Formal Languages
Formal language theory provides the mathematical framework for describing patterns in strings — the foundation of compilers, parsers, regular expressions, and computability theory.
Alphabets and Strings
Alphabet (Σ)
A finite, non-empty set of symbols.
Σ = {0, 1} — binary alphabet
Σ = {a, b, c, ..., z} — lowercase English
Σ = {0, 1, ..., 9} — decimal digits
Σ = ASCII — all ASCII characters
String (Word)
A finite sequence of symbols from Σ.
w = 0110 (string over {0, 1})
w = hello (string over {a-z})
Empty string: ε (or λ) — the string with zero symbols. |ε| = 0.
Length: |w| = number of symbols in w. |hello| = 5.
Concatenation: w₁w₂ — append w₂ to w₁. "ab" · "cd" = "abcd".
Power: wⁿ = w concatenated n times. (ab)³ = ababab. w⁰ = ε.
Reversal: wᴿ — reverse the string. (abc)ᴿ = cba.
Σ* and Σ⁺
Σ*: Set of all strings over Σ (including ε). Σ* = Σ⁰ ∪ Σ¹ ∪ Σ² ∪ ...
Σ⁺: All non-empty strings. Σ⁺ = Σ* \ {ε} = Σ¹ ∪ Σ² ∪ ...
For Σ = {0, 1}: Σ* = {ε, 0, 1, 00, 01, 10, 11, 000, 001, ...} — countably infinite.
Languages
A language L over alphabet Σ is any subset of Σ*.
L ⊆ Σ*
Examples:
- L = {ε} — language containing only the empty string
- L = ∅ — the empty language (no strings at all)
- L = {0ⁿ1ⁿ | n ≥ 0} = {ε, 01, 0011, 000111, ...}
- L = {w ∈ {0,1}* | w is a palindrome}
- L = {w ∈ {a-z}* | w is a valid English word}
- L = set of all syntactically valid Rust programs
Note: ∅ ≠ {ε}. The empty language has no strings. {ε} has one string (the empty string).
Operations on Languages
Set Operations
Since languages are sets of strings, all set operations apply:
- Union: L₁ ∪ L₂ = {w | w ∈ L₁ or w ∈ L₂}
- Intersection: L₁ ∩ L₂ = {w | w ∈ L₁ and w ∈ L₂}
- Difference: L₁ \ L₂ = {w | w ∈ L₁ and w ∉ L₂}
- Complement: L̄ = Σ* \ L = {w ∈ Σ* | w ∉ L}
Concatenation
L₁ · L₂ = {w₁w₂ | w₁ ∈ L₁, w₂ ∈ L₂}
Example: L₁ = {a, ab}, L₂ = {c, cd}. L₁ · L₂ = {ac, acd, abc, abcd}.
Properties:
- L · {ε} = {ε} · L = L
- L · ∅ = ∅ · L = ∅
- Not commutative in general
Kleene Star (Closure)
L* = L⁰ ∪ L¹ ∪ L² ∪ L³ ∪ ... = {ε} ∪ L ∪ LL ∪ LLL ∪ ...
Zero or more concatenations of strings from L.
Example: L = {ab}. L* = {ε, ab, abab, ababab, ...}.
Kleene plus: L⁺ = L · L* = L* \ {ε} (one or more).
Properties:
- ∅* = {ε}
- {ε}* = {ε}
- (L*)* = L*
- L* = {ε} ∪ L · L*
Reversal
Lᴿ = {wᴿ | w ∈ L}
Homomorphism
A function h: Σ → Δ* mapping each symbol to a string. Extended to strings: h(a₁a₂...aₙ) = h(a₁)h(a₂)...h(aₙ).
Example: h(0) = ab, h(1) = ε. Then h(010) = abab.
