Design a Search Engine
This case study walks through the design of a web-scale search engine similar to Google or Bing. The system crawls billions of web pages, builds an inverted index, ranks results by relevance & authority, and serves queries with sub-second latency. It also covers autocomplete, spell correction, and the tension between index freshness & completeness.
Functional Requirements
- Web crawling: discover & fetch web pages across the internet, respecting robots.txt and politeness policies
- Indexing: build & maintain an inverted index mapping terms to documents
- Query processing: parse user queries, retrieve matching documents, rank them, and return results
- Ranking: combine text relevance (BM25), link authority (PageRank), freshness, and user engagement signals
- Spell correction: detect & suggest corrections for misspelled queries
- Autocomplete: suggest query completions as the user types, based on popularity & personalization
- Snippet generation: extract relevant text snippets from matched documents for the results page
- Image & video search: index non-text content via metadata, alt text, and surrounding context
- SafeSearch filtering: classify & filter explicit or harmful content
Non-Functional Requirements
- Latency: search results returned within 500 ms (p99), autocomplete within 100 ms
- Availability: 99.99% uptime; search is a critical daily utility
- Scalability: index 50 B+ web pages, serve 100 K+ queries per second
- Freshness: breaking news pages indexed within minutes; long-tail pages within days
- Completeness: maximize coverage of the crawlable web
- Fault tolerance: no single point of failure; graceful degradation if index shards are unavailable
Estimation
Crawling
- 50 B pages on the crawlable web
- Average page size: 100 KB (HTML + text)
- Full re-crawl cycle: 30 days -> ~19 M pages/second crawl rate
- Freshness tier: 1 B "hot" pages re-crawled every hour -> ~278 K pages/second
- Outbound bandwidth for crawling: 19 M * 100 KB = ~1.9 TB/second (distributed across thousands of crawlers)
Index Storage
- 50 B pages; average 500 unique terms per page after stemming & stop-word removal
- Inverted index entry: term -> list of (doc_id, term_frequency, positions)
- Compressed inverted index: ~100 TB (with delta encoding & variable-byte compression)
- Document store (raw content for snippet generation): 50 B * 100 KB = 5 PB (compressed ~1 PB)
- PageRank scores & metadata: ~500 GB
Query Traffic
- 10 B queries per day -> ~115 K queries/second average
