Design a Distributed Rate Limiter
A rate limiter controls how many requests a client can make within a time window. At scale, the limiter must work across multiple servers, data centers, and API endpoints while adding minimal latency. Services like Cloudflare, Stripe, and GitHub rate-limit billions of requests daily to protect infrastructure and ensure fair usage. This design covers algorithms, distributed counting, rule engines, and multi-tier limiting.
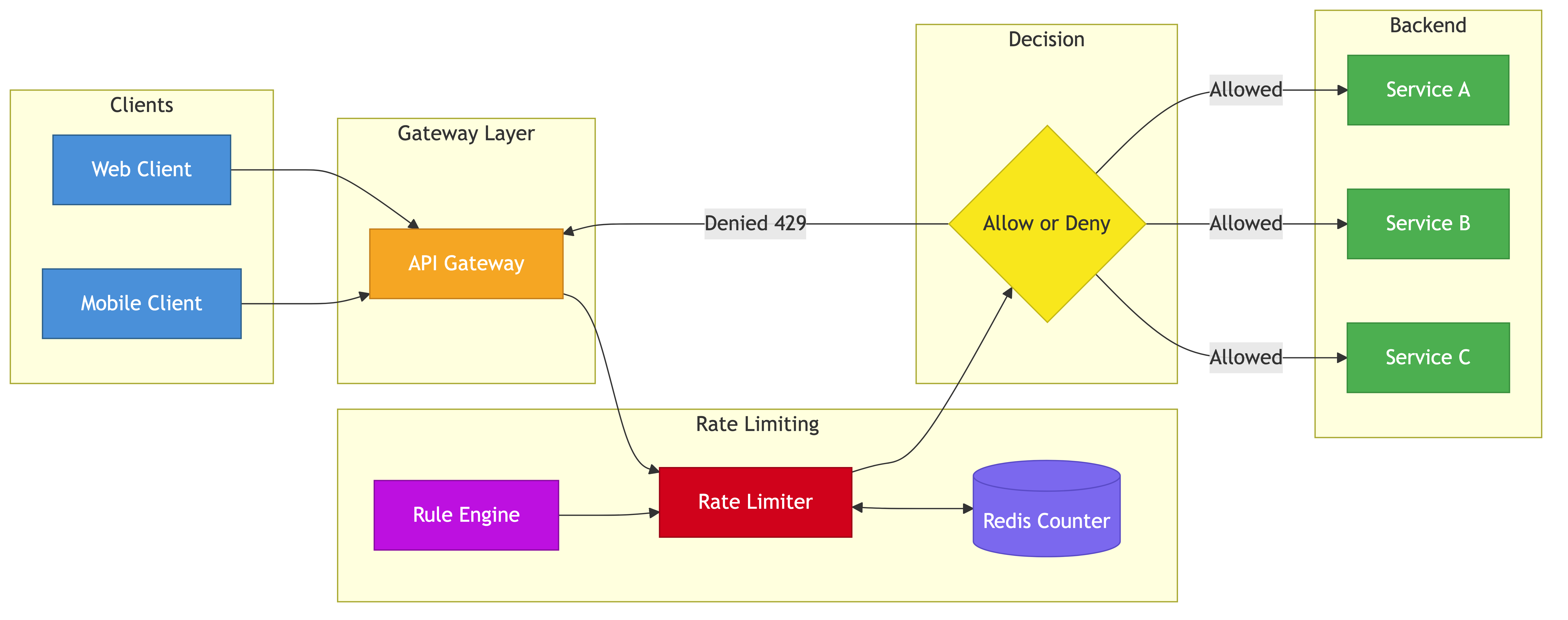
Functional Requirements
- Limit requests per user, per API key, per IP, or per custom identifier
- Support multiple rate limiting algorithms (fixed window, sliding window, token bucket, leaky bucket)
- Allow multi-tier limits (per endpoint, per user, per organization, global)
- Provide a rule engine for configurable policies (different limits for different plans)
- Return standard rate limit headers (X-RateLimit-Limit, X-RateLimit-Remaining, X-RateLimit-Reset)
- Support both hard limits (reject) and soft limits (log only / degrade)
Non-Functional Requirements
- Sub-millisecond overhead per request (p99 under 2ms)
- 99.99% availability (the limiter must not become a single point of failure)
- Consistent behavior across distributed nodes
- Handle 1 million rate limit checks per second
- Graceful degradation: if the rate limiter is unavailable, default to allowing traffic (fail open)
Estimation
Traffic
1 million rate limit checks/second
Each check: 1 Redis round trip (~0.5ms local, ~5ms cross-region)
At 1M checks/sec with 0.5ms each: ~500 concurrent Redis connections needed
Storage
Active rate limit keys: ~50 million (unique user+endpoint combinations)
Per key storage: ~100 bytes (counter, timestamp, metadata)
Total active state: 50M * 100B = 5 GB
Fits comfortably in Redis memory on a single large instance
With sharding across 4 Redis nodes: ~1.25 GB per shard
Bandwidth
Per check: ~200 bytes request + ~100 bytes response to Redis
At 1M checks/sec: ~300 MB/sec Redis network traffic
Manageable for modern networks
High-Level Design
The rate limiter sits in the request path, either as middleware in the API gateway or as a sidecar. It checks a distributed counter store (Redis) against rules defined in a rule engine.
