Memory Hierarchy
The memory hierarchy bridges the speed gap between fast processors and slow main memory by exploiting locality — the tendency of programs to access nearby data (spatial) and recently accessed data (temporal).
Locality
Temporal Locality
Recently accessed data is likely to be accessed again soon.
Examples: Loop variables, function local variables, stack top, recently called functions, hot database rows.
Spatial Locality
Data near recently accessed data is likely to be accessed soon.
Examples: Sequential array traversal, instruction fetch (sequential execution), struct/object fields, matrix rows.
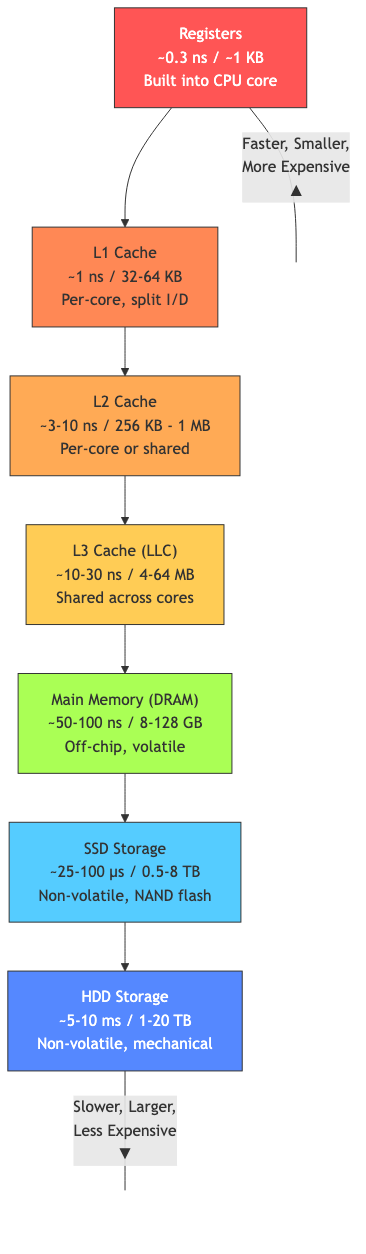
The Memory Wall
Processor speed has improved ~1000× faster than memory latency:
- CPU: ~0.3 ns per operation (3+ GHz)
- DRAM: ~50-100 ns access time
Without caches, the processor would spend >99% of its time waiting for memory.
Cache Organization
A cache is a small, fast memory that stores copies of frequently accessed data.
Cache Structure
┌──────┬──────────┬─────────────────────────────────┐
│ Valid │ Tag │ Data Block │
│ bit │ │ (multiple bytes/words) │
├──────┼──────────┼─────────────────────────────────┤
│ 1 │ 0x1A3F │ data data data data data data │
│ 1 │ 0x0B72 │ data data data data data data │
│ 0 │ — │ (invalid) │
│ ... │ ... │ ... │
└──────┴──────────┴─────────────────────────────────┘
Address Decomposition
For a cache with 2ˢ sets, block size of 2ᵇ bytes:
Address: [ Tag | Index (s bits) | Offset (b bits) ]
- Offset: Which byte within the block (b = log₂(block size))
- Index: Which set to look in (s = log₂(number of sets))
- Tag: Identifies the specific block within the set
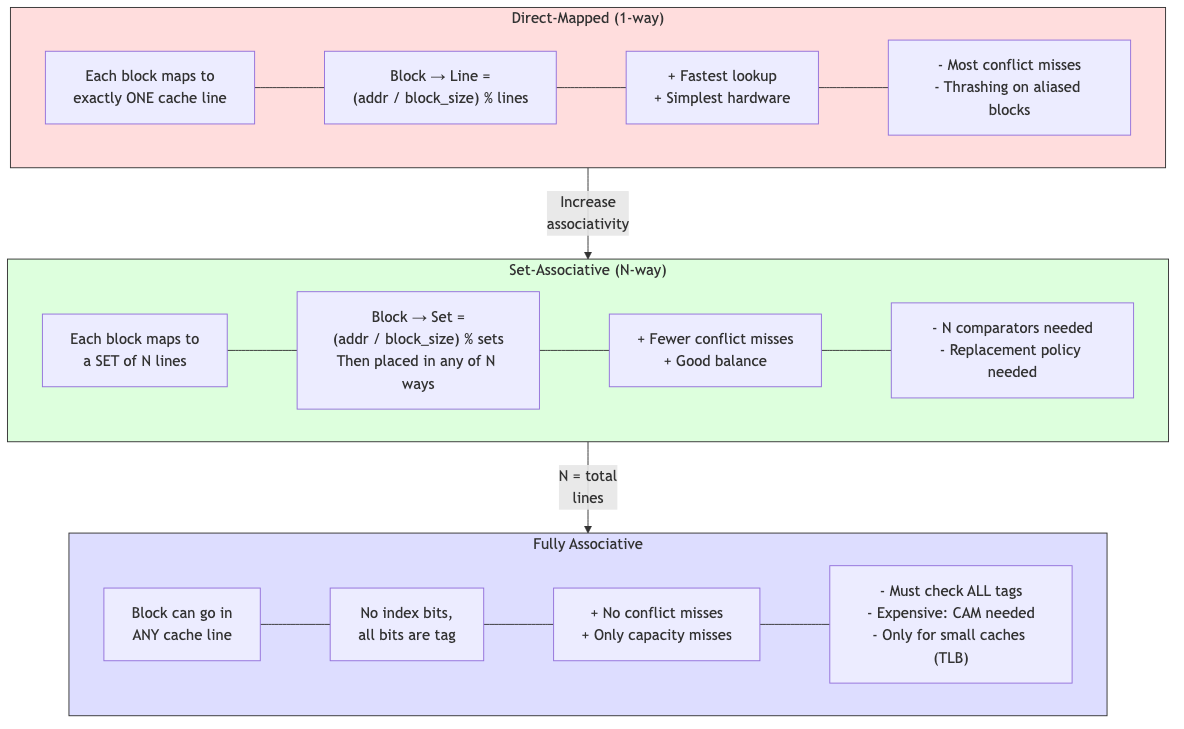
Cache Types
Direct-Mapped (1-way)
Each memory block maps to exactly one cache line.
Cache line = (address / block_size) % num_lines
Advantages: Simplest, fastest lookup (one comparison). Disadvantages: Conflict misses — two blocks mapping to the same line evict each other.
