Normalization
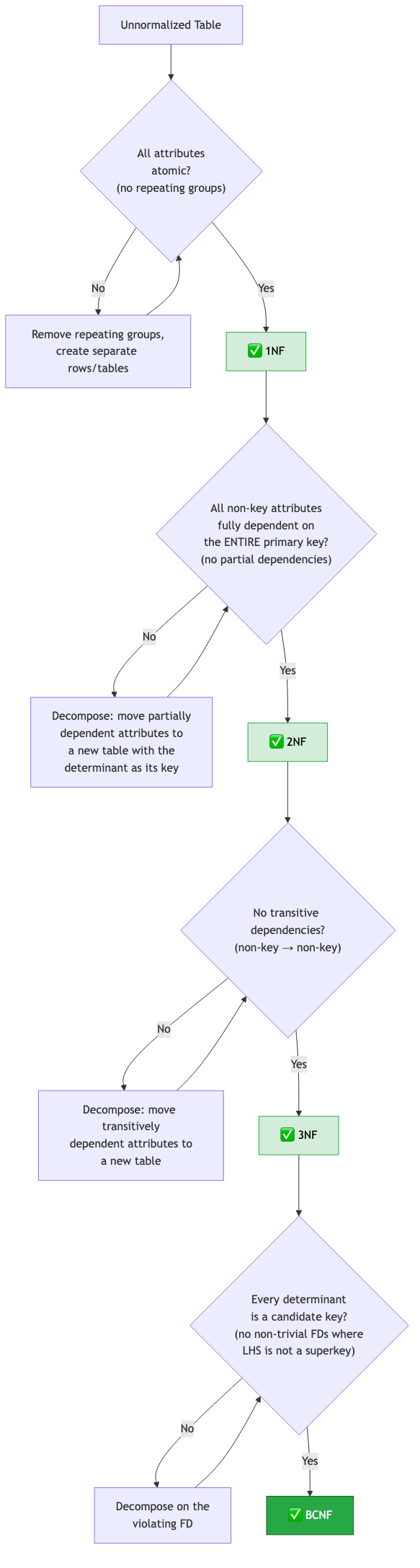
Normalization eliminates data redundancy and update anomalies by decomposing tables into well-structured forms. Each normal form imposes stricter constraints.
Why Normalize?
Update Anomalies
Without normalization, redundant data causes problems:
StudentCourses(student_id, student_name, course_id, course_name, instructor)
| sid | name | cid | course | instructor |
|-----|-------|------|----------|------------|
| 1 | Alice | CS50 | Intro CS | Dr. Smith |
| 1 | Alice | CS51 | Data Str | Dr. Jones |
| 2 | Bob | CS50 | Intro CS | Dr. Smith |
Insertion anomaly: Can't add a course without a student enrolled.
Deletion anomaly: Deleting Bob's enrollment loses the fact that CS50 is taught by Dr. Smith (if Bob is the last student).
Update anomaly: If Dr. Smith changes, must update every row mentioning them. Miss one → inconsistency.
Solution: Decompose into Students, Courses, and Enrollments tables.
First Normal Form (1NF)
Rule: Every attribute contains only atomic (indivisible) values. No repeating groups, no sets, no nested tables.
Violation:
| student | courses |
|---------|-----------------|
| Alice | CS50, CS51 | ← multivalued!
| Bob | CS50 |
Fix: One row per student-course pair, or a separate Enrollments table.
Note: Modern databases support JSON, arrays, etc. — 1NF is about the relational model, not about what databases technically allow.
Second Normal Form (2NF)
Rule: 1NF + every non-key attribute is fully dependent on the entire primary key (no partial dependencies).
Only relevant for tables with composite primary keys.
Violation (PK = {student_id, course_id}):
Enrollments(student_id, course_id, student_name, grade)
student_name depends only on student_id, not on the full key → partial dependency.
Fix: Move student_name to a Students table.
Students(student_id, student_name)
Enrollments(student_id, course_id, grade)
Third Normal Form (3NF)
Rule: 2NF + no transitive dependencies (non-key attribute depending on another non-key attribute).
Formally: For every FD X → A, either X is a superkey OR A is part of a candidate key (prime attribute).
Violation:
Students(student_id, name, department_id, department_name)
student_id → department_id → department_name is transitive. department_name depends on department_id, not directly on student_id.
Fix:
Students(student_id, name, department_id)
Departments(department_id, department_name)
3NF Test
For every non-trivial FD X → Y in the relation:
- X is a superkey, OR
- Y is a prime attribute (part of some candidate key)
If both conditions fail for any FD → not in 3NF.