Components
Rate Limiter Middleware: Runs in the API gateway or as a library in each service. Intercepts every request, constructs a rate limit key, checks the counter, and allows or rejects.
Counter Store (Redis): Holds the current count or token state for each rate limit key. All nodes share the same counters via Redis.
Rule Engine: Stores rate limit rules (which limits apply to which users, endpoints, and plans). Rules are loaded into memory and refreshed periodically.
Configuration Service: Manages rules, plan definitions, and overrides. Provides an API for ops teams to update limits without deployments.
Detailed Design
Rate Limiting Algorithms
Four algorithms are commonly used, each with different trade-offs.
Fixed Window Counter
Divide time into fixed windows (e.g., 1-minute intervals). Count requests in the current window. Reject when the count exceeds the limit.
Window: minute 14:05 (14:05:00 to 14:05:59)
Key: rate:user-123:endpoint-abc:1405
Limit: 100 requests/minute
Request arrives at 14:05:32:
INCR rate:user-123:endpoint-abc:1405
Current count: 78 -> allow (78 <= 100)
Request arrives at 14:05:55:
INCR rate:user-123:endpoint-abc:1405
Current count: 101 -> reject (101 > 100)
Pros: Simple, low memory (one counter per window per key), atomic via Redis INCR.
Cons: Boundary spike problem. A user can send 100 requests at 14:05:59 and 100 more at 14:06:00, effectively sending 200 in 2 seconds while never exceeding the per-minute limit.
Boundary spike example:
14:05:58 - 14:05:59: 100 requests (window 1405, count = 100, allowed)
14:06:00 - 14:06:01: 100 requests (window 1406, count = 100, allowed)
Result: 200 requests in ~3 seconds, despite 100/min limit
Sliding Window Log
Store the timestamp of every request. When a new request arrives, remove timestamps older than the window, count remaining timestamps, and compare against the limit.
Key: rate:user-123:endpoint-abc (sorted set)
Request at 14:05:32:
ZREMRANGEBYSCORE key 0 (now - 60s) # remove old entries
ZADD key 14:05:32 14:05:32 # add current timestamp
ZCARD key # count entries
Count: 78 -> allow
Pros: Exact counting, no boundary spike problem.
Cons: High memory usage (stores every timestamp). For 100 requests/minute per user across 50M users, that is 5 billion timestamps. Impractical at scale.
Sliding Window Counter
A hybrid that approximates the sliding window using two fixed windows. Weight the previous window's count by the overlap percentage.
Current time: 14:05:15 (15 seconds into minute 1405)
Previous window (1404) count: 84
Current window (1405) count: 36
Window overlap: 45/60 = 75% of previous window is still relevant
Weighted count = 84 * 0.75 + 36 = 63 + 36 = 99
Limit: 100 -> allow (99 <= 100)
Pros: Low memory (two counters per key), smooths the boundary spike, good accuracy in practice.