- Peak: 2x average -> ~230 K queries/second
- Each query touches ~100 index shards in parallel
- Result page size: ~50 KB (10 results with snippets)
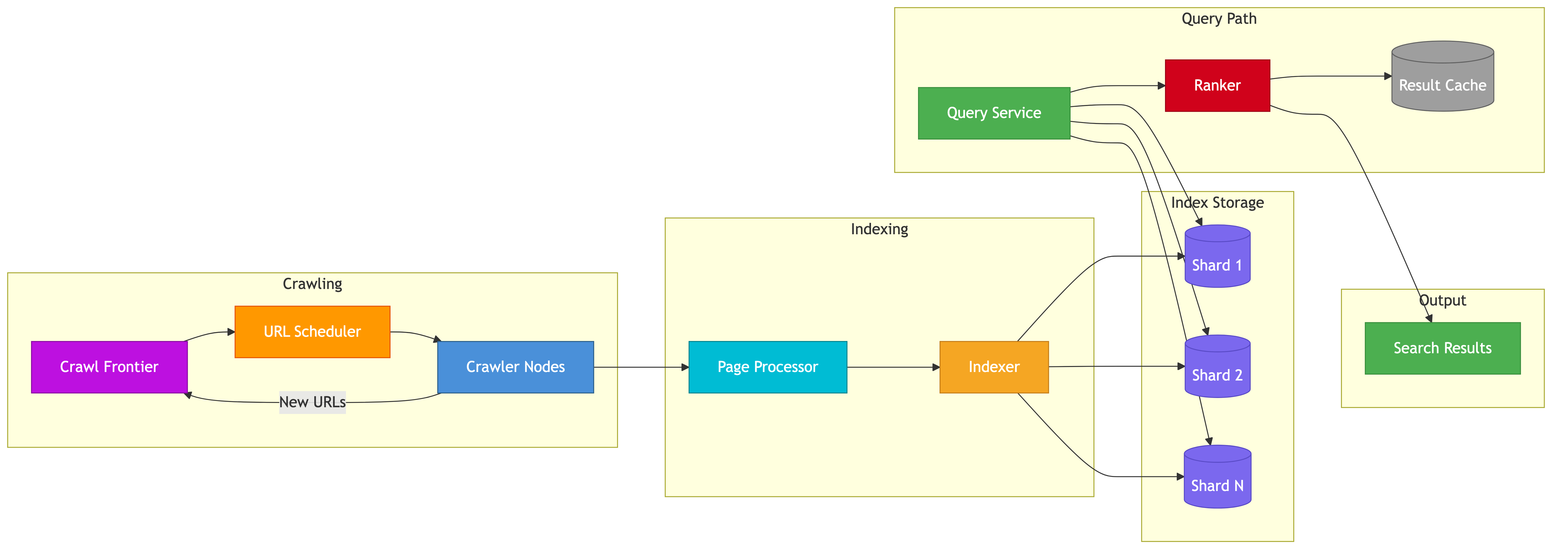
High-Level Design
The system has three major pipelines that operate at different timescales.
Offline Pipeline (Hours to Days)
Crawling, indexing, and link analysis run continuously but produce batch outputs.
URL Frontier -> Crawler Fleet -> Raw Page Store (S3/HDFS)
Raw Page Store -> Parser -> Cleaned Documents
Cleaned Documents -> Indexer -> Inverted Index Shards
Cleaned Documents -> Link Extractor -> Link Graph
Link Graph -> PageRank Computation -> PageRank Scores
Near-Real-Time Pipeline (Minutes)
A fast-track pipeline handles breaking news and frequently updated pages.
RSS Feeds / Sitemaps / Change Detection -> Priority Crawler
Priority Crawler -> Streaming Indexer -> Real-Time Index Supplement
The real-time supplement is a small, frequently rebuilt index that is merged with query results from the main index.
Online Pipeline (Milliseconds)
Query serving is the latency-critical path.
User -> Load Balancer -> Query Frontend
Query Frontend -> Spell Checker -> Autocomplete (if partial query)
Query Frontend -> Query Parser -> Index Servers (fan-out to shards)
Index Servers -> Merge & Rank -> Snippet Generator -> Results Page
Detailed Design
Web Crawling
The crawler is a distributed system running on thousands of machines. Each crawler instance pulls URLs from the URL Frontier, fetches the page, and stores the raw HTML.
URL Frontier: a priority queue that determines which URLs to crawl next. Priority is based on:
- Freshness score: pages that change frequently get re-crawled sooner
- PageRank: high-authority pages are crawled more often
- Politeness: rate-limit requests per domain to avoid overloading hosts (typically 1 request per second per domain)
URL Frontier (priority queue, partitioned by domain)
-> Crawler Worker
-> DNS Resolution (cached aggressively)
-> HTTP Fetch (with timeout, redirect following, retry)
-> robots.txt Check (cached per domain)
-> Store raw HTML + headers + fetch timestamp
-> Extract outgoing URLs -> feed back into URL Frontier
Duplicate detection: many URLs point to the same content. The crawler computes a SimHash or MinHash fingerprint of each page. If the fingerprint matches an already-crawled page, the duplicate is discarded.
Crawl traps: some sites generate infinite URLs (calendars, session IDs in URLs). Mitigations include URL normalization, per-domain URL count limits, and depth limits.
