Memory Models
Why Memory Models Matter
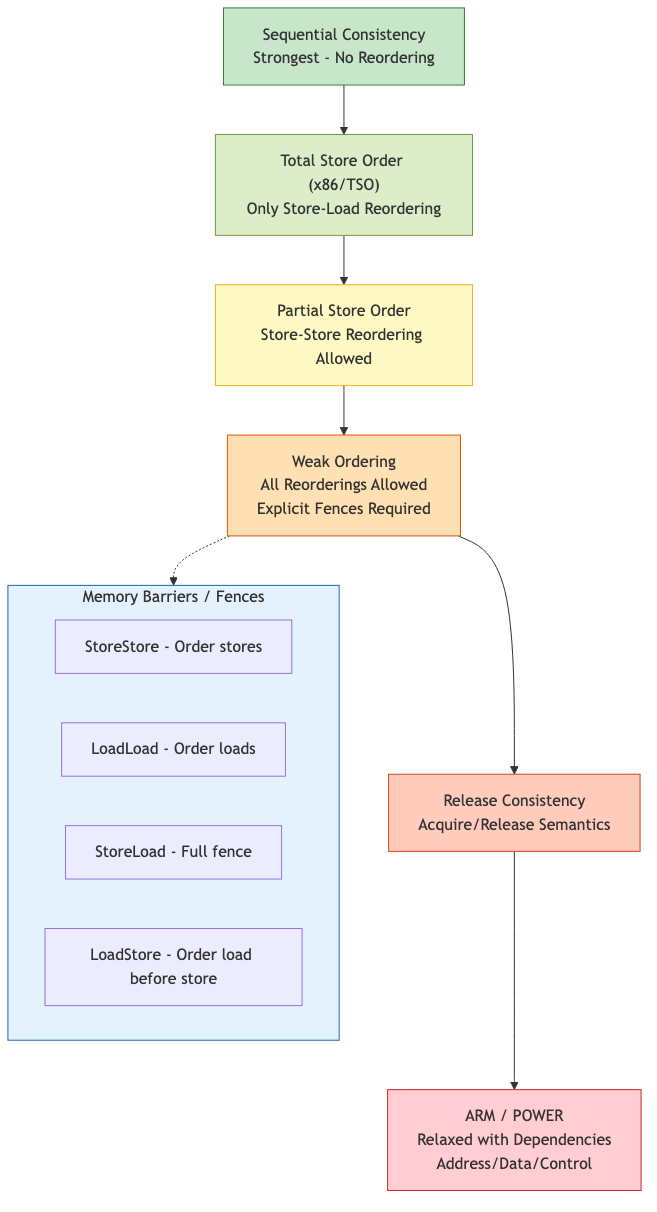
Modern processors and compilers reorder memory operations for performance. A memory model defines which reorderings are permitted, determining what values a read can return in a concurrent program.
Without a defined memory model, reasoning about concurrent code is impossible.
Sequential Consistency (SC)
Defined by Lamport (1979): the result of any execution is the same as if operations of all processors were executed in some sequential order, and the operations of each processor appear in the order specified by the program.
Properties:
1. All operations appear to execute atomically
2. Operations of each thread appear in program order
3. All threads agree on a single total order
SC is the most intuitive model but the most restrictive for hardware optimization. No modern processor implements full SC by default.
SC Violations Example
Initially: x = 0, y = 0
Thread 1: Thread 2:
x = 1 y = 1
r1 = y r2 = x
Under SC: r1 = 0 AND r2 = 0 is impossible
Under TSO: r1 = 0 AND r2 = 0 is impossible (store buffers don't allow it here)
Under relaxed: r1 = 0 AND r2 = 0 IS possible
Total Store Order (TSO) -- x86
x86 processors implement TSO, which is close to SC with one relaxation: each processor has a store buffer.
Allowed Reorderings
| Reordering | Allowed? |
|---|---|
| Store-Store | No |
| Load-Load | No |
| Load-Store | No |
| Store-Load | Yes (the only relaxation) |
A store can be delayed in the buffer, so a subsequent load to a different address may execute before the store becomes visible to other cores.
Store Buffer Forwarding
A core can read its own pending stores from the store buffer before they reach cache. This means a thread always sees its own writes immediately.
MFENCE
The MFENCE instruction drains the store buffer, providing a full memory barrier. LOCK-prefixed instructions also act as full barriers on x86.
mov [x], 1 ; store
mfence ; drain store buffer
mov eax, [y] ; load -- guaranteed to see all prior stores
Relaxed Memory Models (ARM, POWER)
ARM and POWER have much weaker memory models, allowing nearly all reorderings.
ARM (ARMv8)
| Reordering | Allowed? |
|---|---|
| Store-Store | Yes (without dependencies) |
| Load-Load | Yes (without dependencies) |
| Load-Store | Yes |
| Store-Load | Yes |
ARMv8 provides ordered instructions:
LDAR(load-acquire): no subsequent memory access can be reordered before itSTLR(store-release): no prior memory access can be reordered after itDMB(data memory barrier): full, load, or store barrier variants
POWER
Even weaker than ARM. Can reorder dependent loads in some cases (value prediction, though rare). Provides:
lwsync: lightweight sync (prevents most reorderings except store-load)hwsync/sync: heavyweight full barrierisync: instruction barrier
Practical Impact
Code that works correctly on x86 may break on ARM/POWER due to additional reorderings. Always use proper atomic operations or barriers rather than relying on architecture-specific behavior.
