Datacenter Networking
Datacenter Network Requirements
| Requirement | Description |
|---|---|
| High bisection bandwidth | Full bandwidth between any two server groups |
| Low latency | Microsecond-scale for storage and RPC traffic |
| Scalability | Support 100K+ servers |
| Fault tolerance | No single point of failure; fast failover |
| Cost efficiency | Use commodity hardware where possible |
Datacenter Topologies
Fat Tree / Clos Network
The most widely deployed datacenter topology, based on Clos network theory (Charles Clos, 1953).
Core Switches (k/2)^2
/ | | \
Agg Agg Agg Agg (k pods, k/2 agg switches per pod)
/ \ / \ / \ / \
ToR ToR ToR ToR ToR ToR (k/2 ToR switches per pod)
||| ||| ||| ||| ||| |||
servers (k/2 per ToR)
For a k-ary fat tree:
- k pods, each with k/2 aggregation and k/2 ToR (edge) switches.
- (k/2)^2 core switches.
- Supports k^3/4 hosts.
- Full bisection bandwidth using commodity switches.
- k=48 example: 27,648 hosts, 2,880 switches.
Leaf-Spine (2-Tier Clos)
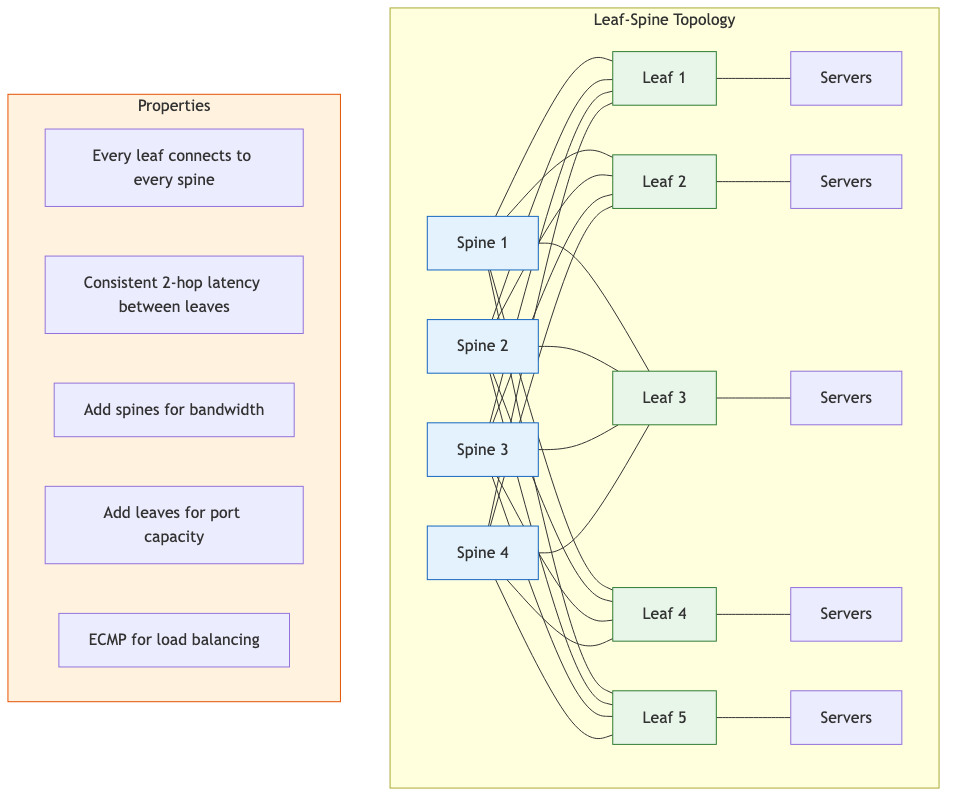
Simplified Clos variant common in modern datacenters.
Spine 1 Spine 2 Spine 3 Spine 4
| \ / | \ / | \ / |
Leaf1 Leaf2 Leaf3 Leaf4 Leaf5
|||| |||| |||| |||| ||||
servers
- Every leaf connects to every spine (full mesh between tiers).
- Consistent hop count (2 hops between any two leaves).
- Easy to scale: add more spines for bandwidth, more leaves for ports.
- No oversubscription when properly provisioned.
Dragonfly
Designed for high-radix switches, reducing cabling cost.
Group structure:
Each group: fully connected switches (intra-group links)
Between groups: each switch has inter-group links to other groups
- Three levels of links: intra-switch (to servers), intra-group (between switches in a group), inter-group (between groups).
- High bandwidth with fewer cables than fat tree at large scale.
- Requires adaptive routing to avoid congestion on inter-group links.
- Used in HPC systems (Cray Slingshot) more than cloud datacenters.
Topology Comparison
| Property | Fat Tree | Leaf-Spine | Dragonfly |
|---|---|---|---|
| Bisection BW | Full | Full (if provisioned) | Full (with adaptive routing) |
| Hop count | 2-4 | 2 | 2-3 |
| Cabling complexity | High | Moderate | Low |
| Scalability | Very high | High | Very high |
| Typical use | Cloud DC | Cloud DC | HPC |
Datacenter Transport
DCTCP (Data Center TCP)
Uses ECN to achieve high throughput with minimal queuing.
Switch: mark packets with CE when queue > K (e.g., K = 20 packets)
Receiver: feed back fraction of marked packets
Sender: cwnd = cwnd * (1 - alpha/2)
where alpha = EWMA of marked fraction
- Maintains queue occupancy near K, far below buffer capacity.
- Requires ECN support on all switches and endpoints.
- Coexistence with standard TCP requires careful isolation.
RDMA (Remote Direct Memory Access)
Allows direct memory-to-memory transfers between servers without CPU involvement or kernel intervention.
