Design a Distributed Job Scheduler
Overview
A distributed job scheduler accepts, queues, and executes tasks across a fleet of workers. Systems like Celery, Temporal, and Airflow power background processing for millions of applications. The core challenge is guaranteeing reliable execution at scale while supporting priorities, retries, cron schedules, and complex job dependencies.
Functional Requirements
Core capabilities:
- Submit jobs with payload, priority, and optional schedule
- Execute jobs on distributed worker pools
- Support one-time, delayed, and recurring (cron) jobs
- Retry failed jobs with configurable backoff
- Route dead/poison jobs to a dead letter queue
- Track job status (pending, running, succeeded, failed, dead)
- Define job dependencies as directed acyclic graphs (DAGs)
- Cancel or pause individual jobs and entire DAGs
API surface:
POST /jobs -> Submit a new job
GET /jobs/{id} -> Get job status and result
DELETE /jobs/{id} -> Cancel a job
POST /jobs/{id}/retry -> Manually retry a failed job
POST /schedules -> Create a recurring schedule
GET /schedules/{id}/runs -> List past runs for a schedule
POST /dags -> Submit a DAG of dependent jobs
GET /dags/{id}/status -> Get DAG execution status
Non-Functional Requirements
Reliability:
- Exactly-once execution semantics (at-least-once delivery + idempotency)
- No job lost even during node crashes or network partitions
- Graceful worker draining on deployment
Performance:
- Job pickup latency under 100ms for high-priority jobs
- Support 100,000+ queued jobs
- Handle 10,000 job submissions per second
Scalability:
- Horizontally scale workers independently per queue
- Support multiple job types with isolated resource pools
Observability:
- Per-job execution logs and duration metrics
- Alerting on queue depth, failure rate, and stuck jobs
Estimation
Traffic:
- 10,000 job submissions/sec peak
- Average job duration: 5 seconds
- Workers needed at peak: 10,000 * 5 = 50,000 concurrent slots
- With overprovisioning: ~2,000 worker machines (25 slots each)
Storage:
- Job record: ~2 KB (metadata, payload reference, status, timestamps)
- 10,000/sec * 86,400 sec/day = 864 million jobs/day
- 864M * 2 KB = ~1.7 TB/day raw job metadata
- Retain 30 days of history: ~50 TB