C/C++ Memory Model (C11/C++11)
Defines memory ordering semantics for atomic operations, independent of hardware.
Memory Orderings
enum memory_order {
memory_order_relaxed, // no ordering constraints
memory_order_consume, // data-dependency ordering (deprecated in practice)
memory_order_acquire, // read barrier: no reads/writes reordered before this load
memory_order_release, // write barrier: no reads/writes reordered after this store
memory_order_acq_rel, // both acquire and release
memory_order_seq_cst // full sequential consistency (default)
};
Relaxed Ordering
No synchronization. Only guarantees atomicity.
// Counter where ordering doesn't matter
counter.fetch_add(1, memory_order_relaxed);
Use cases: statistics counters, reference counts (increment only), progress indicators.
Acquire-Release
Creates a happens-before relationship between a release store and an acquire load of the same atomic variable.
// Thread 1 (producer)
data = 42; // (a)
ready.store(true, memory_order_release); // (b)
// Thread 2 (consumer)
while (!ready.load(memory_order_acquire)) {} // (c)
assert(data == 42); // guaranteed to pass // (d)
The release at (b) synchronizes-with the acquire at (c), establishing:
- (a) happens-before (b) (program order)
- (b) synchronizes-with (c)
- (c) happens-before (d) (program order)
- Therefore (a) happens-before (d)
Sequential Consistency (seq_cst)
Default ordering. All seq_cst operations appear in a single global total order consistent with program order of each thread.
x.store(1, memory_order_seq_cst);
r1 = y.load(memory_order_seq_cst);
Most expensive but easiest to reason about. On x86, seq_cst stores require an MFENCE or LOCK XCHG.
Ordering Cost (approximate, x86)
| Ordering | Store cost | Load cost |
|---|---|---|
| relaxed | MOV | MOV |
| release | MOV | N/A |
| acquire | N/A | MOV |
| seq_cst | MOV + MFENCE (or XCHG) | MOV |
On x86, loads are already acquire and stores are already release (due to TSO), so only seq_cst stores have additional cost.
Happens-Before Relation
The central concept in the C/C++ memory model.
Definition
Event A happens-before event B if:
- A and B are in the same thread and A precedes B in program order (sequenced-before), OR
- A synchronizes-with B (e.g., release store / acquire load pair), OR
- Transitivity: A happens-before C and C happens-before B
Data Race
Two memory accesses form a data race if:
- They access the same memory location
- At least one is a write
- They are not ordered by happens-before
- At least one is not atomic
A program with a data race on non-atomic data has undefined behavior in C/C++.
Memory Fences (Barriers)
Standalone fence instructions that enforce ordering without being tied to a specific atomic variable.
atomic_thread_fence(memory_order_acquire); // acquire fence
atomic_thread_fence(memory_order_release); // release fence
atomic_thread_fence(memory_order_acq_rel); // full fence
atomic_thread_fence(memory_order_seq_cst); // seq_cst fence
Fence-Fence Synchronization
A release fence in thread 1 synchronizes with an acquire fence in thread 2 if there is an atomic store (any ordering) after the release fence that is read by an atomic load (any ordering) before the acquire fence.
// Thread 1
data = 42;
atomic_thread_fence(memory_order_release);
flag.store(1, memory_order_relaxed);
// Thread 2
while (flag.load(memory_order_relaxed) != 1) {}
atomic_thread_fence(memory_order_acquire);
assert(data == 42); // guaranteed
Rust Memory Model
Rust follows the C++20 memory model for its std::sync::atomic types with identical orderings (Relaxed, Acquire, Release, AcqRel, SeqCst).
Key Differences from C/C++
- No data races possible in safe code: the ownership and borrowing system prevents shared mutable access at compile time
- Data races in
unsafecode are still undefined behavior Ordering::SeqCstis the recommended default unless performance profiling justifies weaker orderings- Rust does not expose
memory_order_consume(it was effectively deprecated in C++ too)
Rust Atomic API
flag ← ATOMIC_BOOL(FALSE)
ATOMIC_STORE(flag, TRUE, ordering ← Release)
val ← ATOMIC_LOAD(flag, ordering ← Acquire)
old ← COMPARE_AND_EXCHANGE(flag,
expected ← FALSE, new ← TRUE,
success_ordering ← AcqRel, // success ordering
failure_ordering ← Relaxed) // failure ordering
Common Patterns and Their Ordering Requirements
| Pattern | Store | Load |
|---|---|---|
| Spin lock | Release (unlock) | Acquire (lock) |
| Flag/notification | Release | Acquire |
| Reference counting (decrement) | AcqRel | N/A |
| Statistics counter | Relaxed | Relaxed |
| Dekker/Peterson mutex | SeqCst | SeqCst |
Compiler Barriers
Prevent compiler reordering without emitting hardware fence instructions.
asm volatile("" ::: "memory"); // GCC/Clang compiler barrier
_ReadWriteBarrier(); // MSVC
atomic_signal_fence(memory_order_seq_cst); // C11 standard
A compiler barrier is necessary when communicating with signal handlers in the same thread (no hardware barrier needed since same CPU).