Chomsky Hierarchy
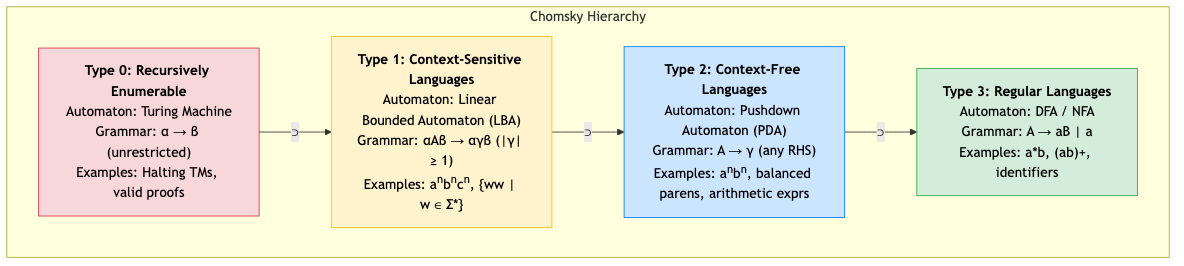
The Chomsky hierarchy classifies grammars and languages into four types based on the form of their production rules.
Type 0: Recursively Enumerable (Turing machines)
⊃
Type 1: Context-Sensitive (Linear bounded automata)
⊃
Type 2: Context-Free (Pushdown automata)
⊃
Type 3: Regular (Finite automata)
| Type | Grammar | Automaton | Example |
|---|---|---|---|
| 3 (Regular) | A → aB or A → a | DFA/NFA | a*b+ |
| 2 (Context-Free) | A → γ (any string of terminals/nonterminals) | PDA | {aⁿbⁿ} |
| 1 (Context-Sensitive) | αAβ → αγβ (|LHS| ≤ |RHS|) | LBA | {aⁿbⁿcⁿ} |
| 0 (Unrestricted) | Any production | Turing machine | Halting problem complement |
Each level strictly contains the levels below it.
Why This Matters for CS
| Language Class | Application |
|---|---|
| Regular | Lexical analysis (tokenization), pattern matching (regex), protocol validation |
| Context-free | Syntax analysis (parsing), programming language grammars, XML/JSON/HTML |
| Context-sensitive | Natural language (some aspects), type checking |
| Recursively enumerable | General computation, program verification |
Grammars
A grammar G = (V, Σ, R, S) consists of:
- V: Set of non-terminal symbols (variables)
- Σ: Set of terminal symbols (alphabet)
- R: Set of production rules (rewriting rules)
- S: Start symbol (S ∈ V)
Derivation
Apply production rules to transform strings.
Grammar:
S → aSb | ε
Derivation of "aabb":
S ⇒ aSb ⇒ aaSbb ⇒ aabb (replaced S → ε at last step)
Leftmost derivation: Always expand the leftmost non-terminal. Rightmost derivation: Always expand the rightmost non-terminal.
The language generated by G: L(G) = {w ∈ Σ* | S ⇒* w} (all terminal strings derivable from S).
Decision Problems
| Problem | Regular | Context-Free | Context-Sensitive | RE |
|---|---|---|---|---|
| Membership (w ∈ L?) | O(n) | O(n³) (CYK) | Decidable | Undecidable |
| Emptiness (L = ∅?) | Decidable | Decidable | Undecidable | Undecidable |
| Equivalence (L₁ = L₂?) | Decidable | Undecidable | Undecidable | Undecidable |
| Containment (L₁ ⊆ L₂?) | Decidable | Undecidable | Undecidable | Undecidable |
Applications in CS
- Compilers: Lexical analysis (regular), parsing (context-free), semantic analysis (context-sensitive aspects).
- Text processing: Regular expressions for search, validation, extraction.
- Protocol specification: Formal grammars describe message formats and state machines.
- Natural language processing: Context-free grammars for syntax, context-sensitive for agreement and scoping.
- Bioinformatics: Stochastic context-free grammars for RNA secondary structure prediction.
- Security: Input validation, protocol conformance checking.
- Verification: Model checking temporal properties expressed as automata.