Practical Machine Learning
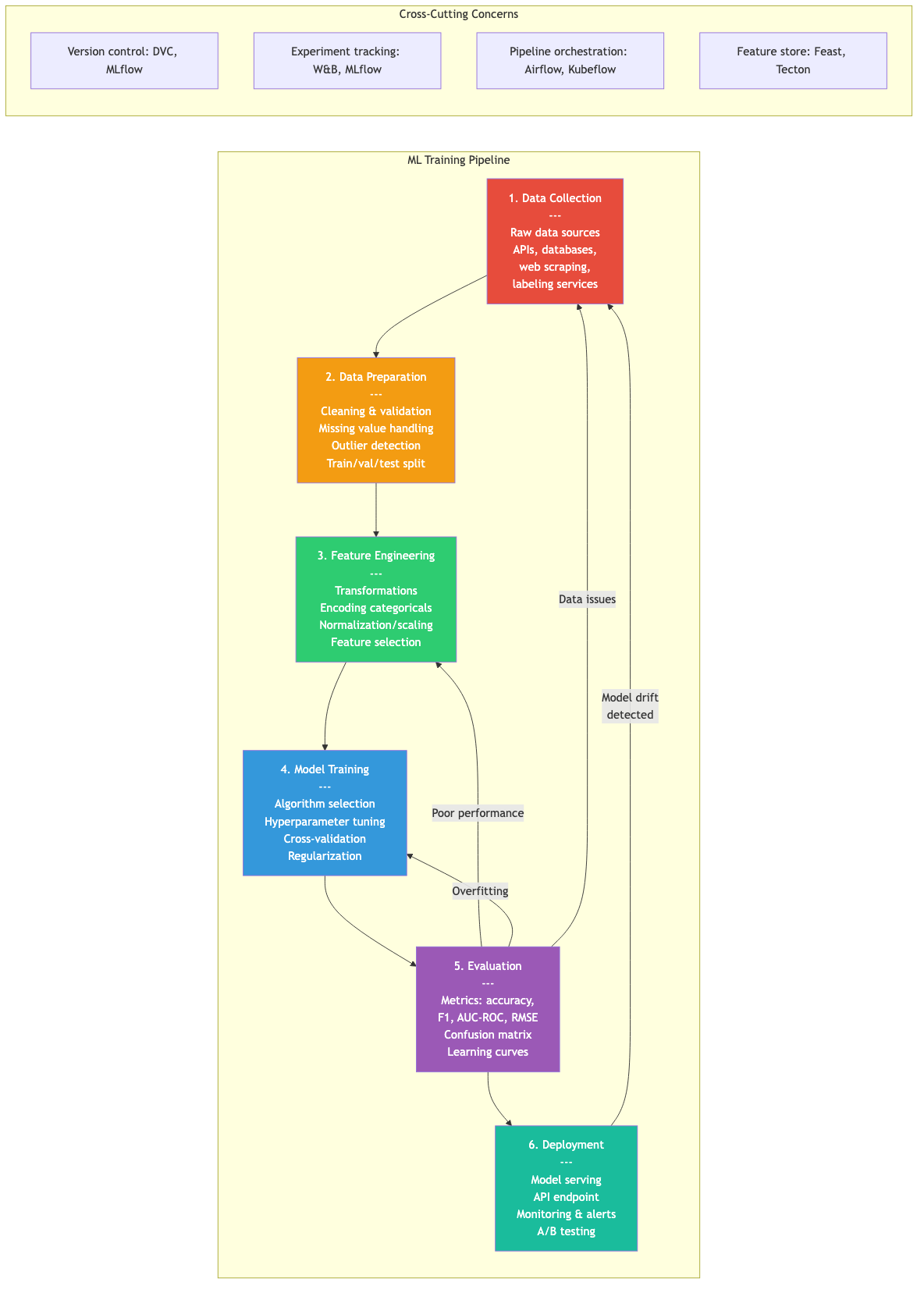
Feature Engineering
Transform raw data into features that better represent the underlying problem.
