Machine Learning Foundations
Learning Paradigms
Supervised Learning
Learn a mapping f: X -> Y from labeled training data {(x_i, y_i)}.
- Classification: y is discrete (spam detection, image recognition)
- Regression: y is continuous (price prediction, temperature forecasting)
The goal is to minimize expected risk over the true data distribution:
R(f) = E_{(x,y)~P}[L(f(x), y)]
Since P is unknown, we minimize empirical risk over training data:
R_emp(f) = (1/n) * sum_{i=1}^{n} L(f(x_i), y_i)
Unsupervised Learning
Find structure in unlabeled data {x_i}. No target variable.
- Clustering: group similar points (K-means, DBSCAN)
- Dimensionality reduction: compress features (PCA, t-SNE)
- Density estimation: model P(x) (GMM, KDE)
- Anomaly detection: identify outliers (isolation forest)
Semi-Supervised Learning
Combine small labeled set with large unlabeled set. Relies on assumptions:
- Smoothness: nearby points share labels
- Cluster: points in the same cluster share labels
- Manifold: data lies on a lower-dimensional manifold
Examples: label propagation, self-training, MixMatch.
Self-Supervised Learning
Generate supervisory signal from the data itself. The model solves a pretext task to learn representations useful for downstream tasks.
- Contrastive: SimCLR, MoCo (learn similar/dissimilar pairs)
- Masked prediction: BERT (masked tokens), MAE (masked patches)
- Next-token prediction: GPT-style autoregressive pretraining
Reinforcement Learning
An agent interacts with an environment to maximize cumulative reward.
Agent -> Action a_t -> Environment -> (State s_{t+1}, Reward r_t) -> Agent
Key distinction: delayed rewards, exploration-exploitation tradeoff.
Bias-Variance Tradeoff
For a model trained on dataset D, predicting target y = f(x) + epsilon where epsilon ~ N(0, sigma^2):
E_D[(y - f_hat(x))^2] = Bias(f_hat(x))^2 + Var(f_hat(x)) + sigma^2
\_____________/ \____________/ \______/
underfitting overfitting irreducible
Where:
Bias(f_hat(x)) = E_D[f_hat(x)] - f(x) # systematic error
Var(f_hat(x)) = E_D[(f_hat(x) - E[f_hat(x)])^2] # sensitivity to training set
| Property | High Bias | High Variance |
|---|---|---|
| Model | Too simple | Too complex |
| Training error | High | Low |
| Test error | High | High |
| Fix | More features | More data, regularize |
Regularization controls complexity to navigate this tradeoff: L1, L2, dropout, early stopping, data augmentation.
Cross-Validation
K-Fold Cross-Validation
def k_fold_cv(data, model_class, k=5):
folds = split_into_k_folds(data, k)
scores = []
for i in range(k):
val_fold = folds[i]
train_folds = concatenate(folds[:i] + folds[i+1:])
model = model_class.fit(train_folds)
scores.append(evaluate(model, val_fold))
return mean(scores), std(scores)
Variants
| Method | Use Case |
|---|---|
| Hold-out | Large datasets, quick iteration |
| K-Fold (k=5,10) | Standard practice |
| Stratified K-Fold | Imbalanced classification |
| Leave-One-Out (LOO) | Very small datasets (high variance) |
| Time-Series Split | Temporal data (no future leakage) |
| Group K-Fold | Grouped data (e.g., patients) |
Nested Cross-Validation
Outer loop evaluates model performance; inner loop tunes hyperparameters. Prevents optimistic bias from tuning on the test fold.
For each outer fold:
For each inner fold:
Tune hyperparameters
Train with best hyperparams on outer train set
Evaluate on outer test fold
Evaluation Metrics
Classification Metrics
From the confusion matrix (TP, FP, TN, FN):
Accuracy = (TP + TN) / (TP + TN + FP + FN)
Precision = TP / (TP + FP) # of predicted positives, how many correct?
Recall = TP / (TP + FN) # of actual positives, how many found?
F1 = 2 * P * R / (P + R) # harmonic mean of precision and recall
F_beta = (1 + beta^2) * P * R / (beta^2 * P + R)
When to use what:
- Accuracy: balanced classes only
- Precision: cost of false positives is high (spam filter)
- Recall: cost of false negatives is high (cancer screening)
- F1: balanced tradeoff between precision and recall
ROC and AUC
ROC curve plots TPR (recall) vs FPR (= FP / (FP + TN)) at varying thresholds.
- AUC = 1.0: perfect classifier
- AUC = 0.5: random guessing
- AUC is threshold-independent and invariant to class imbalance
Precision-Recall curve: preferred when classes are heavily imbalanced (use AUPRC instead of AUROC).
Regression Metrics
MSE = (1/n) * sum(y_i - y_hat_i)^2 # penalizes large errors
RMSE = sqrt(MSE) # same units as y
MAE = (1/n) * sum|y_i - y_hat_i| # robust to outliers
R^2 = 1 - SS_res / SS_tot # proportion of variance explained
MAPE = (1/n) * sum|y_i - y_hat_i| / |y_i| # percentage error
Multi-Class Extensions
- Macro-average: compute metric per class, take mean (treats all classes equally)
- Micro-average: aggregate TP/FP/FN globally, then compute (biased toward frequent classes)
- Weighted: macro weighted by class support
The No Free Lunch Theorem
Theorem (Wolpert, 1996): Averaged over all possible data-generating distributions, no learning algorithm is universally better than any other.
