Indexing
Indexes are auxiliary data structures that speed up data retrieval at the cost of additional storage and write overhead. Choosing the right indexes is one of the most impactful performance decisions.
Index Fundamentals
Without an index: full table scan — read every row to find matches. O(n).
With an index: index lookup — navigate the index structure to find matches. O(log n) for tree-based, O(1) for hash-based.
Cost Tradeoff
| Aspect | Without Index | With Index |
|---|---|---|
| Read (point query) | O(n) — full scan | O(log n) — index lookup |
| Read (range query) | O(n) — full scan | O(log n + k) — index scan |
| Write (INSERT) | O(1) — append | O(log n) — update index |
| Write (UPDATE) | O(n) find + O(1) modify | O(log n) find + O(log n) update index |
| Storage | Table only | Table + index structure |
Rule: Indexes help reads but hurt writes. Add indexes for frequently queried columns. Don't over-index.
Index Types
Clustered vs Non-Clustered
Clustered index: Table rows are physically stored in index order. Only one per table (the data IS the index leaf level). Range scans are very fast (sequential disk reads).
B+ tree leaf pages ARE the data pages:
[... | id=1,data | id=2,data | id=3,data | ...]
In InnoDB (MySQL), the primary key is always the clustered index.
Non-clustered (secondary) index: A separate structure pointing to the table rows. Multiple per table. Each leaf contains the indexed columns + a pointer (row ID or primary key) to the actual row.
Index leaf: [email="alice@..." → PK=1] [email="bob@..." → PK=2]
Then: look up PK=1 in the clustered index to get the full row.
Covering Index
An index that includes all columns needed by a query. The query can be answered entirely from the index without accessing the table (index-only scan).
CREATE INDEX idx_covering ON orders(customer_id, order_date, total);
-- This query uses only columns in the index:
SELECT order_date, total FROM orders WHERE customer_id = 42;
-- → Index-only scan! No table access needed.
INCLUDE clause (PostgreSQL): Add non-key columns to the index leaf without indexing them:
CREATE INDEX idx ON orders(customer_id) INCLUDE (order_date, total);
Composite (Multi-Column) Index
Index on multiple columns. Column order matters!
CREATE INDEX idx ON orders(customer_id, order_date);
Leftmost prefix rule: The index supports queries on:
customer_idalone ✓customer_idANDorder_date✓order_datealone ✗ (can't skip the first column)
Design guideline: Put the most selective (highest cardinality) column first. Put equality conditions before range conditions.
Partial Index
Index only a subset of rows matching a condition.
CREATE INDEX idx_active ON users(email) WHERE is_active = TRUE;
Benefits: Smaller index, faster updates (only indexed rows affected). Perfect for queries that always filter on the condition.
Functional Index
Index on the result of a function or expression.