Common Transformations
| Technique | Description | Example |
|---|---|---|
| Binning | Discretize continuous features | Age -> age groups |
| Log transform | Reduce skewness | log(1 + income) |
| Polynomial | Capture non-linear relationships | x, x^2, x*y |
| Interaction | Combine features | price_per_sqft = price/area |
| Cyclical encoding | sin/cos for periodic features | hour -> sin(2pih/24) |
| Target encoding | Replace category with mean target | city -> avg_price_in_city |
| Frequency encoding | Replace category with its count | city -> count(city) |
| Date decomposition | Extract year, month, day, weekday, etc. | timestamp -> components |
def cyclical_encode(values, period):
"""Encode periodic features as sin/cos pair."""
return np.sin(2 * np.pi * values / period), np.cos(2 * np.pi * values / period)
def target_encode(train_df, col, target, smoothing=10):
"""Target encoding with smoothing to prevent overfitting."""
global_mean = train_df[target].mean()
agg = train_df.groupby(col)[target].agg(['mean', 'count'])
smooth = (agg['count'] * agg['mean'] + smoothing * global_mean) / (agg['count'] + smoothing)
return smooth
Text Features
- Bag of words / TF-IDF: sparse word count vectors
- Word embeddings: Word2Vec, GloVe, FastText (dense, semantic)
- Sentence embeddings: from pretrained transformers (BERT, Sentence-BERT)
Feature Selection
Remove irrelevant or redundant features to reduce overfitting and improve interpretability.
Filter Methods
Rank features independently of the model:
- Variance threshold: remove near-constant features
- Correlation: remove one of highly correlated pairs (|r| > 0.95)
- Mutual information: I(X; Y) measures non-linear dependency
- Chi-squared: for categorical features vs categorical target
- ANOVA F-test: for continuous features vs categorical target
Wrapper Methods
Use model performance to evaluate feature subsets:
- Forward selection: start empty, greedily add best feature
- Backward elimination: start with all, greedily remove worst
- Recursive Feature Elimination (RFE): train model, remove least important feature, repeat
Embedded Methods
Feature selection built into the model:
- Lasso (L1): drives coefficients to zero
- Tree-based importance: feature importance from random forests / gradient boosting
- Elastic net: combines L1 selection with L2 stability
Handling Missing Data
Strategies
| Method | When to Use | Implementation |
|---|---|---|
| Drop rows | Very few missing, MCAR | df.dropna() |
| Drop columns | >50% missing in a feature | df.drop(columns=[...]) |
| Mean/median/mode | Simple baseline, not too many missing | SimpleImputer |
| KNN imputation | Features are correlated | KNNImputer |
| Iterative (MICE) | Complex patterns | IterativeImputer |
| Indicator variable | Missingness is informative | Add is_missing column |
| Model-native | Tree methods handle missing natively | XGBoost, LightGBM |
Missing data types:
- MCAR (Missing Completely at Random): missingness unrelated to any data
- MAR (Missing at Random): missingness depends on observed data
- MNAR (Missing Not at Random): missingness depends on unobserved values
Handling Imbalanced Classes
When one class is much rarer (e.g., fraud detection: 99.9% non-fraud).
Data-Level Methods
| Method | Description |
|---|---|
| Random oversample | Duplicate minority samples |
| Random undersample | Remove majority samples |
| SMOTE | Generate synthetic minority samples via interpolation |
| ADASYN | Focus synthetic samples on harder examples |
| Tomek links | Remove ambiguous majority samples near boundary |
SMOTE (Synthetic Minority Over-sampling Technique):
def smote(X_minority, k=5, n_synthetic=100):
knn = NearestNeighbors(n_neighbors=k).fit(X_minority)
synthetic = []
for _ in range(n_synthetic):
idx = np.random.randint(len(X_minority))
x = X_minority[idx]
neighbors = knn.kneighbors([x], return_distance=False)[0]
nn = X_minority[np.random.choice(neighbors)]
# Interpolate between x and its neighbor
lam = np.random.random()
synthetic.append(x + lam * (nn - x))
return np.array(synthetic)
Algorithm-Level Methods
- Class weights: weight loss inversely proportional to class frequency
- Focal loss: down-weight easy examples: L = -alpha * (1-p)^gamma * log(p)
- Threshold adjustment: optimize decision threshold on validation set using PR curve
Evaluation for Imbalanced Data
Do NOT use accuracy. Use: precision, recall, F1, AUPRC, Matthews Correlation Coefficient (MCC).
Experiment Tracking
MLflow
import mlflow
with mlflow.start_run():
mlflow.log_param("lr", 0.001)
mlflow.log_param("epochs", 50)
for epoch in range(50):
train_loss = train_one_epoch(model, data)
val_acc = evaluate(model, val_data)
mlflow.log_metric("train_loss", train_loss, step=epoch)
mlflow.log_metric("val_acc", val_acc, step=epoch)
mlflow.log_artifact("model.pkl")
mlflow.sklearn.log_model(model, "model")
Weights & Biases (W&B)
import wandb
wandb.init(project="my-project", config={"lr": 0.001, "epochs": 50})
for epoch in range(50):
train_loss = train_one_epoch(model, data)
wandb.log({"train_loss": train_loss, "epoch": epoch})
wandb.finish()
Key capabilities: hyperparameter sweeps, artifact versioning, team collaboration, experiment comparison dashboards.