- Store large payloads in object storage, only reference in job record
Bandwidth:
- Inbound: 10,000/sec * 2 KB = 20 MB/sec for submissions
- Worker polling/push: 10,000/sec * 1 KB = 10 MB/sec for dispatch
- Status updates: 10,000/sec * 0.5 KB = 5 MB/sec
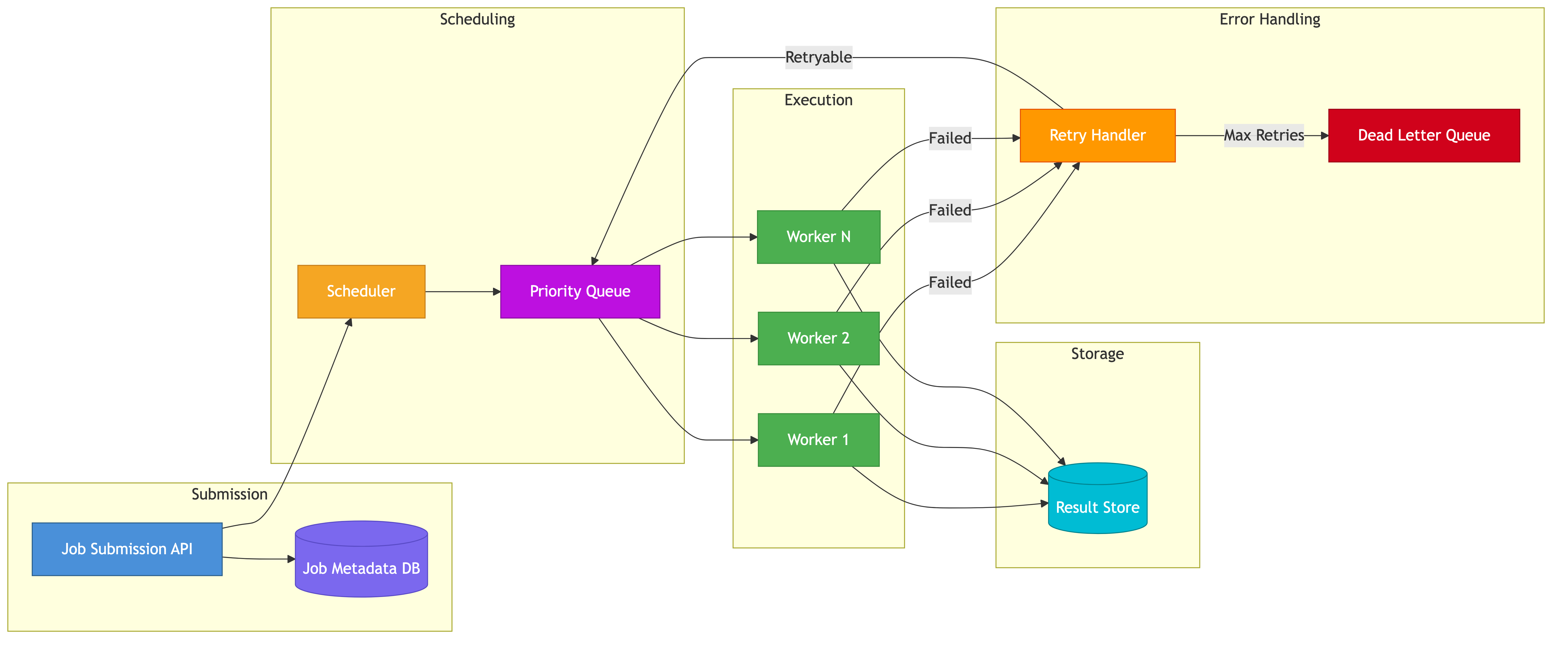
High-Level Design
Clients (SDKs, HTTP, CLI)
|
v
API Gateway
|
v
Job Service <------> Metadata Store (PostgreSQL / Vitess)
|
|--- writes job to queue ---> Priority Queue (Redis Sorted Sets)
|
v
Scheduler Service
|--- cron tick evaluation
|--- DAG dependency resolution
|
v
Dispatcher
|--- assigns jobs to workers
|--- tracks heartbeats
|
v
Worker Fleet (per-queue pools)
|
|--- success/failure ---> Result Store
|--- dead jobs ---------> Dead Letter Queue
|
v
Notification Service (webhooks, callbacks)
Component Responsibilities
Job Service:
- Validates and persists job definitions
- Assigns job IDs (ULIDs for time-ordered uniqueness)
- Enqueues jobs into the correct priority queue
- Exposes status and result queries
Scheduler Service:
- Evaluates cron expressions every second
- Creates job instances for matching schedules
- Resolves DAG dependencies before releasing child jobs
Dispatcher:
- Matches queued jobs to available workers
- Implements fair scheduling across tenants
- Detects stuck workers via heartbeat timeouts
Worker Fleet:
- Pulls or receives jobs from assigned queues
- Executes job logic in isolated processes/containers
- Reports progress, completion, or failure back to dispatcher
Detailed Design
Job Queuing & Priority Scheduling
Queue structure using Redis Sorted Sets:
ZADD queue:email score=priority*1e12+timestamp job_id
ZPOPMIN queue:email -> returns highest priority, oldest job
Priority levels:
CRITICAL = 0 (lowest score = popped first)
HIGH = 1
NORMAL = 2
LOW = 3
Score formula:
score = (priority * 1_000_000_000_000) + unix_timestamp_micros
This ensures strict priority ordering with FIFO within same priority.
Multi-queue isolation:
Separate sorted sets per job type: queue:email, queue:export, queue:ml
Workers subscribe to specific queues with configurable concurrency.
Prevents slow ML jobs from blocking fast email jobs.
LinkedIn uses priority queues in their job processing platform to ensure
time-sensitive notifications are processed before batch analytics jobs.
