Design an E-Commerce Platform
This case study walks through the design of a large-scale e-commerce platform similar to Amazon or Shopify. The system supports millions of products across many sellers, handles spiky traffic during flash sales, and ensures reliable checkout & payment processing.
Functional Requirements
- Product catalog: sellers create, update, and manage product listings with images, descriptions, pricing, and categories
- Search & browse: buyers find products via keyword search, category navigation, and filters (price, rating, brand)
- Shopping cart: users add, remove, and update items; carts persist across sessions
- Checkout flow: address selection, shipping method, coupon/discount application, order summary, payment
- Inventory management: real-time stock tracking, reservations during checkout, low-stock alerts
- Order processing: order creation, status tracking, cancellation, returns & refunds
- Payment integration: support for credit cards, digital wallets, and buy-now-pay-later via third-party gateways
- Recommendations: personalized product suggestions based on browsing history, purchase history, and collaborative filtering
- Multi-seller support: seller onboarding, per-seller storefronts, commission tracking, payouts
- Reviews & ratings: buyers leave reviews; aggregate ratings displayed on product pages
Non-Functional Requirements
- Availability: 99.99% uptime target; checkout & payment paths are the most critical
- Latency: product page loads under 200 ms (p95); search results under 300 ms
- Consistency: inventory counts must be strongly consistent to prevent overselling
- Scalability: handle 100 M+ daily active users, 10x traffic spikes during events (Black Friday, Prime Day)
- Durability: zero tolerance for lost orders or payment records
- Security: PCI-DSS compliance for payment data; encryption at rest & in transit
Estimation
Traffic
- 100 M daily active users
- Each user views ~20 pages per session -> 2 B page views/day -> ~23 K requests/second average
- Peak during flash sales: ~230 K requests/second (10x)
- 5% of sessions result in a purchase -> 5 M orders/day -> ~58 orders/second average
Storage
- 500 M products in the catalog; each product record ~10 KB -> 5 TB for product metadata
- Product images: average 5 images per product at 500 KB each -> 1.25 PB raw (served via CDN)
- Orders: 5 M/day * 5 KB avg -> 25 GB/day -> ~9 TB/year
- User data (profiles, carts, wishlists): 500 M users * 5 KB -> 2.5 TB
Bandwidth
- Average page size 2 MB (mostly images from CDN)
- 2 B page views * 2 MB -> 4 PB/day outbound (CDN absorbs 95%+)
- Origin bandwidth: ~200 TB/day
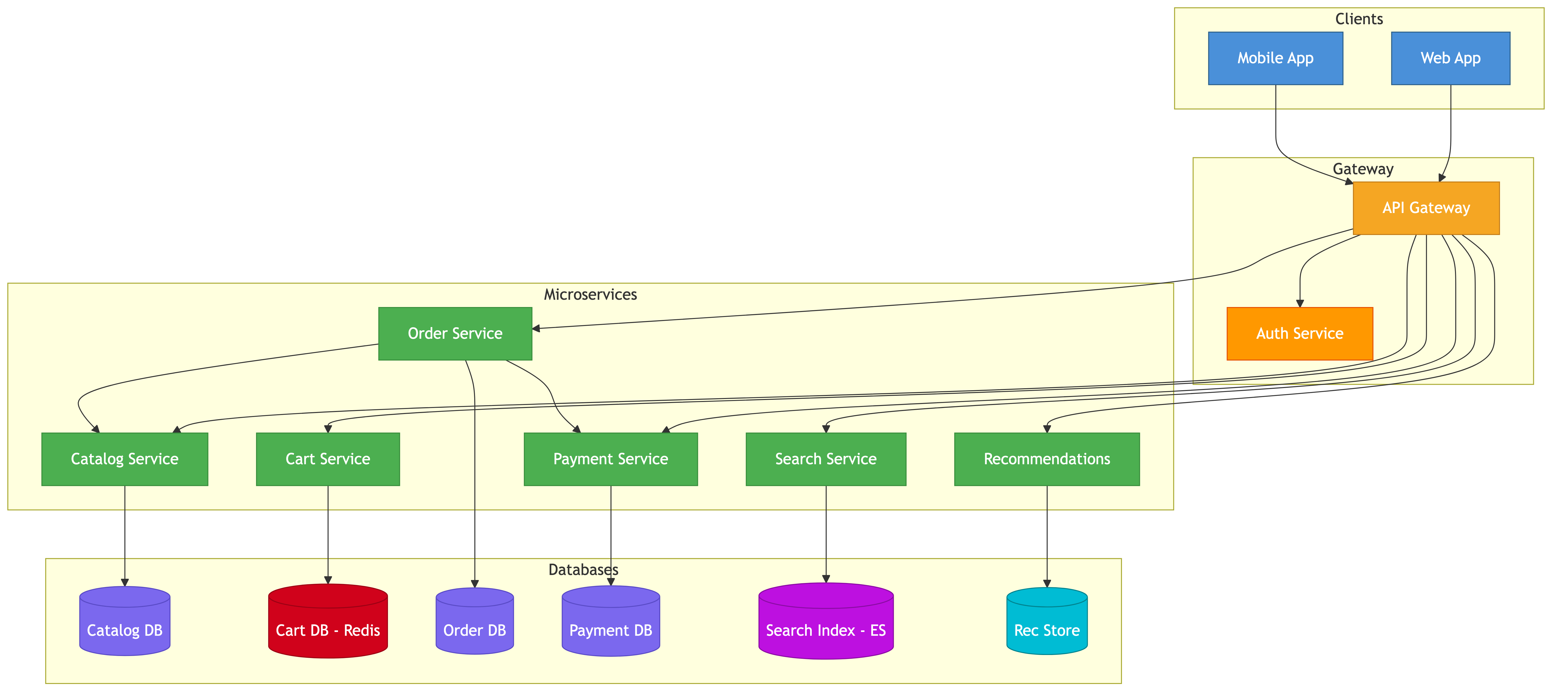
High-Level Design
The platform is split into independently deployable services behind an API gateway.
