Context-Free Languages
Context-free languages (CFLs) are the second level of the Chomsky hierarchy. They capture the recursive structure of programming languages and are recognized by pushdown automata.
Context-Free Grammars (CFG)
A CFG G = (V, Σ, R, S) where:
- V: Non-terminal symbols
- Σ: Terminal symbols
- R: Production rules of the form A → γ where A ∈ V and γ ∈ (V ∪ Σ)*
- S: Start symbol
Example: Balanced Parentheses
S → (S) | SS | ε
Derivation of "(()())":
S ⇒ (S) ⇒ (SS) ⇒ ((S)S) ⇒ ((S)(S)) ⇒ (()()) ⇒ (()())
Example: Arithmetic Expressions
E → E + T | T
T → T * F | F
F → (E) | id | num
This grammar encodes operator precedence (* before +) and associativity (left) in its structure.
Derivations and Parse Trees
Leftmost and Rightmost Derivations
Leftmost: Always expand the leftmost non-terminal. Rightmost: Always expand the rightmost non-terminal.
For unambiguous grammars, the leftmost and rightmost derivations correspond to the same parse tree.
Parse Trees
A tree representation of a derivation:
- Root: Start symbol
- Internal nodes: Non-terminals
- Leaves: Terminals (reading left-to-right gives the derived string)
Expression: id + id * id
Parse tree (with precedence):
E
/ \
E + T
| / \
T T * F
| | |
F F id
| |
id id
Ambiguity
A grammar is ambiguous if some string has two or more distinct parse trees (equivalently, two distinct leftmost derivations).
Example: E → E + E | E * E | id. The string "id + id * id" has two parse trees (one with + at root, one with * at root), giving different evaluation orders.
Disambiguation techniques:
- Rewrite the grammar to encode precedence/associativity.
- Use disambiguation rules in the parser (shift/reduce preferences).
Inherently ambiguous languages: Some CFLs have no unambiguous grammar. Example: {aⁱbʲcᵏ | i=j or j=k}.
Normal Forms
Chomsky Normal Form (CNF)
Every production is either:
- A → BC (two non-terminals)
- A → a (single terminal)
- S → ε (only for start symbol, if ε ∈ L)
Every CFG can be converted to CNF (by eliminating ε-productions, unit productions, and long/mixed productions).
CNF is important for: CYK parsing algorithm (requires CNF input).
Greibach Normal Form (GNF)
Every production is: A → aα where a is a terminal and α is a (possibly empty) string of non-terminals.
Every CFG can be converted to GNF. Useful for proofs and for constructing PDAs.
Pushdown Automata (PDA)
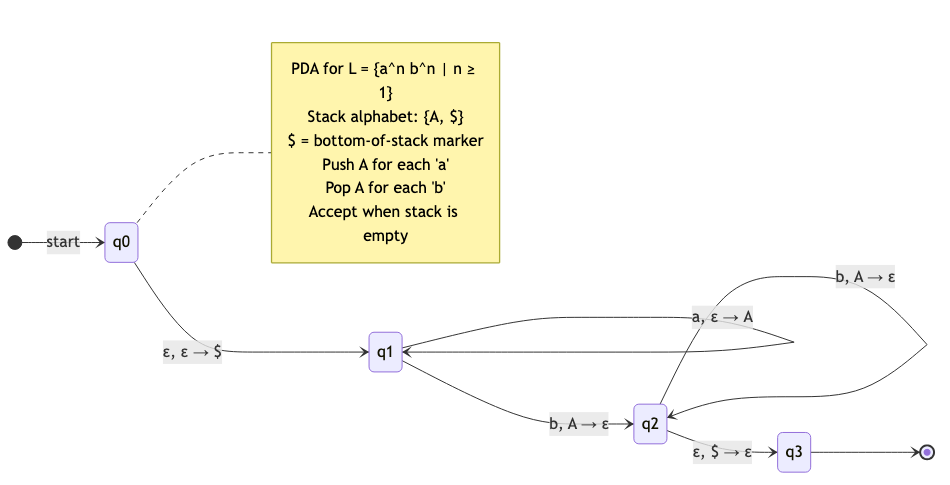
A PDA is an NFA augmented with a stack (infinite LIFO memory).
M = (Q, Σ, Γ, δ, q₀, Z₀, F) where:
- Γ: Stack alphabet
- Z₀: Initial stack symbol
- δ: Q × (Σ ∪ {ε}) × Γ → P(Q × Γ*)
Each transition: read an input symbol (or ε), pop a stack symbol, push zero or more stack symbols.
