Design a URL Shortener
A URL shortener takes a long URL and produces a compact alias (e.g., https://short.ly/a1B2c3) that redirects to the original. Services like Bitly, TinyURL, & short.io handle billions of redirects per day with sub-millisecond latency budgets.
This document walks through the full design: requirements, estimation, architecture, deep dives, trade-offs, & scaling considerations.
Functional Requirements
- Given a long URL, generate a unique short URL
- When a user visits the short URL, redirect to the original long URL
- Users can optionally specify a custom alias
- Links can have a configurable TTL (time-to-live) after which they expire
- Basic analytics: track click count, referrer, timestamp, & geo per redirect
Non-Functional Requirements
- High availability — the redirect path must never go down
- Low latency — redirects should complete in under 50ms at p99
- Read-heavy workload — read-to-write ratio of roughly 100:1
- Short URLs should be as compact as possible (7-8 characters)
- Shortened URLs should not be guessable or sequential
Estimation
Traffic
- 100 million new URLs created per month
- 10 billion redirects per month (100:1 read-to-write ratio)
- Writes: ~40 per second on average, ~200/s at peak
- Reads: ~4,000 per second on average, ~20,000/s at peak
Storage
- Each record stores: short key (7 bytes), long URL (avg 200 bytes), metadata (100 bytes) = ~300 bytes
- 100 million records/month x 300 bytes = 30 GB/month
- Over 5 years: ~1.8 TB of URL data
Bandwidth
- Redirect responses are tiny (HTTP 301/302 with a Location header) — ~500 bytes each
- Read bandwidth: 4,000 x 500 bytes = 2 MB/s average
- Write bandwidth is negligible
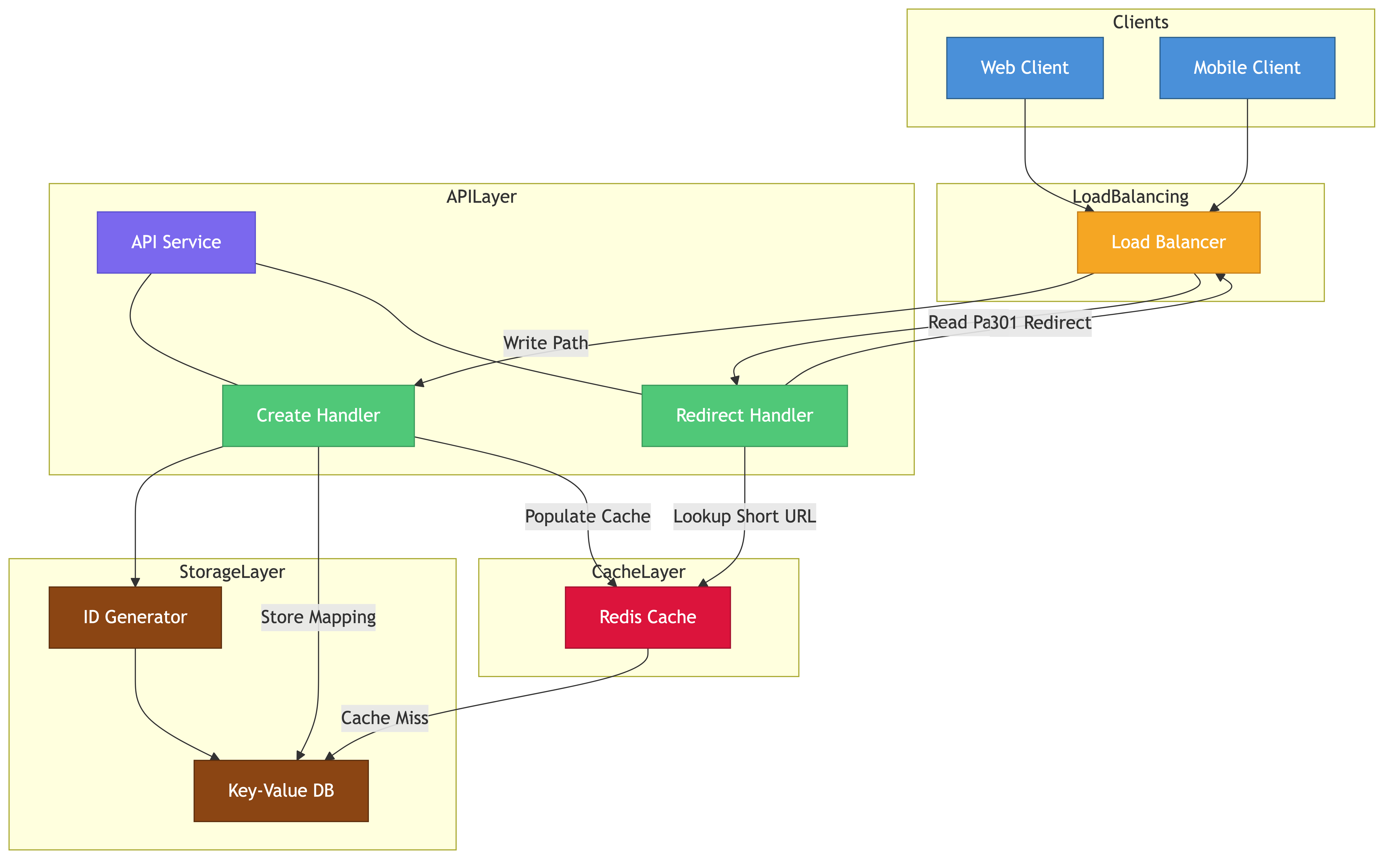
High-Level Design
The system has three main paths: URL creation, URL redirection, & analytics collection.
Components
- API Gateway — rate limiting, authentication, request routing
- Shortening Service — generates the short key, stores the mapping