Core Services
- Product Service — CRUD for product listings, catalog browsing, category management
- Search Service — full-text search over the product catalog with filters & facets
- Cart Service — shopping cart state management
- Order Service — order lifecycle from creation through fulfillment
- Inventory Service — stock levels, reservations, replenishment triggers
- Payment Service — integrates with external payment gateways
- User Service — authentication, profiles, addresses
- Recommendation Service — ML-based product suggestions
- Seller Service — seller onboarding, storefront config, commission & payout tracking
- Notification Service — order confirmations, shipping updates, promotional emails
Data Flow — Happy Path Purchase
Client -> CDN (static assets, product images)
Client -> API Gateway -> Product Service (browse/search)
Client -> API Gateway -> Cart Service (add to cart)
Client -> API Gateway -> Order Service (place order)
Order Service -> Inventory Service (reserve stock)
Order Service -> Payment Service -> External Gateway (charge)
Order Service -> Notification Service (confirmation email)
Order Service -> Seller Service (notify seller to ship)
Data Stores
- Product DB — PostgreSQL with read replicas; holds product metadata, categories, seller info
- Search Index — Elasticsearch cluster; synced from Product DB via change data capture
- Cart Store — Redis cluster; fast reads/writes, TTL-based expiry for abandoned carts
- Order DB — PostgreSQL with strong consistency; partitioned by order date
- Inventory DB — PostgreSQL; requires serializable isolation for stock reservation
- User DB — PostgreSQL with read replicas
- Object Storage — S3 for product images, invoices, and other blobs
- Analytics Warehouse — ClickHouse or BigQuery for recommendation model training & business intelligence
Detailed Design
Product Catalog & Search
The Product Service owns the source of truth for all product data. When a seller creates or updates a listing, the change is written to PostgreSQL and an event is published to a Kafka topic.
The Search Service consumes these events and updates an Elasticsearch index. The index is optimized for full-text queries with filters on price, category, brand, rating, and seller.
Seller writes product -> Product DB (PostgreSQL)
-> Kafka (product.updated event)
-> Search Indexer -> Elasticsearch
Search queries flow through the API gateway to the Search Service, which fans out to Elasticsearch shards. Results are enriched with pricing and stock data before returning to the client.
Faceted navigation (e.g., "Laptops > Brand: Dell > Price: 1000") is handled by Elasticsearch aggregations. Category trees are stored in PostgreSQL using a materialized path or nested set model.
Shopping Cart
Carts are stored in Redis for speed. Each cart is a hash keyed by user ID, with fields for each product (SKU, quantity, price snapshot).
For guest users, a session-based cart ID is stored in a cookie. When the guest signs in, the Cart Service merges the session cart with any existing user cart.
Cart data has a TTL of 30 days. If the user returns after expiry, the cart is empty. Price snapshots in the cart may become stale, so the checkout flow re-validates prices & availability at the moment of purchase.
Inventory Management & Reservation
Inventory is the most consistency-critical component. The Inventory Service uses PostgreSQL with serializable transactions to prevent overselling.
When a user begins checkout, the Order Service calls the Inventory Service to create a soft reservation:
BEGIN SERIALIZABLE;
SELECT quantity FROM inventory WHERE sku = ? FOR UPDATE;
-- check quantity >= requested
UPDATE inventory SET quantity = quantity - ?, reserved = reserved + ? WHERE sku = ?;
COMMIT;
Soft reservations have a TTL (e.g., 10 minutes). If the user does not complete payment, a background job releases the reservation and restores available stock.