Parsing & Content Extraction
Raw HTML goes through a processing pipeline:
- HTML parsing — extract text, title, headings, meta tags, links
- Boilerplate removal — strip navigation, ads, footers to isolate main content
- Language detection — classify the page language for language-specific indexing
- Tokenization — split text into terms
- Normalization — lowercase, remove diacritics, apply stemming (Porter stemmer for English)
- Stop-word removal — optional; modern engines often keep stop words for phrase matching
Inverted Index
The inverted index is the core data structure. For each term, it stores a posting list: an ordered list of documents containing that term, along with metadata.
term -> [(doc_id_1, tf, [pos1, pos2, ...]),
(doc_id_2, tf, [pos1]),
...]
- doc_id: globally unique document identifier (64-bit integer)
- tf: term frequency in the document
- positions: byte offsets for phrase matching & snippet generation
Compression: posting lists are sorted by doc_id. Delta encoding reduces the values, and variable-byte or PForDelta encoding compresses them further. A well-compressed inverted index for 50 B documents fits in ~100 TB.
Sharding: the index is partitioned across thousands of machines. Two main strategies:
- Document-partitioned: each shard holds the complete index for a subset of documents. A query goes to ALL shards, and results are merged.
- Term-partitioned: each shard holds the posting lists for a subset of terms. A query goes to only the shards holding query terms, but multi-term queries require cross-shard coordination.
Document-partitioned sharding is standard in practice (Google, Elasticsearch) because it is simpler to build, balance, and query.
50 B documents / 5 M documents per shard = 10,000 shards
Each shard replicated 3x = 30,000 shard replicas
Distributed across ~5,000 machines (6 shard replicas per machine)
Ranking
Ranking combines multiple signals into a single relevance score.
BM25 (text relevance): an improvement over TF-IDF that accounts for term frequency saturation and document length normalization.
BM25(q, d) = sum over terms t in q:
IDF(t) * (tf(t,d) * (k1 + 1)) / (tf(t,d) + k1 * (1 - b + b * |d| / avgdl))
where:
IDF(t) = log((N - df(t) + 0.5) / (df(t) + 0.5))
k1 = 1.2 (term frequency saturation parameter)
b = 0.75 (document length normalization parameter)
N = total documents, df(t) = documents containing term t
PageRank (link authority): models the web as a directed graph. Each page's score is proportional to the sum of scores of pages linking to it, divided by their outbound link count.
PR(p) = (1 - d) / N + d * sum over pages q linking to p: PR(q) / outlinks(q)
where d = 0.85 (damping factor), N = total pages
PageRank is computed offline as an iterative algorithm over the full link graph. It converges after 40-50 iterations. For 50 B pages, this requires a distributed graph processing framework (MapReduce, Pregel, or Apache Giraph).
Combined ranking: a learning-to-rank model (e.g., LambdaMART or a neural ranker) combines BM25, PageRank, freshness, click-through rate, domain authority, content quality signals, and hundreds of other features. The model is trained on human relevance judgments and click logs.
The ranking pipeline has two stages:
- Candidate retrieval: BM25 over the inverted index returns the top ~1,000 candidates per shard
- Re-ranking: the learning-to-rank model scores the merged candidates and returns the top 10
Query Processing
When a user submits a query:
- Query parsing: tokenize, stem, detect phrases (quoted terms), identify operators (site:, filetype:)
- Query expansion: add synonyms or related terms to improve recall
- Spell check: if the query has low index hits, suggest a corrected version ("Did you mean...?")
- Fan-out: the query frontend sends the parsed query to all index shards in parallel
- Per-shard retrieval: each shard runs BM25, returns top-K candidates with scores
- Merge: the query frontend merges results from all shards by score, deduplicates, and takes top N
- Re-rank: the top candidates pass through the learning-to-rank model
- Snippet generation: for each result, extract the most relevant passage containing query terms
- Return: serialize results with titles, URLs, snippets, and metadata
The fan-out to 10,000 shards is the latency bottleneck. Mitigations:
- Return partial results if some shards are slow (tail-at-scale problem)
- Use hedged requests: send the query to two replicas of each shard, take the faster response
- Set aggressive timeouts (e.g., 200 ms per shard) and exclude slow shards from the merge
Spell Correction
Spell correction uses multiple approaches:
- Edit distance: for each query term, find dictionary words within edit distance 1-2 (Levenshtein). Pre-compute candidates using a BK-tree or symmetric delete algorithm.