Cron Scheduling
Cron expression: "0 */6 * * *" -> every 6 hours
Cron evaluator runs on the Scheduler Service:
1. Every second, check all active schedules
2. For each schedule, compute next_fire_time
3. If current_time >= next_fire_time, create a job instance
4. Update next_fire_time in the schedule record
5. Use distributed lock to prevent duplicate cron firings
Optimization for large schedule sets:
- Store schedules in a sorted set by next_fire_time
- Only evaluate schedules where next_fire_time <= now
- Partition schedules across scheduler instances by hash
Schedule record:
schedule_id: ulid
cron_expr: "0 */6 * * *"
job_template: { type: "report", payload: {...} }
next_fire_time: 1711929600
enabled: true
last_run_id: job_12345
Airflow uses a similar scheduler loop. Their bottleneck was single-threaded
evaluation, which they fixed by sharding the schedule space in Airflow 2.0.
Retry with Exponential Backoff
Retry policy (per job type):
max_retries: 5
initial_delay: 1 second
backoff_factor: 2
max_delay: 300 seconds (5 minutes)
jitter: random 0-30% of delay
Retry sequence:
Attempt 1: immediate
Attempt 2: 1s + jitter -> ~1.2s
Attempt 3: 2s + jitter -> ~2.4s
Attempt 4: 4s + jitter -> ~4.8s
Attempt 5: 8s + jitter -> ~9.6s
Attempt 6: DEAD (moved to dead letter queue)
Implementation:
On failure, compute next_retry_time and re-enqueue with that timestamp.
Use a Redis sorted set as a delay queue:
ZADD delayed_jobs next_retry_time job_id
A sweeper process moves jobs from delayed_jobs to active queues
when current_time >= their score.
Stripe processes billions of payment webhooks and uses exponential
backoff with jitter to avoid thundering herd on merchant endpoints.
Dead Letter Handling
A job enters the dead letter queue (DLQ) when:
- All retry attempts are exhausted
- The job payload is malformed (non-retryable error)
- The job exceeds maximum execution time after retries
- A worker explicitly marks it as poison
DLQ record:
original_job_id: job_67890
job_type: "payment_webhook"
failure_reason: "ConnectionTimeout after 5 retries"
failed_at: 2026-04-03T10:23:00Z
original_payload: { ... }
attempt_history: [ { attempt: 1, error: "...", at: "..." }, ... ]
DLQ operations:
- Browse and inspect dead jobs via admin UI
- Replay individual jobs or bulk replay by type/time range
- Purge jobs older than retention period
- Alert when DLQ depth exceeds threshold
AWS SQS dead letter queues follow this pattern. Teams at Amazon set up
CloudWatch alarms on DLQ depth to catch upstream service degradation early.
Worker Management
Worker lifecycle:
1. Worker starts, registers with dispatcher (type, capacity, queues)
2. Worker sends heartbeat every 5 seconds
3. Dispatcher assigns jobs via push or worker pulls from queue
4. Worker executes job, reports result
5. On shutdown signal, worker drains: finishes current jobs, stops pulling
Heartbeat and failure detection:
- Dispatcher expects heartbeat every 5 seconds
- After 15 seconds without heartbeat: mark worker suspect
- After 30 seconds: mark worker dead, re-enqueue its in-flight jobs
- In-flight jobs get a visibility timeout (like SQS): if not acked
within timeout, they become available for other workers
Worker scaling:
- Monitor queue depth per job type
- Auto-scale worker pools: if queue_depth > threshold for 2 minutes, add workers
- Scale down when queue is empty for 5 minutes (with cooldown)
- Use Kubernetes HPA or cloud auto-scaling groups
Uber uses a similar heartbeat mechanism in their Cherami messaging system
to detect failed consumers and reassign unprocessed messages.
Exactly-Once Execution
True exactly-once is impossible in distributed systems.
Instead: at-least-once delivery + idempotent execution = effectively once.
At-least-once delivery:
- Jobs persist in durable storage before acknowledgment
- Unacked jobs are re-delivered after visibility timeout
- Crashed workers' jobs are reassigned
Idempotency layer:
Before executing, worker checks an idempotency key:
Key = hash(job_id + attempt_number)
Stored in: Redis with TTL or a dedicated idempotency table
Execution flow:
1. Worker receives job_id=abc, attempt=3
2. Check: EXISTS idempotency:abc:3 -> if yes, skip execution
3. Execute job logic
4. SET idempotency:abc:3 = result, TTL 24h
5. Ack job completion
For jobs that produce side effects (send email, charge card):
Use an idempotency key from the business domain.