For flash sales with extreme contention on a single SKU, the system uses a token bucket approach: pre-allocate purchase tokens in Redis and let the Inventory DB reconcile asynchronously. This trades strict real-time accuracy for throughput.
Checkout & Payment Flow
Checkout is a multi-step process with compensation (saga pattern) for failures at any stage.
1. Validate cart (prices, availability)
2. Reserve inventory
3. Calculate totals (subtotal, tax, shipping, discounts)
4. Create order record (status: PENDING_PAYMENT)
5. Initiate payment via Payment Service
-> Payment Service calls Stripe/Adyen/PayPal
6a. Payment SUCCESS -> update order to CONFIRMED, notify seller
6b. Payment FAILURE -> release inventory reservation, update order to FAILED
The Order Service acts as the saga orchestrator. Each step is idempotent so that retries are safe. The Payment Service stores a unique idempotency key per order to prevent double charges.
For PCI-DSS compliance, the platform never stores raw card numbers. The client-side checkout form sends card data directly to the payment gateway (e.g., Stripe Elements), which returns a token. Only the token is sent to the backend.
Order Processing & Fulfillment
After payment confirmation, the order moves through a state machine:
PENDING_PAYMENT -> CONFIRMED -> PROCESSING -> SHIPPED -> DELIVERED
-> CANCELLED (from CONFIRMED or PROCESSING)
-> RETURN_REQUESTED -> REFUNDED (from DELIVERED)
State transitions publish events to Kafka. Downstream consumers handle:
- Seller notification (ship the order)
- Warehouse management system integration (for platform-fulfilled orders)
- Notification Service (email/SMS updates to buyer)
- Analytics pipeline (revenue tracking)
Recommendations
The Recommendation Service combines multiple signals:
- Collaborative filtering — users who bought X also bought Y (computed offline in batch)
- Content-based filtering — similar product attributes (category, brand, price range)
- Real-time personalization — recent browsing and cart activity stored in Redis, used to re-rank candidates
A nightly batch job trains the collaborative filtering model on the analytics warehouse. Results are pre-computed and stored in a key-value store (DynamoDB or Redis) keyed by user ID and product ID.
Real-time features (recently viewed, trending in category) are computed using a streaming pipeline on Kafka + Flink.
Multi-Seller Support
Each product belongs to a seller. The Seller Service manages:
- Seller profiles & verification
- Per-seller commission rates
- Payout scheduling (aggregate orders, subtract commission, transfer funds)
When an order contains items from multiple sellers, the Order Service splits it into sub-orders, one per seller. Each sub-order has its own fulfillment lifecycle. The buyer sees a unified order view; sellers see only their sub-order.
Payouts run as a scheduled batch job (e.g., bi-weekly). The Payment Service transfers funds to seller bank accounts via ACH or equivalent.
Search Relevance & Autocomplete
Search ranking combines:
- Text relevance (BM25 score from Elasticsearch)
- Popularity (sales velocity, click-through rate)
- Seller quality (rating, fulfillment speed)
- Sponsored boost (paid placement by sellers)
Autocomplete uses a prefix-based index in Elasticsearch with a completion suggester. Popular queries are cached in Redis with short TTLs.
Spell correction uses an n-gram based approach: the search index includes n-gram sub-fields, and fuzzy matching catches common typos.
Trade-Offs & Alternatives
SQL vs NoSQL for Product Catalog
PostgreSQL was chosen for its strong consistency, relational modeling (products-categories-sellers), and mature tooling. A document store like MongoDB could simplify the schema for products with highly variable attributes, but joins across sellers, categories, and inventory become harder.
An alternative is a hybrid: PostgreSQL for structured data (pricing, inventory, seller info) and a document store for flexible product attributes (specifications vary by category).
Synchronous vs Asynchronous Checkout
The design uses synchronous payment calls during checkout for immediate user feedback. An alternative is fully asynchronous: accept the order, return a "processing" status, and confirm later. This improves throughput but degrades user experience — buyers want instant confirmation.
The hybrid chosen here is synchronous for the payment call (typically < 2 seconds) with asynchronous post-payment processing (notifications, fulfillment triggers).
Event Sourcing for Orders
The order state machine could be implemented with event sourcing: store every state change as an immutable event and derive the current state by replaying events. This provides a perfect audit trail and enables temporal queries ("what was the order status at 3 PM?").
The trade-off is increased complexity. For most e-commerce platforms, a status column with a separate audit log table achieves 90% of the benefit with far less complexity.