CREATE INDEX idx_lower_email ON users(LOWER(email));
-- Now this query uses the index:
SELECT * FROM users WHERE LOWER(email) = 'alice@mail.com';
B-Tree Indexes
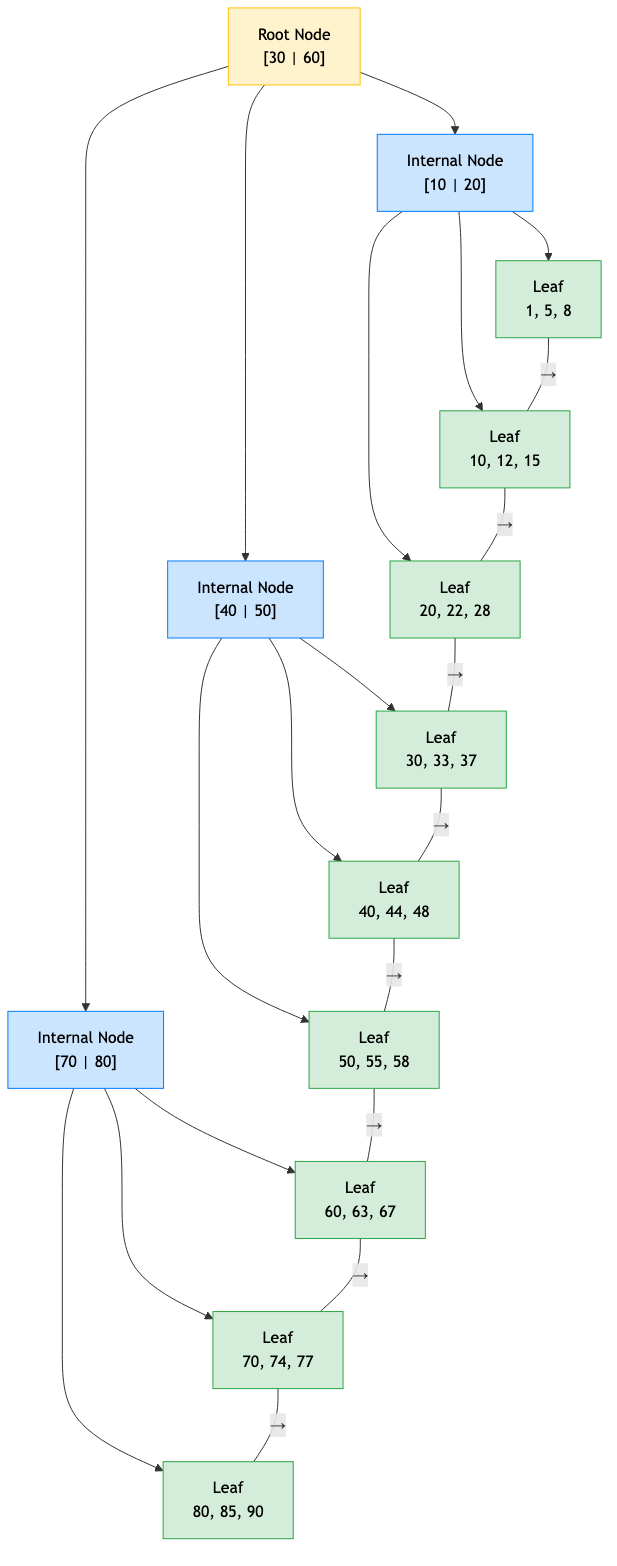
The default and most common index type. Covered in detail in the data structures B-tree file.
Supports: Equality (=), range (<, >, <=, >=, BETWEEN), prefix (LIKE 'abc%'), ORDER BY, MIN/MAX.
Does NOT support: Non-prefix patterns (LIKE '%abc'), functions (unless functional index).
Structure: B+ tree where leaf nodes form a doubly-linked list for efficient range scans.
Hash Indexes
Hash table mapping key → row pointer.
Supports: Equality (=) only. O(1) average lookup.
Does NOT support: Range queries, ordering, partial matching.
Use case: Exact-match lookups (e.g., hash join build side, in-memory hash indexes).
PostgreSQL: Supports hash indexes but B-tree is almost always better (hash indexes don't support WAL crash recovery before PG10, and range queries are common).
Bitmap Indexes
A bit vector for each distinct value. Bit i = 1 if row i has that value.
Color index:
Red: 10010100...
Blue: 01000011...
Green: 00101000...
Queries: AND/OR/NOT operations on bitmaps are very fast (bitwise operations).
Best for: Low-cardinality columns (gender, status, color) in read-heavy OLAP workloads. Terrible for OLTP (every row insert/update modifies the bitmap).
GiST (Generalized Search Tree)
Framework for building custom index types. Supports:
- Geometric data (containment, overlap, nearest-neighbor)
- Full-text search
- Range types
- IP addresses
PostgreSQL: GiST indexes for PostGIS (spatial), ltree (hierarchical labels), pg_trgm (trigram similarity).
GIN (Generalized Inverted Index)
Inverted index: maps each element to the set of rows containing it.
