FPN levels
- 10x fewer training epochs, better small-object performance
RT-DETR
Real-time DETR variant with hybrid encoder and efficient decoder.
Non-Maximum Suppression (NMS)
Post-processing to remove duplicate detections:
- Sort detections by confidence score
- Select highest-scoring detection
- Remove all remaining detections with IoU > threshold (typically 0.5) with selected detection
- Repeat until no detections remain
Variants:
- Soft-NMS: decay scores instead of hard removal:
s_i = s_i * exp(-IoU^2 / sigma) - Class-agnostic NMS: apply across all classes
- Batched NMS: offset boxes by class ID to prevent inter-class suppression
Evaluation Metrics
Intersection over Union (IoU)
IoU = |A ∩ B| / |A ∪ B| = |A ∩ B| / (|A| + |B| - |A ∩ B|)
A prediction is a true positive if IoU with a ground truth box exceeds a threshold (typically 0.5).
Precision-Recall and AP
- Precision: TP / (TP + FP)
- Recall: TP / (TP + FN)
- AP: area under the precision-recall curve (interpolated at 101 recall levels)
Mean Average Precision (mAP)
mAP = (1/C) * sum_{c=1}^{C} AP_c
COCO mAP (standard):
mAP@0.5: AP at IoU threshold 0.5 (PASCAL VOC metric)mAP@0.75: stricter localizationmAP@[0.5:0.95]: averaged over IoU thresholds 0.5, 0.55, ..., 0.95 (primary COCO metric)mAP_S, mAP_M, mAP_L: by object size (small < 32^2, medium < 96^2, large)
GIoU, DIoU, CIoU
Improved IoU losses for box regression:
- GIoU:
GIoU = IoU - |C \ (A ∪ B)| / |C|where C is smallest enclosing box - DIoU: adds penalty for center distance
- CIoU: adds aspect ratio consistency term
Modern Trends
- Open-vocabulary detection: detect novel categories using language embeddings (OWL-ViT, Grounding DINO)
- Foundation models: pre-train on large-scale data, fine-tune or zero-shot (DINO, Florence)
- Efficient architectures: mobile-friendly detectors (EfficientDet, NanoDet, YOLO-NAS)
- Rotated detection: oriented bounding boxes for aerial images and text detection
Key Takeaways
| Concept | Core Idea |
|---|---|
| Faster R-CNN | RPN + RoI pooling; dominant two-stage paradigm |
| YOLO | Grid-based single-shot regression; speed-optimized |
| Focal loss | Down-weight easy negatives to solve class imbalance |
| Anchor-free | Predict box properties per-pixel (FCOS) or per-center (CenterNet) |
| DETR | Transformer + Hungarian matching; end-to-end, no NMS |
| mAP@[0.5:0.95] | Standard evaluation across IoU thresholds |