Microkernels
Philosophy and Design Principles
A microkernel moves as much functionality as possible out of the kernel into user-space servers. The kernel retains only the minimal mechanisms required: address space management, thread scheduling, and inter-process communication (IPC). Everything else -- file systems, device drivers, networking stacks -- runs as isolated user-space processes.
Key tenets:
- Minimize the trusted computing base (TCB)
- Isolate faults: a crashed driver does not bring down the system
- Enforce the principle of least privilege at the architectural level
- Enable formal verification of the kernel itself
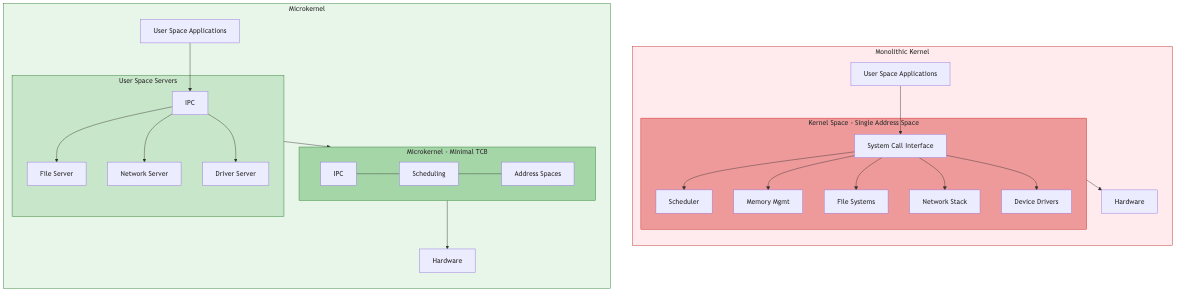
Monolithic vs. microkernel trade-off: Monolithic kernels (Linux, FreeBSD) achieve lower IPC overhead because subsystem calls stay in kernel space. Microkernels pay an IPC cost on every cross-domain call but gain fault isolation, modularity, and a verifiable core.
The L4 Family
L4 originated with Jochen Liedtke (1993), who demonstrated that IPC could be made fast enough to make microkernels practical. The key insight: hand-optimized IPC paths on the order of a few hundred cycles.
L4 Generations
| Generation | Example | Notable Feature |
|---|---|---|
| L4 v1 | Original L4 | x86 assembly, ultra-fast IPC |
| L4Ka | Pistachio | Portable C++ implementation |
| OKL4 | OKL4 Microvisor | Deployed in billions of modem chips |
| NOVA | NOVA microhypervisor | Capability-based, hypervisor focus |
| seL4 | seL4 | Formally verified, capability-based |
seL4: Formal Verification
seL4 is the world's first OS kernel with a machine-checked proof of functional correctness. The verification chain:
- Abstract specification -- Haskell model of desired behavior
- Executable specification -- Haskell prototype that can run
- C implementation -- High-performance C code
- Binary verification -- Proof that the compiled binary matches the C semantics
What is proven:
- The C implementation refines the abstract specification (no bugs, period)
- Integrity and confidentiality enforcement (information flow proofs)
- Worst-case execution time (WCET) bounds for all kernel operations
Capability security in seL4: Every object (thread, endpoint, address space, frame) is accessed via a capability -- an unforgeable token granting specific rights. Capabilities are stored in a capability derivation tree (CDT), enabling controlled delegation and revocation.
Capability structure:
cap = (object_ref, access_rights, badge)
CNode (capability node) holds capabilities in slots:
CNode[0] -> cap_to_TCB
CNode[1] -> cap_to_Endpoint
CNode[2] -> cap_to_Frame
Mach
Mach (Carnegie Mellon, 1985) introduced many microkernel concepts that persist today:
- Ports as the universal IPC abstraction (message queues with capabilities)
- External pagers -- virtual memory managed by user-space servers
- Copy-on-write memory for efficient fork and message passing
Mach became the basis for macOS/iOS (via the XNU hybrid kernel, which combines Mach IPC/VM with a BSD personality). Pure Mach suffered from IPC overhead; XNU collapses most calls into the kernel to recover performance.