- N-gram overlap: index terms by character n-grams (trigrams). A misspelled word shares many trigrams with the correct word.
- Query log mining: the most powerful signal. If users frequently type "amazn" and then immediately re-search "amazon", the system learns the correction. This handles domain-specific terms that no dictionary contains.
The correction is applied only when the original query returns few or poor results. The corrected query is shown as a suggestion, not forced, to respect user intent.
Autocomplete
Autocomplete suggests complete queries as the user types. The system must respond within 100 ms.
Data source: the top 10-100 M queries by frequency, updated daily from query logs.
Data structure: a trie (prefix tree) with query strings as keys and frequency counts as values. For serving, the trie is stored in memory on dedicated autocomplete servers.
User types "how to b"
Trie lookup: prefix "how to b" -> ["how to bake bread", "how to boil eggs",
"how to buy a house", ...]
Ranked by: frequency, recency, personalization (user's past queries)
For efficiency, each trie node stores the top-K completions for its prefix, pre-computed offline. This avoids scanning all descendants at query time.
Autocomplete servers are sharded by prefix range (a-f on shard 1, g-m on shard 2, etc.) and replicated for availability.
Freshness vs Completeness
A fundamental tension in search engine design:
- Freshness: users expect breaking news to appear within minutes
- Completeness: the full web takes weeks to crawl; rebuilding the index is expensive
The solution is a tiered architecture:
- Base index: the full 50 B page index, rebuilt weekly or continuously via incremental updates
- Real-time index: a small index (millions of pages) covering breaking news, updated every few minutes
- Query merging: results from the base index and real-time index are merged at query time, with a freshness boost for recent pages
The real-time index uses a simpler, less compressed format optimized for fast writes. It is periodically merged into the base index and discarded.
Change detection for re-crawling uses HTTP conditional requests (If-Modified-Since, ETag) and sitemap change frequencies.
Trade-Offs & Alternatives
Document-Partitioned vs Term-Partitioned Index
Document-partitioned (chosen) requires fanning out every query to all shards but is simple to manage — adding documents means adding shards, and each shard is self-contained. Term-partitioned reduces fan-out for single-term queries but makes phrase queries and multi-term queries expensive since posting lists for different terms live on different machines. In practice, every major search engine uses document-partitioned sharding.
BM25 vs Neural Retrieval
BM25 is fast, interpretable, and good enough for candidate retrieval. Neural retrieval (dense vector search with embeddings) better captures semantic meaning ("cheap flights" matching "affordable airfare") but is computationally expensive for billions of documents.
The practical approach is BM25 for first-stage retrieval, followed by a neural re-ranker on the top candidates. Full neural first-stage retrieval (e.g., approximate nearest neighbor search over document embeddings) is emerging but requires significant infrastructure (vector index, GPU serving).
Pre-Computed vs On-the-Fly Snippets
Pre-computing snippets for every query-document pair is impossible (too many combinations). Pre-computing snippets for popular queries saves latency but uses enormous storage. On-the-fly snippet generation from a cached document store is the standard approach, adding ~10-20 ms to query latency.
PageRank Alternatives
PageRank is one link-analysis algorithm. Alternatives include HITS (Hyperlink-Induced Topic Search), which computes hub & authority scores per query, and CheiRank, which analyzes outgoing links. Modern engines use PageRank as one of many features rather than the primary ranking signal.