- Redirect Service — looks up the short key, returns the redirect response
- Key Generation Service — pre-generates unique keys to avoid collisions at write time
- Cache Layer — holds hot URLs in memory (Redis/Memcached)
- Database — persistent store for URL mappings
- Analytics Pipeline — async ingestion of click events
Request Flow: Create Short URL
Client -> API Gateway -> Shortening Service -> Key Generation Service
-> Database (write mapping)
-> return short URL to client
Request Flow: Redirect
Client -> API Gateway -> Redirect Service -> Cache (hit? return)
-> Database (miss? fetch, populate cache)
-> return 301/302 with Location header
-> Analytics Pipeline (async log click event)
Detailed Design
Key Generation
This is the core algorithmic challenge. Several approaches exist.
Approach 1: Base62 Encoding of a Counter
Use a global counter (or distributed counter) and encode the value in base62 (a-z, A-Z, 0-9). A 7-character base62 string gives 62^7 = ~3.5 trillion unique keys.
counter value: 1,000,000
base62 encoded: "4c92"
padded to 7 chars: "0004c92"
Pros: guaranteed uniqueness, simple. Cons: sequential output is predictable; requires a coordination point for the counter.
To avoid predictability, apply a bijective shuffle (e.g., multiply by a large coprime modulo 62^7) so the output looks random while remaining reversible internally.
Approach 2: Hash-Based
Compute MD5 or SHA-256 of the long URL and take the first 7 base62 characters.
md5("https://example.com/very/long/path") = "a3f2b8..."
first 43 bits -> base62 -> "kR9mW2x"
Pros: deterministic for the same input, no coordination needed. Cons: collisions are possible with only 43 bits; must handle them (check DB, append salt & rehash).
Approach 3: Pre-Generated Key Pool (Recommended)
A dedicated Key Generation Service (KGS) pre-generates a large batch of unique random keys and stores them in a key pool. When the Shortening Service needs a key, it pulls one from the pool.