Best for: Multi-valued columns (arrays, JSON, full-text search).
CREATE INDEX idx_tags ON articles USING GIN(tags);
SELECT * FROM articles WHERE tags @> ARRAY['rust', 'database'];
Full-text search:
CREATE INDEX idx_fts ON articles USING GIN(to_tsvector('english', body));
SELECT * FROM articles WHERE to_tsvector('english', body) @@ to_tsquery('database & optimization');
BRIN (Block Range Index)
Store min/max values for each block of consecutive pages.
Very small: One entry per block range (e.g., 128 pages). Fraction of the size of a B-tree index.
Best for: Naturally ordered data (timestamps in append-only tables, auto-increment IDs). If the physical order correlates with the indexed column, BRIN can skip entire blocks.
CREATE INDEX idx_brin ON events USING BRIN(created_at);
Full-Text Indexes
Inverted Index
Maps each word to the list of documents containing it.
"database" → [doc1, doc3, doc7]
"index" → [doc1, doc2, doc5, doc7]
"query" → [doc2, doc3]
Query: "database AND index" → intersect posting lists → [doc1, doc7].
TF-IDF
Term Frequency × Inverse Document Frequency: Measure how important a word is to a document within a corpus.
TF(t, d) = count(t in d) / total_words(d)
IDF(t) = log(N / documents_containing(t))
TF-IDF(t, d) = TF × IDF
High TF-IDF → word is frequent in this document but rare overall → more relevant.
BM25
Modern replacement for TF-IDF. Better handling of document length and term frequency saturation.
BM25(t, d) = IDF(t) × (TF(t,d) × (k₁ + 1)) / (TF(t,d) + k₁ × (1 - b + b × |d|/avgdl))
Typical: k₁ = 1.2, b = 0.75. Used by Elasticsearch, PostgreSQL full-text search, Lucene.
Spatial Indexes
R-Tree
Tree of minimum bounding rectangles (MBRs). Efficient for spatial range queries and nearest-neighbor.
-- PostGIS
CREATE INDEX idx_geom ON places USING GIST(geom);
SELECT * FROM places WHERE ST_Contains(boundary, point);
SELECT * FROM places ORDER BY geom <-> point LIMIT 5; -- nearest 5
Quadtree
Recursively subdivide 2D space into quadrants. Simpler than R-tree but less balanced.
Index Selection and Optimization
When to Create Indexes
- Columns in WHERE clauses (especially selective predicates)
- Columns in JOIN conditions (foreign keys)
- Columns in ORDER BY / GROUP BY
- Columns with high selectivity (many distinct values)
When NOT to Create Indexes
- Small tables (full scan is fast enough)
- Columns with low selectivity (boolean, status with few values — unless bitmap)
- Frequently updated columns (index maintenance cost)
- Columns rarely used in queries
Index Maintenance Cost
Every INSERT, UPDATE, DELETE must update all affected indexes.
Write amplification: A table with 5 indexes requires ~6× the write work (1 table write + 5 index updates).
Bloat: Deleted entries leave dead space in B-tree pages. Periodic REINDEX or VACUUM (PostgreSQL) reclaims space.
Monitoring
-- PostgreSQL: check index usage
SELECT indexrelname, idx_scan, idx_tup_read, idx_tup_fetch
FROM pg_stat_user_indexes ORDER BY idx_scan;
-- Unused indexes (idx_scan = 0 after sufficient time) → consider dropping
Applications in CS
- Query performance: The #1 tool for improving query speed. EXPLAIN ANALYZE reveals whether indexes are used.
- Database administration: Index creation, monitoring, maintenance (rebuild, vacuum).
- Search engines: Inverted indexes with BM25 ranking. Elasticsearch, Lucene, Meilisearch.
- Geospatial: Spatial indexes (R-tree/GiST) for location-based queries.
- Full-text search: GIN indexes with tsvector/tsquery in PostgreSQL. Or dedicated search engines.