Example: {aⁿbⁿ | n ≥ 0}
States: {q₀, q₁, q_accept}
1. In q₀, reading 'a': Push A onto stack. Stay in q₀.
2. In q₀, reading 'b': Pop A from stack. Go to q₁.
3. In q₁, reading 'b': Pop A from stack. Stay in q₁.
4. In q₁, reading ε with empty stack: Go to q_accept.
Computation on "aabb":
(q₀, aabb, Z₀)
→ (q₀, abb, AZ₀) push A
→ (q₀, bb, AAZ₀) push A
→ (q₁, b, AZ₀) pop A, switch to q₁
→ (q₁, ε, Z₀) pop A
→ (q_accept, ε, Z₀) accept
Deterministic vs Nondeterministic PDA
DPDA: At each step, at most one transition applies. DCFLs ⊊ CFLs.
NPDA: Multiple transitions may apply; accepts if any path reaches acceptance. NPDAs recognize all CFLs.
Key difference from DFA/NFA: For finite automata, deterministic = nondeterministic (same power). For PDAs, nondeterministic is strictly more powerful than deterministic.
DCFLs: {aⁿbⁿ}, most programming language syntax, LR(1) languages. Inherently non-deterministic CFLs: {wwᴿ | w ∈ {a,b}*} (palindromes — need to guess the middle).
Equivalence: CFG ↔ PDA
Theorem: A language is context-free iff it is recognized by a PDA.
CFG → PDA: Top-down simulation. Push start symbol, match terminals with input, expand non-terminals using productions.
PDA → CFG: Construct grammar rules that simulate PDA transitions. Each non-terminal represents a state pair [qᵢ, qⱼ] (strings that take the PDA from qᵢ to qⱼ with the same stack height).
Pumping Lemma for CFLs
Theorem: If L is context-free, there exists a pumping length p such that for every w ∈ L with |w| ≥ p, there exist u, v, x, y, z with w = uvxyz satisfying:
- |vy| ≥ 1 (v and y aren't both empty)
- |vxy| ≤ p
- For all i ≥ 0: uvⁱxyⁱz ∈ L
Differences from regular pumping lemma: Two segments are pumped (v and y), and they must be pumped together at the same rate.
Example: {aⁿbⁿcⁿ | n ≥ 0} is Not Context-Free
Take w = aᵖbᵖcᵖ. By condition 2, |vxy| ≤ p, so vxy can contain at most two types of symbols. Pumping changes the count of those symbols but not the third. So uvⁱxyⁱz ∉ L for i ≠ 1. ∎
Closure Properties
| Operation | Closed? |
|---|---|
| Union | ✓ (S → S₁ | S₂) |
| Concatenation | ✓ (S → S₁S₂) |
| Kleene star | ✓ (S → SS₁ | ε) |
| Intersection | ✗ ({aⁿbⁿcⁿ} = {aⁿbⁿ} ∩ {bⁿcⁿ} shift) |
| Complement | ✗ (since intersection = complement of union of complements) |
| Intersection with regular | ✓ (product construction: PDA × DFA) |
| Reversal | ✓ |
| Homomorphism | ✓ |
CFLs are NOT closed under intersection or complement — a crucial difference from regular languages.
CYK Parsing Algorithm
Cocke-Younger-Kasami: Decides membership in O(n³) for any CFG (in CNF).
Dynamic programming: Fill a table T[i][j] = set of non-terminals that can derive the substring w[i..j].
For length l = 1 to n:
For start i = 0 to n-l:
j = i + l - 1
For split k = i to j-1:
If A → BC where B ∈ T[i][k] and C ∈ T[k+1][j]:
Add A to T[i][j]
Accept if S ∈ T[0][n-1]
Time: O(n³ × |G|). Space: O(n²).
Practical use: Not used for programming language parsers (too slow, O(n³)). Used for natural language parsing (where ambiguity is high and grammars are complex).
Earley Parsing
Handles any CFG (not just CNF) in O(n³) worst case, O(n²) for unambiguous grammars, and O(n) for LR grammars.
More practical than CYK. Used in NLP (e.g., NLTK).
Applications in CS
- Programming language syntax: Most programming language syntax is defined by context-free grammars.
- Parsers: Compilers use LR, LALR, LL parsers for CFGs (covered in compiler design).
- XML/HTML/JSON: Structured documents have context-free structure.
- Natural language processing: Phrase structure grammars, probabilistic CFGs for parsing sentences.
- Bioinformatics: Stochastic CFGs model RNA secondary structure.
- Security: Grammar-based fuzzing generates syntactically valid inputs.