Example conflict: Arrays A and B both have elements that map to the same cache line. Accessing them alternately causes thrashing.
Set-Associative (N-way)
Each memory block can go into any of N lines within a set.
Set = (address / block_size) % num_sets
Block can be in any of the N ways within the set
- 2-way: Each set has 2 lines. Check both tags in parallel.
- 4-way: Each set has 4 lines. Common in L1 caches.
- 8-way: Common in L2/L3 caches.
Tradeoff: Higher associativity → fewer conflict misses but slower (more comparators) and more power.
Fully Associative
A block can go anywhere in the cache. Must check all tags (expensive). Used only for very small caches (TLBs, victim caches).
Cache Replacement Policies
When a set is full and a new block arrives, which block to evict?
LRU (Least Recently Used)
Evict the block that hasn't been used for the longest time.
Implementation: Track access order. For 2-way: 1 bit. For 4-way: 6 bits (pseudo-LRU is common). For 8+ way: true LRU is expensive → use approximations.
FIFO (First In, First Out)
Evict the oldest block. Simpler than LRU but can evict frequently used blocks.
Random
Evict a random block. Surprisingly competitive with LRU for high associativity. Very simple hardware.
Pseudo-LRU (Tree-PLRU)
Binary tree of bits. Each bit points toward the LRU side. On access, point bits away from the accessed way. Approximates LRU with much less hardware.
Optimal (Bélády's)
Evict the block that won't be used for the longest time in the future. Impossible to implement (requires future knowledge). Used as a theoretical upper bound for comparison.
Write Policies
Write Hit
Write-through: Write to both cache and memory immediately.
- Simpler. Memory always up-to-date.
- High memory traffic (every write goes to memory).
- Often combined with a write buffer to hide latency.
Write-back: Write only to cache. Mark line as dirty. Write to memory only when evicted.
- Less memory traffic (only dirty lines written back).
- More complex (dirty bit tracking, write-back on eviction).
- Dominant in modern processors.