QNX Neutrino
QNX is a commercial POSIX-compliant microkernel RTOS used in safety-critical domains:
- Automotive (instrument clusters, ADAS)
- Medical devices, industrial control, nuclear power plants
Architecture highlights:
- Message-passing IPC with priority inheritance built into the kernel
- Resource managers implement POSIX APIs (file systems, networking) in user space
- Adaptive partitioning scheduler guarantees CPU budgets per partition
- Certified to IEC 62304 (medical), ISO 26262 (automotive)
MINIX 3
MINIX 3 (Andrew Tanenbaum) was designed for extreme reliability:
- Drivers run as isolated user-space processes (~3,000-5,000 lines each)
- A reincarnation server monitors drivers and restarts them on failure
- Self-healing: a crashed disk driver is restarted transparently
- The kernel is ~12,000 lines of C (compare Linux at ~30M+ lines)
MINIX 3 influenced Intel ME firmware -- every modern Intel CPU runs a MINIX-derived kernel in the Management Engine.
Fuchsia Zircon
Zircon is the microkernel powering Google's Fuchsia OS. Design choices:
- Object-capability model: all kernel resources accessed via handles (capabilities)
- Kernel objects: processes, threads, VMOs (virtual memory objects), channels, ports, fifos
- Channels: bidirectional message-passing with handle transfer
- No POSIX in kernel: POSIX compatibility provided by user-space libraries
- Component framework: applications are isolated components communicating via FIDL (Fuchsia Interface Definition Language)
Zircon IPC via channels:
zx_channel_create() -> (handle_a, handle_b)
zx_channel_write(handle_a, data, handles_to_transfer)
zx_channel_read(handle_b, &data, &received_handles)
IPC Mechanisms
IPC performance is the critical bottleneck in microkernel design.
Synchronous vs. Asynchronous IPC
| Type | Mechanism | Latency | Use Case |
|---|---|---|---|
| Synchronous | L4/seL4 call/reply | ~100-500 cycles | Short RPC-style calls |
| Asynchronous | Mach ports, Zircon channels | Higher | Decoupled communication |
| Notification | seL4 notifications | Very low | Signaling (no data) |
| Shared memory | Mapped pages + signal | Near-zero | Bulk data transfer |
Fast IPC Techniques
- Direct process switch: The kernel switches directly from caller to callee without going through the scheduler (L4 migrating threads model)
- Register-based transfer: Short messages passed in CPU registers, avoiding memory copies
- Lazy scheduling: Defer scheduler queue updates during IPC to reduce overhead
- UTCB (User Thread Control Block): Per-thread memory region for IPC buffers, avoiding kernel allocation
Kernel-Bypass Techniques
Modern systems increasingly move operations out of the kernel entirely:
- DPDK / SPDK: User-space networking and storage drivers that poll devices directly, bypassing kernel syscalls and interrupts
- io_uring: Shared submission/completion rings between user and kernel space, amortizing syscall overhead
- VFIO: User-space device access via IOMMU isolation, enabling safe direct hardware access
- virtio-user: Virtio devices operated from user space for VM networking
Relationship to Microkernels
Kernel bypass and microkernels share a philosophical ancestor: minimize the kernel's role in the data path. The difference is that kernel bypass keeps a monolithic kernel but routes around it for performance, while microkernels remove functionality from the kernel entirely.
Performance Comparison
| Metric | Monolithic (Linux) | Microkernel (seL4) | Hybrid (XNU) |
|---|---|---|---|
| Syscall overhead | ~100 ns | ~150-300 ns | ~200 ns |
| IPC round-trip | N/A (in-kernel) | ~200-600 ns | ~500 ns |
| Driver restart | System reboot | Transparent | Partial |
| Formal verification | Infeasible | Achieved | Infeasible |
| Lines of kernel code | ~30M | ~10K | ~500K |
Applications and Deployment
| Domain | System | Why Microkernel |
|---|---|---|
| Automotive ADAS | QNX | Safety certification, fault isolation |
| Secure phones | seL4 | Proven information flow isolation |
| IoT / embedded | Fuchsia | Updatable, sandboxed components |
| Cellular basebands | OKL4 | Isolation between modem and app processor |
| Research / education | MINIX 3 | Simplicity, self-healing demonstration |
Key Takeaways
- Microkernels trade IPC overhead for fault isolation and verifiability
- seL4 proves that a production kernel can be formally verified end-to-end
- Capability-based security (seL4, Zircon) provides fine-grained access control without ambient authority
- Modern IPC techniques (register transfer, direct switch) close much of the performance gap with monolithic kernels
- Kernel bypass represents a convergent evolution: even monolithic systems benefit from minimizing kernel involvement in fast paths