Cons: Approximate, not exact. Accuracy degrades when traffic is very bursty within a window.
Redis implementation:
Key 1: rate:user-123:1404 = 84 (TTL: 120s)
Key 2: rate:user-123:1405 = 36 (TTL: 120s)
Compute weighted sum in application code or Lua script
Token Bucket
A bucket holds tokens, up to a maximum capacity. Each request consumes one token. Tokens are added at a fixed rate. If the bucket is empty, the request is rejected.
Bucket for user-123:
capacity: 100
refill_rate: 10 tokens/second
current_tokens: 45
last_refill: 14:05:30
Request at 14:05:32:
Elapsed since last refill: 2 seconds
New tokens: 2 * 10 = 20
Current tokens: min(45 + 20, 100) = 65
Consume 1 token: 65 - 1 = 64
Update: current_tokens = 64, last_refill = 14:05:32
Result: allow
Pros: Allows short bursts (up to bucket capacity) while enforcing long-term rate. Two parameters (capacity and refill rate) offer flexible tuning. Memory-efficient (one record per key).
Cons: Slightly more complex to implement atomically in a distributed setting.
Redis Lua script for atomic token bucket:
local key = KEYS[1]
local capacity = tonumber(ARGV[1])
local refill_rate = tonumber(ARGV[2])
local now = tonumber(ARGV[3])
local bucket = redis.call('HMGET', key, 'tokens', 'last_refill')
local tokens = tonumber(bucket[1]) or capacity
local last = tonumber(bucket[2]) or now
local elapsed = now - last
tokens = math.min(capacity, tokens + elapsed * refill_rate)
if tokens >= 1 then
tokens = tokens - 1
redis.call('HMSET', key, 'tokens', tokens, 'last_refill', now)
redis.call('EXPIRE', key, capacity / refill_rate * 2)
return 1 -- allowed
else
redis.call('HMSET', key, 'tokens', tokens, 'last_refill', now)
redis.call('EXPIRE', key, capacity / refill_rate * 2)
return 0 -- rejected
end
Leaky Bucket
Requests enter a queue (bucket) and are processed at a fixed rate. If the queue is full, new requests are dropped. This produces a perfectly smooth output rate.
Bucket for user-123:
queue_size: 100
drain_rate: 10 requests/second
current_queue: 72
Request arrives:
If current_queue < queue_size: enqueue, allow
Else: reject (queue full)
Processing:
Dequeue and process 10 requests/second
Pros: Perfectly smooth output rate, good for protecting downstream services.
Cons: Recent requests wait behind older ones (added latency). Less intuitive to configure. Rarely used for API rate limiting; more common in network traffic shaping.
Algorithm Selection Guide
Use Case | Recommended Algorithm
Simple API rate limiting | Sliding window counter
Burst-tolerant limiting | Token bucket
Strict smoothing | Leaky bucket
Exact counting (low volume) | Sliding window log
Maximum simplicity | Fixed window counter
Most production systems use token bucket or sliding window counter. Stripe uses token bucket. Cloudflare uses sliding window.
Distributed Counting with Redis
All API servers share state through Redis. Each rate limit check is a single round trip to Redis (or a Lua script for atomic multi-step operations).
Architecture:
API Server 1 --|
API Server 2 --|-- Redis Cluster (rate limit state)
API Server 3 --|
Redis Cluster:
Shard 1: keys with hash slots 0-5460
Shard 2: keys with hash slots 5461-10922
Shard 3: keys with hash slots 10923-16383
Key design ensures related rate limit keys hash to the same shard using hash tags:
Key: rate:{user-123}:endpoint-abc:1405
Key: rate:{user-123}:global:1405
Both hash on {user-123} -> same shard -> atomic multi-key operations
Local Cache for Reduced Latency
For extremely latency-sensitive paths, a two-tier approach reduces Redis round trips:
Tier 1: Local in-memory counter (per API server)
Tier 2: Redis (shared global counter)
Flow:
1. Check local counter first
2. If local counter says "definitely under limit" -> allow without Redis call
3. If local counter says "near limit" -> check Redis for accurate count
4. Periodically sync local counters with Redis
This trades some accuracy for lower latency. A user might slightly exceed their limit before the global counter catches up. For most use cases, this is acceptable.