Write Miss
Write-allocate: Fetch the block into cache, then write. Exploits spatial locality (future writes likely nearby).
No-write-allocate (write-around): Write directly to memory without fetching into cache.
Common pairings:
- Write-back + write-allocate (most common — modern caches)
- Write-through + no-write-allocate
Cache Performance
Miss Rate
Miss rate = Cache misses / Total accesses
Hit rate = 1 - Miss rate
Typical L1 miss rates: 2-5% (data), <1% (instruction).
Three Cs of Cache Misses
Compulsory (cold) misses: First access to a block. Cannot be avoided (except prefetching).
Capacity misses: Cache is too small to hold all needed data. Reduce by increasing cache size.
Conflict misses: Multiple blocks compete for the same set. Reduce by increasing associativity.
(Fourth C: Coherence misses in multiprocessor systems.)
Average Memory Access Time (AMAT)
AMAT = Hit time + Miss rate × Miss penalty
For a multi-level cache:
AMAT = L1_hit_time + L1_miss_rate × (L2_hit_time + L2_miss_rate × L2_miss_penalty)
Example
L1: 1 cycle hit, 5% miss rate. L2: 10 cycles hit, 1% miss rate (of accesses that reach L2 → local miss rate 20%). Main memory: 100 cycles.
AMAT = 1 + 0.05 × (10 + 0.20 × 100) = 1 + 0.05 × 30 = 2.5 cycles
Without caches: AMAT = 100 cycles. 40× improvement.
Cache Hierarchy
Modern processors have 2-3 levels:
| Level | Size | Latency | Associativity | Shared? |
|---|---|---|---|---|
| L1I (instruction) | 32-64 KB | 1-4 cycles | 4-8 way | Per core |
| L1D (data) | 32-64 KB | 1-4 cycles | 4-8 way | Per core |
| L2 | 256 KB - 1 MB | 10-15 cycles | 8-16 way | Per core |
| L3 | 4-64 MB | 30-50 cycles | 12-20 way | Shared |
| Main memory (DRAM) | 8-256 GB | 100-200 cycles | N/A | Shared |
Inclusion Policies
Inclusive: L2 contains a copy of everything in L1. Eviction from L2 → back-invalidate L1. Simplifies coherence.
Exclusive: Data is in either L1 or L2, not both. Effective capacity = L1 + L2. Used by AMD.
Non-inclusive non-exclusive (NINE): No strict policy. L2 doesn't track L1 contents. Used by some Intel designs.
Cache Optimization Techniques
Hardware
- Prefetching: Predict and fetch blocks before they're needed (hardware stream prefetcher, stride prefetcher).
- Victim cache: Small fully-associative cache for recently evicted lines. Catches conflict misses.
- Multi-banked cache: Multiple banks accessed in parallel for higher bandwidth.
- Non-blocking cache: Allows hits during a miss (miss-under-miss, hit-under-miss). Uses MSHRs (Miss Status Holding Registers).
Software
- Loop tiling/blocking: Process data in cache-sized blocks.
- Data structure layout: Prefer arrays of structs vs structs of arrays depending on access pattern.
- Prefetch instructions: Software-initiated prefetch (
__builtin_prefetchin GCC/Clang,_mm_prefetchfor SSE). - Cache-oblivious algorithms: Work well regardless of cache size (e.g., funnel sort, cache-oblivious matrix multiply).
Cache Coherence Introduction
In multiprocessor systems, multiple caches may have copies of the same memory location. When one processor writes, other caches' copies become stale.
Coherence protocols ensure all processors see a consistent view of memory. Covered in detail in the multiprocessor file.
Applications in CS
- Performance optimization: Understanding cache behavior is essential for writing fast code. Cache-friendly access patterns can give 10-100× speedups.
- Data structure design: Cache-aware data structures (B-trees for disks, cache-oblivious structures, packed arrays vs linked lists).
- Algorithm design: Tiling matrix multiplication, merge sort vs quicksort (locality differences), hash table design (open addressing vs chaining).
- Database systems: Buffer pool management is analogous to cache management. Page replacement policies (LRU, clock, LRU-K).
- Operating systems: Page cache, file system caches, TLB management.
- Game development: Entity Component System (ECS) designed for cache locality. Data-oriented design.