Implications:
- There is no single "best" algorithm -- domain knowledge matters
- Assumptions about the data distribution are necessary and inescapable
- An algorithm that excels on one problem class must perform worse on another
- Model selection (cross-validation, domain expertise) is essential
This does NOT mean all algorithms are equal in practice. Real-world distributions are not uniform -- structured data has patterns that certain algorithms exploit better than others.
PAC Learning Framework
A concept class C is PAC-learnable if there exists an algorithm A such that for any epsilon > 0, delta > 0, and distribution D over X:
P[error(h) <= epsilon] >= 1 - delta
using a number of samples polynomial in 1/epsilon, 1/delta, and problem size.
Sample complexity for finite hypothesis class H:
m >= (1/epsilon) * (ln|H| + ln(1/delta))
This formalizes how much data is needed for reliable generalization.
VC Dimension
The VC dimension of a hypothesis class H is the largest set of points that H can shatter (classify in all 2^n possible ways).
- Linear classifier in R^d: VC dim = d + 1
- Higher VC dim means more expressive but needs more data
- Generalization bound: with probability 1 - delta:
R(f) <= R_emp(f) + O(sqrt((VC(H) * ln(n) + ln(1/delta)) / n))
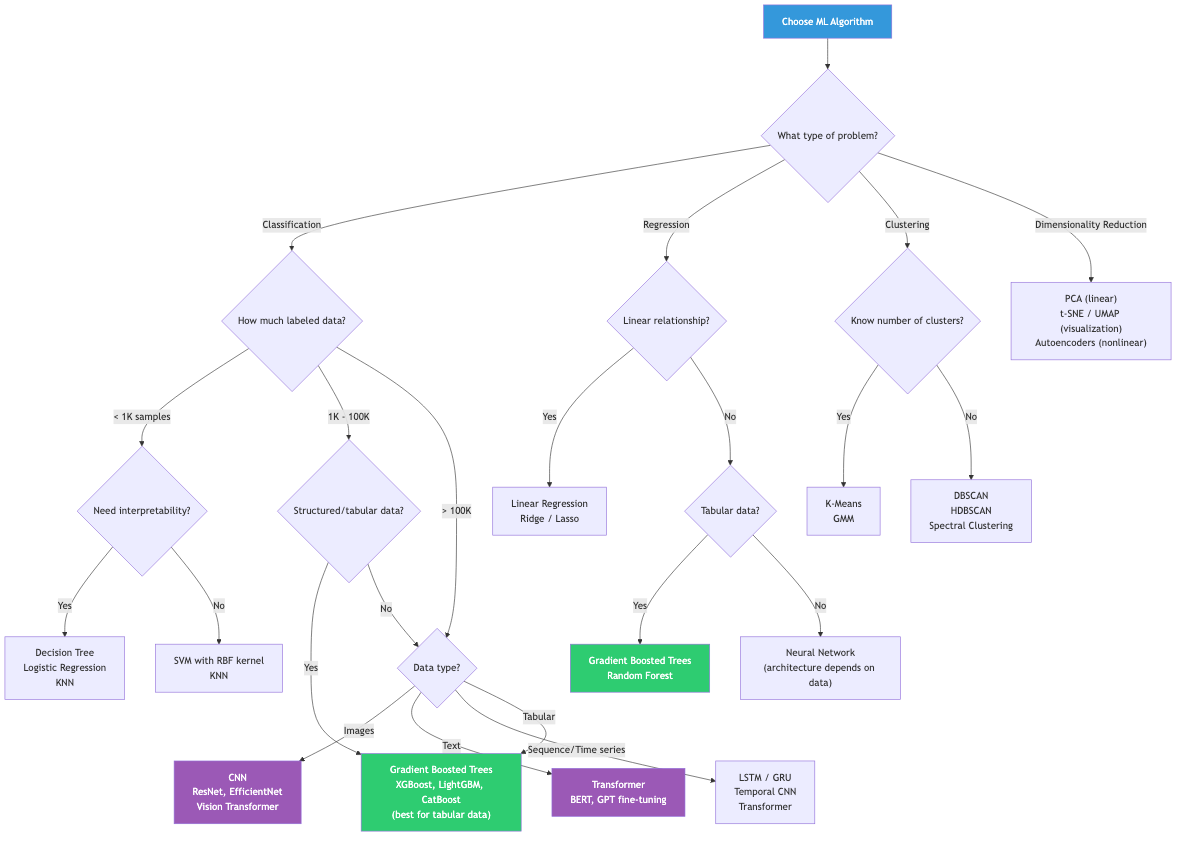
Practical Checklist
- Define the problem: classification, regression, ranking, generation?
- Collect and explore data: distributions, missing values, class balance
- Establish a baseline: simple model (majority class, linear regression)
- Feature engineering: domain knowledge, transformations
- Model selection: cross-validation, appropriate metrics
- Hyperparameter tuning: random/Bayesian search with nested CV
- Error analysis: where does the model fail? Bias or variance?
- Iterate: better features, more data, different architecture