Rule Engine
The rule engine defines which limits apply to which requests. Rules are evaluated in priority order, and the most specific matching rule wins.
Rules (evaluated top to bottom, first match wins):
1. IP 192.168.1.100 on POST /api/login -> 5 req/min (brute force protection)
2. Plan "enterprise" on /api/* -> 10,000 req/min
3. Plan "pro" on /api/* -> 1,000 req/min
4. Plan "free" on /api/* -> 100 req/min
5. Any user on POST /api/upload -> 10 req/hour
6. Global on /api/* -> 1,000,000 req/min (system protection)
Rules are stored in a configuration database and loaded into memory at startup. A watcher process detects changes and reloads rules within seconds. Rules specify:
Rule schema:
id: rule-001
identifier: user_id | api_key | ip_address | organization_id
match:
path_pattern: "/api/v1/orders*"
method: "POST"
plan: "free"
limit:
algorithm: "token_bucket"
capacity: 100
refill_rate: 2 # per second
action: "reject" # or "log_only" or "degrade"
priority: 10
Multi-Tier Limits
Requests are checked against multiple limits simultaneously. All limits must pass for the request to be allowed.
Tier 1: Per-endpoint limit (POST /api/orders: 10 req/min per user)
Tier 2: Per-user global limit (any endpoint: 1000 req/min per user)
Tier 3: Per-organization limit (all users in org: 50,000 req/min)
Tier 4: Global system limit (all traffic: 1,000,000 req/min)
Request from user-123 in org-456 to POST /api/orders:
Check: rate:{user-123}:post-orders -> 8/10 -> pass
Check: rate:{user-123}:global -> 450/1000 -> pass
Check: rate:{org-456}:global -> 32000/50000 -> pass
Check: rate:system:global -> 780000/1000000 -> pass
Result: allow
All four checks execute in a single Redis pipeline (or Lua script) to minimize round trips:
Redis pipeline:
INCR rate:{user-123}:post-orders:1405
INCR rate:{user-123}:global:1405
INCR rate:{org-456}:global:1405
INCR rate:system:global:1405
EXEC
-> Compare all four results against their limits
Response Headers
Rate-limited APIs return standard headers so clients can self-regulate:
HTTP/1.1 200 OK
X-RateLimit-Limit: 100
X-RateLimit-Remaining: 37
X-RateLimit-Reset: 1743681600
HTTP/1.1 429 Too Many Requests
X-RateLimit-Limit: 100
X-RateLimit-Remaining: 0
X-RateLimit-Reset: 1743681600
Retry-After: 45
The Retry-After header tells clients exactly when to retry, reducing unnecessary retries and load.
Synchronization Across Data Centers
For multi-region deployments, two strategies exist:
Centralized Redis (single region): All rate limit checks go to one Redis cluster. Simple but adds cross-region latency (50-200ms).
Local Redis with Async Sync: Each region has its own Redis. Counters are periodically synchronized across regions. Limits are divided across regions (e.g., if the global limit is 1000/min, each of 4 regions gets 250/min).
Strategy: Split limits across regions
Global limit: 1000 req/min
Regions: US-East, US-West, EU-West, AP-Southeast
Static split:
US-East: 400/min (largest traffic share)
US-West: 250/min
EU-West: 200/min
AP-Southeast: 150/min
Dynamic rebalancing:
Every 10 seconds, a coordinator checks actual usage
If US-East is at 380/400 and AP-Southeast is at 80/150:
Redistribute: US-East gets 450, AP-Southeast gets 100
The static split is simple but wastes capacity in low-traffic regions. Dynamic rebalancing adapts to traffic patterns but requires a coordination service.
For most systems, slightly over-allowing due to sync delays is acceptable. The rate limiter is a guardrail, not a precise meter.
Trade-offs & Alternatives
Accuracy vs Latency
Checking Redis on every request gives accurate counts but adds ~0.5ms per request. Local counters with periodic sync reduce latency to near-zero but may over-allow by 5-10%. Most APIs choose the Redis approach because 0.5ms is negligible relative to typical API latency (50-500ms).