InfiniBand RDMA
- Native RDMA on InfiniBand fabric.
- Lossless transport built into the fabric.
- Dominant in HPC clusters.
RoCE (RDMA over Converged Ethernet)
- RDMA over standard Ethernet (RoCEv1 over L2, RoCEv2 over UDP/IP).
- Requires Priority Flow Control (PFC) or other lossless mechanisms.
- RoCEv2 is routable, enabling RDMA across L3 boundaries.
RoCEv2 packet:
Ethernet | IP | UDP (port 4791) | IB BTH | Payload | ICRC
PFC and Lossless Ethernet
PFC (IEEE 802.1Qbb) provides per-priority flow control:
- Switch sends PAUSE frame when queue exceeds threshold.
- Sender halts transmission for that priority class.
- Problem: PFC deadlocks (circular buffer dependencies) and head-of-line blocking.
- Mitigations: PFC watchdog timers, DCQCN congestion control, careful VLAN/priority design.
DCQCN (Data Center QCN)
Congestion control for RoCE combining ECN-based rate reduction (like DCTCP) with QCN-style rate recovery:
- Switch marks packets with ECN at threshold.
- Receiver generates CNP (Congestion Notification Packet).
- Sender reduces rate based on CNP.
- Rate recovery through timer-based increase and active increase phases.
Traffic Engineering
ECMP (Equal-Cost Multi-Path)
- Standard approach: hash on flow 5-tuple to select among equal-cost paths.
- Provides load balancing across parallel links in Clos topologies.
- Limitations: hash polarization (same hash at multiple stages), flow collisions (large flows share a path), no adaptation to congestion.
CONGA (Congestion-Aware Load Balancing)
Distributed, congestion-aware load balancing:
1. Leaf switch selects path based on congestion feedback from remote leaf.
2. Remote leaf piggybacks congestion metric (max link utilization on path) in ACKs.
3. Source leaf maintains congestion table per destination leaf per path.
4. Selects least-congested path for each flowlet (not per-packet to avoid reordering).
- Operates at flowlet granularity (bursts within a flow separated by gaps > ~500us).
- Achieves near-optimal load balancing without centralized controller.
Other TE Approaches
| Approach | Mechanism |
|---|---|
| Hedera | Centralized; detects elephant flows, reroutes via OpenFlow |
| DRILL | Per-packet load balancing using local queue depths |
| LetFlow | Flowlet-based random load balancing (simple, effective) |
| HULA | Probe-based distributed TE using best-path tracking at each switch |
Network Telemetry
In-Band Network Telemetry (INT)
Switches embed telemetry metadata directly into data packets as they traverse the network.
Original Packet | INT Header | INT Metadata (per-hop) |
Per-hop metadata:
- Switch ID
- Ingress/egress port
- Queue occupancy
- Ingress/egress timestamp
- Queue congestion status
- Provides per-packet, per-hop visibility.
- Collected at sink node or telemetry collector.
- P4-programmable switches natively support INT.
gNMI / gRPC Network Management Interface
- Model-driven telemetry using YANG models.
- Streaming telemetry: switch pushes data at configured intervals (replaces SNMP polling).
- Supports dial-in (controller subscribes) and dial-out (device pushes).
- Significantly lower latency than SNMP for detecting failures.
Telemetry Pipeline
Switches → Streaming (gNMI/INT) → Collector → Time-series DB → Analysis/Dashboards
(e.g., Telegraf) (InfluxDB, (Grafana,
Prometheus) custom)
SmartNICs
SmartNICs offload network processing from the host CPU to the NIC hardware.
SmartNIC Architectures
| Type | Implementation | Example |
|---|---|---|
| FPGA-based | Programmable logic | Microsoft Azure SmartNIC (Catapult) |
| SoC-based | ARM cores + accelerators | NVIDIA BlueField, AMD Pensando |
| ASIC-based | Fixed-function offload | Mellanox ConnectX (partial) |
Offloaded Functions
- OVS offload: Virtual switch forwarding in hardware (tc-flower, OVS-DPDK).
- Encryption: IPsec, TLS offload.
- Storage: NVMe-oF target/initiator.
- Telemetry: Packet sampling, flow tracking.
- Security: Firewall rules, microsegmentation.
Infrastructure Processing Unit (IPU/DPU)
Trend toward treating SmartNICs as infrastructure processors that run a complete infrastructure OS, separating tenant workloads from infrastructure management:
Server:
Host CPU → Tenant VMs/containers (application workloads)
DPU/IPU → Infrastructure services (networking, storage, security)
DPDK (Data Plane Development Kit)
DPDK provides a set of libraries for fast packet processing in userspace, bypassing the kernel network stack.
Key Techniques
| Technique | Description |
|---|---|
| Kernel bypass | UIO/VFIO drivers map NIC directly to userspace |
| Poll-mode drivers | Busy-polling instead of interrupt-driven I/O |
| Hugepages | Reduce TLB misses for packet buffer memory |
| Core pinning | Dedicate CPU cores to packet processing |
| Lockless ring buffers | Efficient inter-core communication |
| Batch processing | Amortize per-packet overhead |
Performance
- Single core can process 10-40 Mpps (million packets per second) depending on packet size.
- Enables line-rate processing at 100 Gbps on commodity servers.
- Used in virtual switches (OVS-DPDK), NFV, load balancers, firewalls.
Alternatives to DPDK
| Framework | Approach |
|---|---|
| XDP (eXpress Data Path) | eBPF programs at NIC driver level in Linux |
| AF_XDP | Socket-based interface to XDP for userspace |
| io_uring | Async I/O framework with networking support |
| VPP (fd.io) | Vector packet processing framework |
XDP is increasingly preferred over DPDK for many use cases because it integrates with the Linux kernel ecosystem while still achieving near-DPDK performance for common operations.