Bottlenecks & Scaling
Crawler Throughput
Crawling 50 B pages in 30 days requires ~19 M pages/second. This demands:
- Thousands of crawler machines distributed globally
- Aggressive DNS caching (DNS lookups are a major bottleneck)
- Connection pooling per domain
- Asynchronous I/O to maximize network utilization per machine
- Bandwidth contracts with ISPs and CDNs
Index Build Time
Building the inverted index from 50 B documents is a massive MapReduce job:
- Map phase: emit (term, doc_id, tf, positions) for each term in each document
- Reduce phase: group by term, sort posting lists by doc_id, compress
This takes hours on a large cluster. Incremental indexing (processing only new/changed documents and merging into the existing index) avoids full rebuilds.
Query Fan-Out Latency
Every query fans out to 10,000 shards. The tail-latency problem is severe: if each shard responds within 10 ms 99% of the time, the probability that ALL 10,000 respond within 10 ms is essentially zero.
Mitigations:
- Hedged requests: send to 2 replicas, take the first response
- Partial results: return results from shards that responded within the timeout, skip slow ones
- Canary shards: test query on a few shards first to estimate selectivity; skip shards unlikely to have relevant results
- Tiered index: keep the most important 1 B pages in a "first tier" index with fewer shards; only fan out to the full index if first-tier results are insufficient
Link Graph Processing
Computing PageRank over a 50 B node graph requires distributed graph processing. The graph does not fit in the memory of a single machine.
- Use a distributed graph framework (Pregel, Apache Giraph, or custom MapReduce)
- The link graph is stored as an adjacency list compressed with techniques like WebGraph
- PageRank computation takes 40-50 iterations, each requiring a full pass over the graph
- Incremental PageRank approximations avoid recomputing from scratch when the graph changes slightly
Storage & Replication Costs
- Inverted index: 100 TB * 3 replicas = 300 TB on SSDs for fast access
- Document store: ~1 PB compressed, stored on HDDs or object storage (accessed only for snippet generation)
- Total infrastructure: thousands of machines across multiple data centers
- Cost optimization: compress aggressively, tier storage (SSD for hot index, HDD for document store), decommission stale index partitions
Common Pitfalls
- Politeness violations: crawling too aggressively gets the crawler banned by webmasters and potentially creates legal liability; always respect robots.txt and enforce per-domain rate limits
- Crawl traps: infinite URL spaces (calendars, faceted navigation, session IDs) waste crawler resources; detect and blacklist patterns
- Index staleness: if the crawl-to-index pipeline has multi-day lag, users see outdated results for time-sensitive queries; a real-time index tier is essential
- Ignoring tail latency: optimizing average query latency while ignoring p99 leaves users with inconsistent experiences; hedged requests and partial results are necessary
- Ranking manipulation: SEO spam and link farms try to game PageRank and BM25; adversarial robustness (spam detection, link quality analysis) must be built into the ranking pipeline
- Over-relying on PageRank: new pages have no inlinks and get zero PageRank; freshness signals and content quality features prevent burying new but relevant content
- Autocomplete bias: suggesting offensive or misleading completions causes PR crises; aggressive filtering and human review of top suggestions are required
Key Takeaways
- The inverted index is the foundational data structure: terms map to sorted, compressed posting lists; document-partitioned sharding is the industry standard for web-scale search
- Ranking is a multi-stage pipeline: BM25 for fast candidate retrieval over the full index, then a machine-learned model for re-ranking the top candidates
- Freshness vs completeness is managed through a tiered index: a large base index rebuilt incrementally plus a small real-time index for breaking content, merged at query time
- The tail-latency problem dominates query serving when fanning out to thousands of shards; hedged requests and partial results are essential mitigations
- Web crawling at scale is itself a distributed systems problem requiring URL prioritization, politeness enforcement, duplicate detection, and trap avoidance
- PageRank remains a valuable authority signal but is one of hundreds of ranking features in modern search engines; learning-to-rank models combine them all
- Autocomplete and spell correction rely heavily on query log mining rather than pure algorithmic approaches; real user behavior is the strongest signal