Model Serving
Deployment Patterns
| Pattern | Description | Latency | Use Case |
|---|---|---|---|
| Batch | Score entire dataset periodically | High | Recommendations |
| Real-time API | REST/gRPC endpoint | Low | Search ranking |
| Streaming | Score events as they arrive | Medium | Fraud detection |
| Edge | Run model on device | Lowest | Mobile, IoT |
Model Optimization for Serving
- Quantization: FP32 -> INT8 (2-4x speedup, minimal accuracy loss)
- Pruning: remove near-zero weights (structured or unstructured)
- Distillation: train small student model to mimic large teacher
- ONNX: standard format for cross-framework deployment
- TensorRT / OpenVINO: hardware-specific optimization
A/B Testing
Compare model versions in production with statistical rigor.
Process
- Define metric and minimum detectable effect (MDE)
- Calculate sample size: n = (z_{alpha/2} + z_beta)^2 * 2 * sigma^2 / MDE^2
- Randomly split traffic (e.g., 50/50 or 95/5 for risky changes)
- Run until sample size reached (do NOT peek and stop early without correction)
- Compute p-value or confidence interval
Pitfalls
- Peeking: checking results before planned sample size inflates false positive rate. Use sequential testing (SPRT) if early stopping is needed.
- Multiple comparisons: testing many metrics requires Bonferroni or FDR correction.
- Simpson's paradox: aggregate results can contradict subgroup results. Stratify analysis.
- Network effects: user interactions violate independence assumption.
Data Versioning
Track datasets alongside code for reproducibility.
- DVC (Data Version Control): git-like commands for data, stores large files externally (S3, GCS)
- Delta Lake / Lakehouse: versioned data tables with time travel
- LakeFS: git-like branching for data lakes
# DVC workflow
dvc init
dvc add data/training_set.csv # track with DVC, not git
git add data/training_set.csv.dvc # commit the metadata
dvc push # push data to remote storage
Model Monitoring
What to Monitor
| Category | Metrics |
|---|---|
| Data drift | KS test, PSI, chi-squared on feature distributions |
| Concept drift | Degradation in online metrics over time |
| Prediction drift | Distribution shift in model outputs |
| Performance | Latency (p50, p99), throughput, error rates |
| Resource usage | CPU, memory, GPU utilization |
Data Drift Detection
Population Stability Index (PSI):
PSI = sum_i (actual_i - expected_i) * ln(actual_i / expected_i)
- PSI < 0.1: no significant change
- PSI 0.1-0.25: moderate shift, investigate
- PSI > 0.25: significant shift, retrain
Retraining Strategies
- Scheduled: retrain on fixed cadence (daily, weekly)
- Triggered: retrain when drift exceeds threshold
- Online learning: continuous updates with each new sample
- Shadow mode: deploy new model alongside old, compare before switching
Responsible AI
Model Interpretability
SHAP (SHapley Additive exPlanations): game-theoretic attribution of prediction to features.
phi_j = sum_{S subset F\{j}} |S|!(|F|-|S|-1)! / |F|! * [f(S u {j}) - f(S)]
Properties: local accuracy, missingness, consistency. TreeSHAP computes exact values for tree models in polynomial time.
LIME (Local Interpretable Model-agnostic Explanations):
- Perturb input around the point of interest
- Get model predictions for perturbed samples
- Fit a simple interpretable model (linear, decision tree) weighted by proximity
- Use the simple model as the local explanation
Fairness Metrics
| Metric | Definition |
|---|---|
| Demographic parity | P(Y_hat=1|A=0) = P(Y_hat=1|A=1) |
| Equalized odds | Equal TPR and FPR across groups |
| Equal opportunity | Equal TPR across groups |
| Predictive parity | Equal precision across groups |
| Calibration | P(Y=1|Y_hat=p, A=a) = p for all a |
Impossibility result: except in trivial cases, you cannot simultaneously satisfy demographic parity, equalized odds, and predictive parity (Chouldechova, 2017).
Mitigation Strategies
- Pre-processing: rebalance or transform training data (reweighting, fair representations)
- In-processing: add fairness constraints to the optimization (adversarial debiasing, constrained optimization)
- Post-processing: adjust decision thresholds per group to equalize the chosen metric
ML Pipeline Checklist
- Define success metrics AND fairness criteria upfront
- Audit training data for representation and label quality
- Establish baselines and document assumptions
- Track experiments with versioned data, code, and configs
- Evaluate on held-out test set with stratified metrics
- Deploy with monitoring for drift, performance, and fairness
- Document model cards: intended use, limitations, ethical considerations
- Plan for model updates and deprecation