Boyce-Codd Normal Form (BCNF)
Rule: For every non-trivial FD X → Y, X must be a superkey.
Stricter than 3NF — removes the "Y is prime" exception.
3NF but not BCNF example:
CourseInstructor(student, course, instructor)
FDs: {student, course} → instructor
instructor → course (each instructor teaches one course)
Candidate keys: {student, course}, {student, instructor}
instructor → course: instructor is not a superkey → violates BCNF
But course is a prime attribute → satisfies 3NF
Fix: Decompose into:
Teaches(instructor, course)
Takes(student, instructor)
Trade-off: BCNF decomposition may not preserve all FDs (no dependency preservation guarantee). 3NF always preserves FDs.
Fourth Normal Form (4NF)
Rule: BCNF + no multi-valued dependencies (except those implied by superkeys).
Multi-valued dependency (MVD): X →→ Y means: for each X value, the set of Y values is independent of the other attributes.
Violation:
PersonSkillsLangs(person, skill, language)
| person | skill | language |
|--------|---------|----------|
| Alice | Python | English |
| Alice | Python | French |
| Alice | Rust | English |
| Alice | Rust | French |
person →→ skill and person →→ language (skills and languages are independent). Must store every combination → redundancy.
Fix:
PersonSkills(person, skill)
PersonLanguages(person, language)
Fifth Normal Form (5NF / PJNF)
Rule: 4NF + no join dependencies that aren't implied by candidate keys.
A join dependency means the table can be reconstructed by joining three or more of its projections.
Rarely encountered in practice. Most schemas are well-served by 3NF or BCNF.
Denormalization Tradeoffs
| Aspect | Normalized | Denormalized |
|---|---|---|
| Redundancy | None | Controlled redundancy |
| Update anomalies | None | Must manage manually |
| Storage | Less | More |
| Read performance | May need joins | Faster reads (pre-joined) |
| Write performance | Faster writes | Slower (update multiple copies) |
| Query complexity | More joins | Simpler queries |
Normalize by default. Denormalize for measured performance needs.
When to Denormalize
- Read-heavy OLAP workloads: Pre-compute aggregates, materialized views.
- Caching columns: Store computed values to avoid expensive joins.
- Embedding related data: Store frequently-accessed related data in the same row (in document databases, this is natural).
- Reporting tables: Flatten for simple reporting queries.
Lossless Join Decomposition
A decomposition is lossless if the original table can be reconstructed exactly by joining the decomposed tables.
Lossless condition (for binary decomposition R into R₁, R₂):
(R₁ ∩ R₂) → R₁ OR (R₁ ∩ R₂) → R₂
The common attributes must be a superkey of at least one of the decomposed tables.
BCNF decomposition is always lossless. But it may not preserve all FDs.
Dependency Preservation
A decomposition preserves dependencies if all original FDs can be checked within individual decomposed tables (without joins).
3NF decomposition can always be both lossless and dependency-preserving. BCNF decomposition may sacrifice dependency preservation.
Normalization Algorithm
3NF Synthesis Algorithm
- Find a canonical cover of FDs.
- For each FD X → A: create table (X, A).
- If no table contains a candidate key: add a table with a candidate key.
- Remove redundant tables (subset of another table's attributes).
Result: 3NF, lossless, dependency-preserving.
BCNF Decomposition Algorithm
- Find a non-trivial FD X → Y where X is not a superkey.
- Decompose R into R₁(XY) and R₂(R - Y + X).
- Repeat for each decomposed relation that violates BCNF.
Result: BCNF, lossless. May not preserve all FDs.
Practical Guidelines
- Start at 3NF: Sufficient for most OLTP applications.
- Use BCNF if possible: When dependency preservation isn't sacrificed.
- Don't over-normalize: 4NF/5NF are rarely needed. Understand when they apply.
- Denormalize intentionally: Measure first. Document the denormalization and its rationale.
- Use constraints: Even in denormalized schemas, enforce consistency with triggers, application code, or batch validation.
Applications in CS
- Schema design: Normalization provides a systematic approach to eliminating redundancy.
- Data migration: Normalizing legacy schemas is a common refactoring task.
- ETL: Extract-Transform-Load pipelines often denormalize during the "Load" phase (star schema for analytics).
- ORM design: ORMs work best with properly normalized schemas.
- Performance tuning: Understanding normal forms helps decide when denormalization is justified.