Example: payment_id + action = "pay_123_charge"
The payment processor checks this key before processing.
Temporal workflow engine implements this via event sourcing. Each workflow
step is recorded, and replays skip already-completed steps deterministically.
Job Dependencies & DAGs
DAG definition:
{
"dag_id": "daily_report",
"jobs": {
"extract": { "type": "etl_extract", "depends_on": [] },
"transform": { "type": "etl_transform", "depends_on": ["extract"] },
"load_warehouse": { "type": "etl_load", "depends_on": ["transform"] },
"load_cache": { "type": "cache_warm", "depends_on": ["transform"] },
"notify": { "type": "slack_notify", "depends_on": ["load_warehouse", "load_cache"] }
}
}
DAG execution engine:
1. Parse DAG, validate no cycles (topological sort)
2. Create job records for all nodes with state=BLOCKED
3. Release root nodes (no dependencies) to the queue -> state=PENDING
4. When a job completes:
a. Update its state to SUCCEEDED
b. For each downstream job, check if ALL parents succeeded
c. If yes, release that job to the queue
5. If any job fails and exhausts retries:
a. Mark it FAILED
b. Mark all downstream jobs CANCELLED (or allow partial execution)
Dependency tracking table:
dag_run_id | job_name | status | depends_on_complete
run_001 | extract | SUCCEEDED | 0/0
run_001 | transform | RUNNING | 1/1
run_001 | load_warehouse | BLOCKED | 0/1
run_001 | load_cache | BLOCKED | 0/1
run_001 | notify | BLOCKED | 0/2
Apache Airflow is the most widely used DAG scheduler. Spotify runs
thousands of Airflow DAGs daily for their data pipeline orchestration.
Data Model
Jobs table (PostgreSQL, partitioned by created_at):
job_id ULID PRIMARY KEY
type VARCHAR(64)
queue VARCHAR(64)
priority SMALLINT
status ENUM(pending, running, succeeded, failed, dead, cancelled)
payload_ref TEXT -- S3 URI for large payloads
payload_inline JSONB -- small payloads stored inline
attempt SMALLINT
max_retries SMALLINT
scheduled_at TIMESTAMP
started_at TIMESTAMP
completed_at TIMESTAMP
worker_id VARCHAR(128)
result_ref TEXT
idempotency_key VARCHAR(256)
dag_run_id ULID -- NULL if standalone job
created_at TIMESTAMP
Indexes:
(queue, status, priority, scheduled_at) -- for job dispatch
(dag_run_id, status) -- for DAG progress queries
(idempotency_key) -- for dedup checks
(scheduled_at) WHERE status='pending' -- for delayed job sweeper
Trade-Offs & Alternatives
Push vs Pull dispatch:
Push: Dispatcher assigns jobs to workers
+ Lower latency, better load balancing
- Dispatcher becomes a bottleneck, must track worker state
Pull: Workers pull from queue
+ Simpler, workers are self-regulating
- Slight latency overhead, risk of thundering herd on queue
Recommendation: Pull for most workloads. Push for latency-critical jobs.
Redis vs Kafka for job queue:
Redis Sorted Sets:
+ Sub-millisecond latency, built-in priority support
- Memory-bound, data loss risk without persistence
Kafka:
+ Durable, high throughput, natural replay capability
- No native priority support, partition-based ordering only
Recommendation: Redis for interactive workloads. Kafka for high-volume
batch pipelines where priority is less important.
Relational DB vs dedicated queue:
PostgreSQL with SELECT FOR UPDATE SKIP LOCKED:
+ Single source of truth, transactional guarantees
- Polling overhead, row-level locks under contention
Dedicated queue (Redis/SQS):
+ Purpose-built, lower latency
- Separate system to operate, eventual consistency with DB
Recommendation: Start with PostgreSQL queue for simplicity. Move to
Redis/SQS when throughput exceeds 1,000 jobs/sec.