Fail Open vs Fail Closed
If Redis is unavailable, should the limiter allow all traffic (fail open) or reject all traffic (fail closed)? Fail open risks overloading downstream services. Fail closed risks total service outage because of a rate limiter failure. Most systems fail open because the rate limiter should not be a single point of failure. The brief period without rate limiting is preferable to downtime.
Fixed Rules vs Adaptive Limits
Fixed rules are predictable but cannot respond to changing conditions. Adaptive limits (automatically reducing limits when the system is under stress) are more resilient but harder to reason about. A practical middle ground: fixed rules with manual override capabilities and alerting when limits are frequently hit.
API Gateway vs Library
The rate limiter can live in the API gateway (centralized) or as a library in each service (distributed). The gateway approach is simpler to manage but creates a single chokepoint. The library approach scales better but requires consistent configuration across services. Hybrid approaches (gateway for global limits, library for service-specific limits) are common.
Bottlenecks & Scaling
Redis as a Bottleneck
At 1M checks/second, Redis is the hot path. A single Redis instance handles ~100K operations/second. Solutions: Redis Cluster with 10+ shards, read replicas for non-critical checks, and local caching to reduce Redis load by 50-80%.
Hot Keys
A single popular API key or IP address can create a hot key in Redis. If one shard handles a disproportionate share of traffic, it becomes a bottleneck. Solutions: add jitter to key names (shard a single user's counter across multiple keys and sum them), or use local counters for known hot keys.
Hot key mitigation:
Instead of: rate:{user-celebrity}:global
Use: rate:{user-celebrity}:global:shard-{0-7} (8 sub-keys)
Sum all 8 shards to get the total count
Distributes load across multiple Redis slots
Rule Evaluation Performance
With hundreds of rules, evaluating every rule on every request is expensive. Organize rules into a trie or hash map indexed by path and plan. Most requests match a rule in O(1) after an initial path lookup.
Counter Drift in Multi-Region
Asynchronous synchronization across regions means global counters are eventually consistent. A user roaming between regions could briefly exceed their limit. For most APIs, this is acceptable. For payment or security-critical limits, route all traffic for a given user to a single region using sticky routing.
Memory Pressure
With 50 million active keys, Redis memory must be monitored. Set TTLs on all keys (slightly longer than the rate limit window). Use Redis memory policies (allkeys-lru) as a safety net. Monitor key count and memory usage with alerts.
Common Pitfalls
- Making the rate limiter a single point of failure: if the limiter goes down and the system fails closed, every API call fails. Always implement fail-open behavior with monitoring.
- Forgetting about distributed clock skew: servers have slightly different clocks. A time window that starts at different moments on different servers causes inconsistent limiting. Use Redis server time (via Lua scripts) rather than application server time.
- Not returning rate limit headers: without headers, clients cannot self-regulate and resort to blind retries, making the problem worse. Always include Retry-After on 429 responses.
- Applying one algorithm everywhere: token bucket is great for bursty API traffic but wrong for login attempt limiting (use fixed window with a low count). Match the algorithm to the use case.
- Ignoring the cost of Redis round trips: at high throughput, even 0.5ms per check adds up. Use pipelining for multi-tier checks and local caching for the fast path.
- Rate limiting by IP only: behind NAT or corporate proxies, thousands of users share one IP. Combine IP with API key or user ID for accurate per-user limiting.
Key Takeaways
- Token bucket and sliding window counter are the two most practical algorithms for production rate limiting. Token bucket handles bursts gracefully; sliding window counter is simpler to implement.
- Redis is the standard backing store for distributed rate limiting. Lua scripts ensure atomicity. Redis Cluster handles sharding.
- Multi-tier limits (per endpoint, per user, per org, global) provide defense in depth. Check all tiers in a single Redis pipeline.
- Fail open is the correct default. The rate limiter exists to protect the system, not to become its weakest link.
- Return standard rate limit headers on every response. Clients that know their remaining budget generate less excess traffic.
- Perfect accuracy across distributed nodes is not worth the latency cost. Slight over-allowing during sync windows is an acceptable trade-off for sub-millisecond overhead.