Key Pool Table
+-----------+--------+
| key | used |
+-----------+--------+
| "kR9mW2x" | false |
| "p4Tz1Qa" | false |
| "bN7yR3s" | true |
+-----------+--------+
Implementation details:
- KGS keeps two tables:
unused_keys&used_keys - KGS loads a batch (e.g., 1,000 keys) into memory
- Shortening Service instances request keys over an internal RPC
- If a KGS instance crashes, those in-memory keys are lost (acceptable waste)
- Multiple KGS replicas each own non-overlapping ranges
This approach eliminates collision handling entirely and decouples key generation from the write path.
Custom Aliases
When a user provides a custom alias, the Shortening Service checks the database for conflicts. Custom aliases bypass the KGS entirely. Store them in the same mapping table but flag them so the KGS never generates a conflicting key.
Redirect: 301 vs 302
- 301 Moved Permanently — the browser caches the redirect. Subsequent visits skip the shortener entirely. Lower server load but no analytics on repeat visits.
- 302 Found (Temporary) — the browser does not cache. Every visit hits the shortener. Better for analytics but higher server load.
In practice, use 302 for URLs where analytics matter (most use cases). Use 301 only for permanent, high-traffic links where analytics are not needed.
Cache Strategy
The read path is latency-sensitive. A cache layer dramatically reduces database load.
Read path:
1. Check Redis for key -> long URL mapping
2. Cache hit: return immediately
3. Cache miss: query database, populate cache, return
- Use an LRU eviction policy
- Cache TTL should match or be shorter than the URL's expiry
- At 20,000 reads/s with an 80% cache hit rate, only 4,000 queries/s reach the DB
- Hot URLs (viral links) benefit enormously — a single viral link can generate millions of hits
Database Design
A simple key-value mapping is the core data model.
url_mappings
+-------------+----------------------------------------------+
| short_key | kR9mW2x (PK, varchar 7) |
| long_url | https://example.com/... (varchar 2048) |
| user_id | 12345 (bigint, nullable) |
| created_at | 2026-03-15 10:30:00 (timestamp) |
| expires_at | 2027-03-15 10:30:00 (timestamp, nullable) |
| is_custom | false (boolean) |
+-------------+----------------------------------------------+
Database choice: a NoSQL store like DynamoDB or Cassandra fits well. The access pattern is almost exclusively point lookups by short_key. No complex joins needed. Cassandra gives tunable consistency & easy horizontal scaling.
If using a relational database, shard by the first two characters of short_key for even distribution.
TTL & Expiry
- Store
expires_atalongside each mapping - On redirect, check if the link has expired before redirecting
- Run a background cleanup job to delete expired entries & return keys to the pool
- Expired entries in the cache are handled by setting the Redis TTL to match
expires_at
Analytics
Analytics should never slow down the redirect path. Use an asynchronous pipeline.
Redirect Service -> Kafka topic "click_events" -> Consumer -> Analytics DB
Click event payload:
{
short_key: "kR9mW2x",
timestamp: "2026-03-15T10:30:00Z",
referrer: "https://twitter.com",
user_agent: "Mozilla/5.0...",
ip_geo: "US-CA",
ip_address: "hashed"
}
- Aggregate data in a time-series store (ClickHouse, TimescaleDB) or a data warehouse
- Pre-compute hourly & daily rollups for dashboard queries
- Store raw events for 90 days, rollups indefinitely
Trade-Offs & Alternatives
Key Generation: Counter vs Hash vs Pool
| Approach | Uniqueness Guarantee | Coordination Cost | Predictability |
|---|---|---|---|
| Counter | Perfect | High (single point) | High (needs shuffle) |
| Hash | Probabilistic | None | Low |
| Pre-gen Pool | Perfect | Medium (KGS) | Low |
The pre-generated pool is the best balance for most production systems.
SQL vs NoSQL
SQL (PostgreSQL) works fine at moderate scale with read replicas & sharding. NoSQL (DynamoDB, Cassandra) scales more naturally for this key-value workload but sacrifices ad-hoc query flexibility. Choose based on your team's operational expertise.