Cart in Redis vs Database
Redis provides sub-millisecond cart access but risks data loss if a node fails before replication. For most carts this is acceptable — losing a cart is annoying but not catastrophic. For high-value B2B carts, persisting to PostgreSQL with a Redis cache in front is safer.
Bottlenecks & Scaling
Hot Product Problem
A viral product or flash sale creates extreme read & write contention on a single SKU. Mitigations:
- Cache product detail pages aggressively at the CDN edge
- Use Redis for inventory pre-allocation (token bucket) to avoid DB contention
- Rate-limit add-to-cart requests per user to prevent bot-driven spikes
- Queue checkout requests and process in order (virtual waiting room)
Database Scaling
- Product DB: read replicas handle browse traffic; write traffic is moderate (seller updates)
- Order DB: partition by order creation date; older partitions move to cold storage
- Inventory DB: shard by SKU range; each shard handles a subset of products
- Cross-shard transactions (multi-seller orders) use the saga pattern rather than distributed transactions
Search Index Scaling
Elasticsearch scales horizontally by adding data nodes and shards. For 500 M products:
- 50 shards across 25 nodes (2 shards per node)
- Each shard holds ~10 M products
- Replica shards on different nodes for fault tolerance
- Index aliasing enables zero-downtime re-indexing when the mapping changes
Payment Gateway Reliability
External payment gateways are a single point of failure. Mitigations:
- Support multiple gateways (Stripe as primary, Adyen as fallback)
- Circuit breaker pattern: if Stripe error rate exceeds threshold, route to Adyen
- Idempotency keys on every payment request to handle retries safely
- Store payment intent locally before calling the gateway so no charge is ever lost
CDN & Static Asset Scaling
Product images are the largest bandwidth consumer. Serve them through a multi-tier CDN:
- Edge nodes close to users (CloudFront, Fastly)
- Origin shield layer to reduce load on object storage
- Image transformation service (resize, WebP conversion) at the edge or origin
- Cache-Control headers with long max-age and versioned URLs for cache busting
Session & Authentication Scaling
With 100 M daily active users, session management becomes a scaling concern:
- Use stateless JWT tokens for authentication to avoid server-side session storage
- Short-lived access tokens (15 minutes) with longer-lived refresh tokens stored in Redis
- Rate-limit login attempts per IP and per account to prevent credential stuffing
- During flash sales, pre-authenticate users and issue session tokens before the event starts to reduce auth service load at peak
Monitoring & Alerting
An e-commerce platform requires granular monitoring across every service:
- Business metrics: orders per minute, cart abandonment rate, revenue per second (any sudden drop signals a system problem)
- Inventory alerts: alert when stock reservation failures spike, indicating contention or bugs
- Payment success rate: track per-gateway success rates; a drop below threshold triggers automatic failover
- Search latency: monitor p50, p95, p99; degraded search directly reduces conversion rates
- Consumer lag: track Kafka consumer lag for the search indexer and notification pipeline; stale data causes poor user experience
Common Pitfalls
- Overselling: relying on application-level checks without database-level serialization leads to race conditions; always use
SELECT ... FOR UPDATEor equivalent - Cart-price drift: prices change between when the user adds to cart and when they check out; always re-validate at checkout
- Distributed transactions: trying to atomically update inventory + create order + charge payment in a single transaction across services does not scale; use sagas with compensation
- Search index lag: if the search index falls behind the source database, users see stale results (out-of-stock items appearing available); monitor consumer lag and alert early
- Ignoring idempotency: payment retries without idempotency keys cause double charges; every external call that has side effects needs an idempotency mechanism
- Monolithic product schema: forcing all product types into a single rigid schema leads to sparse columns and awkward queries; use a flexible attribute model
- Neglecting seller experience: focusing only on buyer flows while seller tools (inventory upload, order management, analytics) remain clunky drives sellers to competing platforms
Key Takeaways
- Inventory reservation with strong consistency is the most critical correctness requirement; overselling erodes trust faster than anything else
- The saga pattern with compensation is the practical approach to distributed transactions across services like inventory, payment, and order management
- Redis is an excellent fit for shopping carts and session data where sub-millisecond latency matters and occasional data loss is tolerable
- Search and browse are read-heavy paths that benefit from aggressive caching (CDN, Redis, Elasticsearch replicas) while checkout is write-heavy and demands consistency
- Multi-seller support fundamentally changes order processing: every order may need to be split into sub-orders with independent fulfillment lifecycles
- Payment processing requires PCI-DSS compliance (tokenization, never storing raw card data) and idempotency on every gateway call
- Flash sales and viral products create hot-key problems that require specific mitigations (token buckets, virtual waiting rooms, CDN edge caching)