Temporal vs custom scheduler:
Temporal/Cadence:
+ Battle-tested, built-in retries, timers, saga patterns
- Operational complexity, learning curve
Custom:
+ Tailored to your workload, fewer dependencies
- You own all the edge cases (and there are many)
Recommendation: Use Temporal for complex workflows with long-running
state. Build custom for simple fire-and-forget job queues.
Bottlenecks & Scaling
Bottleneck: Single queue becomes hot spot
Solution: Shard queues by job type or tenant.
Partition key = job_type or hash(tenant_id) % num_shards.
Each shard is an independent Redis sorted set.
Bottleneck: Metadata store write throughput
Solution: Batch status updates. Workers buffer completions and
flush every 100ms or every 50 jobs, whichever comes first.
Use PostgreSQL COPY or multi-row INSERT for bulk writes.
Bottleneck: Cron evaluator with millions of schedules
Solution: Partition schedules across N evaluator instances.
Each instance owns schedules where hash(schedule_id) % N = instance_id.
Use leader election to rebalance on instance failure.
Bottleneck: DAG dependency checks on every job completion
Solution: Maintain an in-memory dependency counter per DAG run.
Decrement on each parent completion. Release child when counter hits 0.
Persist counter to Redis for crash recovery.
Bottleneck: Large payload serialization
Solution: Store payloads in S3/GCS. Pass only a reference URI in the
job record. Workers fetch payload on execution. This keeps the queue
and database lean.
Scaling path:
Phase 1 (< 100 jobs/sec):
Single PostgreSQL as queue + metadata store
Workers pull with SELECT FOR UPDATE SKIP LOCKED
Phase 2 (100-10,000 jobs/sec):
Redis sorted sets for queuing, PostgreSQL for metadata
Multiple worker pools per job type
Phase 3 (10,000+ jobs/sec):
Sharded Redis, partitioned PostgreSQL (by time)
Dedicated scheduler instances per queue shard
Kafka for audit log and replay capability
Common Pitfalls
1. Ignoring job idempotency
Jobs will be delivered more than once during failures. If your job
sends an email or charges a card without idempotency checks, users
get duplicate side effects. Always design jobs to be safely re-run.
2. Unbounded retry loops
A poison job that always fails will consume worker capacity forever.
Always set max_retries and route exhausted jobs to a dead letter queue.
3. No visibility timeout on in-flight jobs
If a worker crashes mid-execution and the job is not re-queued, it is
lost. Set a visibility timeout so unacknowledged jobs return to the queue.
4. Polling the database as a queue at scale
SELECT FOR UPDATE works at low throughput but causes lock contention
at scale. Migrate to a dedicated queue system before this becomes
a production incident.
5. Tight coupling between scheduler and workers
If workers import the scheduler's internal modules, you cannot scale
them independently. Communicate only through the queue and well-defined
job payload contracts.
6. No graceful shutdown
Killing workers abruptly causes jobs to be re-queued and re-executed.
Implement SIGTERM handling: stop pulling new jobs, finish current ones,
then exit.
7. DAG cycles going undetected
If you accept DAG definitions without validation, a cycle causes jobs
to wait forever. Always run topological sort on submission and reject
cyclic graphs.
Key Takeaways
1. Exactly-once execution requires at-least-once delivery combined
with idempotent job handlers. There is no shortcut.
2. Priority queues with Redis Sorted Sets provide sub-millisecond
dispatch with strict ordering. Use the score = priority + timestamp
formula for FIFO within priority levels.
3. Exponential backoff with jitter prevents retry storms. Always cap
the maximum delay and set a retry limit.
4. Dead letter queues are essential operational infrastructure. Without
them, poison jobs silently consume resources or disappear.
5. DAG execution is a state machine: validate the graph on submission,
track dependency counters, and release children only when all parents
succeed.
6. Start with PostgreSQL as both queue and metadata store. Migrate to
dedicated queue infrastructure when you hit measurable contention.
7. Worker heartbeats and visibility timeouts are the two mechanisms that
prevent job loss during failures. Both are required.