Embedded Analytics vs Separate Pipeline
Logging clicks synchronously into the main database is simpler but couples analytics to the critical redirect path. A Kafka-backed pipeline adds operational complexity but keeps the redirect path fast & resilient to analytics failures.
Bottlenecks & Scaling
Read Path Bottleneck
The redirect path takes 100x more traffic than writes. Mitigations:
- Multi-layer caching (local in-process cache + Redis)
- Database read replicas
- CDN-level caching for the most popular URLs (set Cache-Control headers with 302 carefully)
Write Path Bottleneck
At 200 writes/s peak, this is rarely a bottleneck. If it becomes one:
- Batch writes to the database
- The KGS can buffer keys so the write path never waits for key generation
Hot Keys
A single viral URL can receive millions of hits per second. Mitigations:
- Replicate hot keys across multiple Redis nodes
- Use a local in-memory cache on each Redirect Service instance with a short TTL (5-10 seconds)
Database Scaling
- Shard by
short_keyprefix for even distribution - 1.8 TB over 5 years is manageable on a single shard with SSDs but plan for 3-5 shards for throughput
- Use consistent hashing if adding shards dynamically
KGS Failure
If all KGS instances go down, the Shortening Service cannot create new URLs but redirects continue working. Run at least 3 KGS replicas across availability zones.
Geographic Distribution
For a globally used service, latency matters. Deploy redirect servers in multiple regions:
- Place Redis cache replicas in each region
- Use GeoDNS to route users to the nearest redirect cluster
- URL creation can be centralized (writes are infrequent) but redirect must be local
- Replicate the database asynchronously across regions — eventual consistency is acceptable for URL mappings since they are immutable after creation
Abuse & Security
URL shorteners are frequently abused for phishing & malware distribution.
- Scan destination URLs against Google Safe Browsing & other threat intelligence feeds at creation time
- Re-scan periodically since a destination page can turn malicious after the short link is created
- Rate limit creation by IP address & API key
- Require CAPTCHA for anonymous (unauthenticated) link creation
- Maintain a blocklist of known malicious domains
- Log all creation events with IP & user agent for abuse investigations
Monitoring & Alerting
Key metrics to track in production:
- Redirect latency at p50, p95, & p99
- Cache hit ratio (target above 80%)
- KGS key pool size (alert if below a threshold to avoid running out)
- Error rate on redirects (404s for invalid keys, 410s for expired keys)
- Database query latency & connection pool utilization
- Creation rate anomalies (sudden spikes may indicate abuse)
Common Pitfalls
- Ignoring collision handling with hash-based keys — a 7-character hash has only ~43 bits of entropy. Collisions will happen at scale. Always check the database on insert or use the pool approach instead.
- Using 301 redirects by default — browsers cache 301s aggressively. You lose all analytics for repeat visitors. Use 302 unless you have a specific reason not to.
- Synchronous analytics on the redirect path — even a fast database insert adds 2-5ms. At 20,000 requests/s that matters. Always log asynchronously.
- Not handling expired URLs in the cache — if you only check expiry in the database, cached expired URLs will still redirect. Sync Redis TTLs with URL expiry.
- Sequential or predictable short keys — attackers can enumerate all URLs by incrementing the key. Use random keys or a shuffled counter.
- Forgetting rate limiting on the creation endpoint — without it, an attacker can exhaust your key space or fill your database with junk entries.
Key Takeaways
- A URL shortener is a read-heavy system (100:1). Optimize the read path with caching & keep writes simple.
- Pre-generated key pools eliminate collision handling & decouple key generation from the critical path.
- Use 302 redirects when analytics matter; 301 when minimizing server load is the priority.
- Keep analytics asynchronous — the redirect path should do one cache/DB lookup & return immediately.
- The data model is a simple key-value mapping. NoSQL databases are a natural fit, but sharded SQL works too.
- Plan for hot keys (viral URLs) with local caching & replicated cache entries.