Graph Traversal
Graph traversal algorithms visit all vertices and edges systematically. BFS and DFS are the two fundamental approaches, each revealing different structural properties.
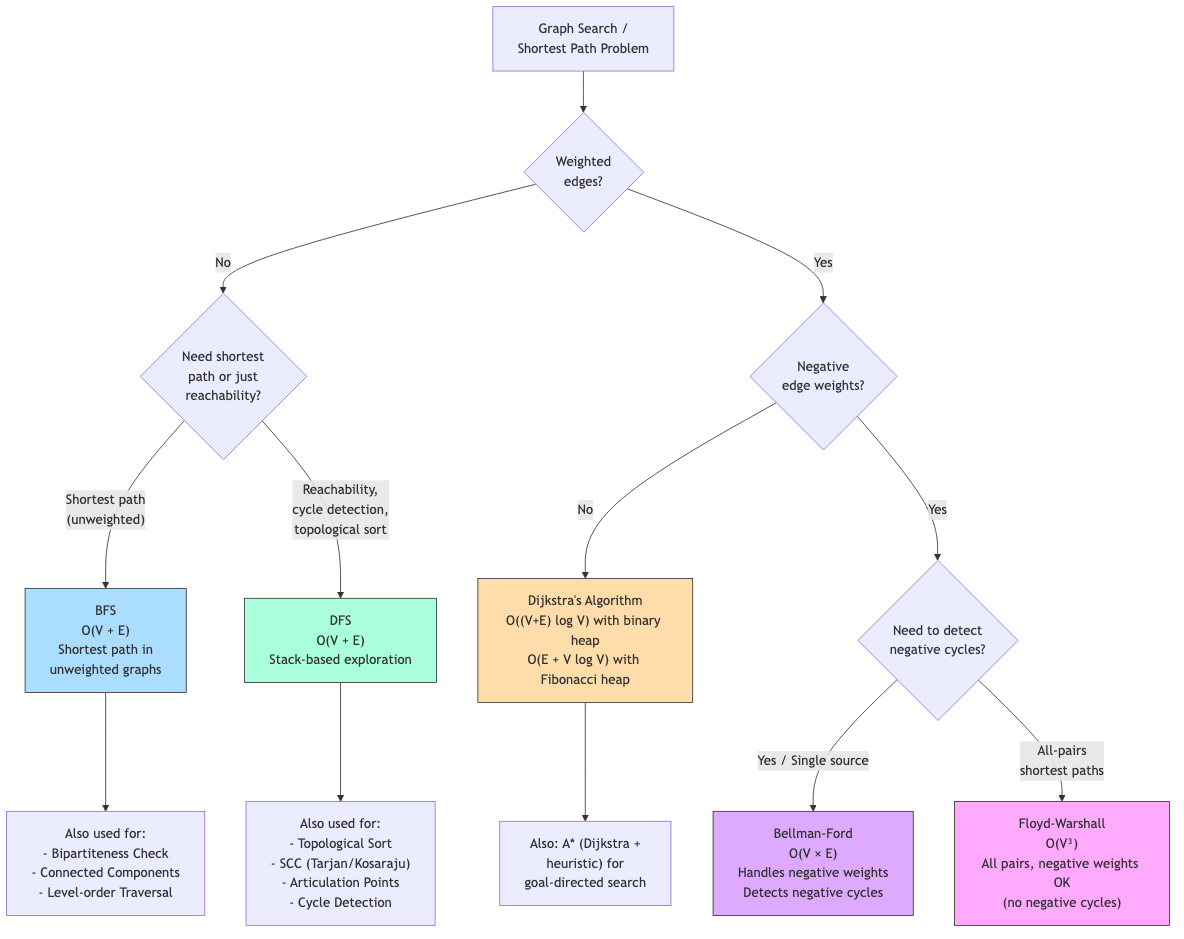
Breadth-First Search (BFS)
Explore vertices in order of increasing distance from the source. Uses a queue.
FUNCTION BFS(graph, source)
n ← number of vertices
dist ← array of size n, all set to -1
parent ← array of size n, all set to NIL
dist[source] ← 0
queue ← empty queue
ENQUEUE(queue, source)
WHILE queue is not empty
u ← DEQUEUE(queue)
FOR EACH v IN neighbors of u
IF dist[v] = -1
dist[v] ← dist[u] + 1
parent[v] ← u
ENQUEUE(queue, v)
RETURN (dist, parent)
Time: O(V + E). Space: O(V) for the queue and distance array.
BFS Properties
- Visits vertices in level order (distance 0, then 1, then 2, ...).
- Shortest path in unweighted graphs (distance = number of edges).
- BFS tree: The parent pointers form a tree of shortest paths from the source.
- Produces cross edges and tree edges only (no back edges in undirected graphs — back edges would mean BFS missed a closer path).
BFS Applications
- Shortest path in unweighted graph: Direct result of BFS.
- Connected components: Run BFS from each unvisited vertex.
- Bipartiteness check: 2-color during BFS. If a conflict is found, the graph is not bipartite (has an odd cycle).
- Level-order tree traversal: BFS on a tree.
- Web crawling: BFS from seed URLs.
- Social network analysis: Degrees of separation (BFS distance).
Depth-First Search (DFS)
Explore as deep as possible before backtracking. Uses a stack (or recursion).
FUNCTION DFS(graph, n)
visited ← array of size n, all false
discovery ← array of size n, all 0
finish ← array of size n, all 0
time ← 0
PROCEDURE DFS_VISIT(u)
visited[u] ← true
time ← time + 1
discovery[u] ← time
FOR EACH v IN neighbors of u
IF NOT visited[v]
DFS_VISIT(v)
time ← time + 1
finish[u] ← time
FOR u ← 0 TO n - 1
IF NOT visited[u]
DFS_VISIT(u)
RETURN (discovery, finish)
Time: O(V + E). Space: O(V) for recursion stack.
Edge Classification (Directed Graphs)
During DFS, edges are classified based on discovery/finish times:
| Edge Type | Condition | Meaning |
|---|---|---|
| Tree edge | v is undiscovered | DFS tree edge |
| Back edge | v is discovered but not finished | Cycle! (v is ancestor of u) |
| Forward edge | v is finished, disc[u] < disc[v] | u is ancestor of v in DFS tree |
| Cross edge | v is finished, disc[u] > disc[v] | No ancestor relationship |
In undirected graphs: Only tree edges and back edges exist.
DFS Properties
- Parenthesis theorem: For any two vertices u, v: either [disc[u], fin[u]] and [disc[v], fin[v]] are disjoint, or one contains the other.
- White-path theorem: v is a descendant of u in the DFS tree iff at time disc[u], there exists a path from u to v consisting entirely of unvisited vertices.
- Cycle detection: A directed graph has a cycle iff DFS finds a back edge.
DFS Applications
- Cycle detection: Back edge in DFS → cycle.
- Topological sort: Sort by decreasing finish time (or use Kahn's algorithm with BFS).
- Finding connected components: Undirected graph — new DFS for each unvisited vertex.
- Finding bridges and articulation points: Using disc/low values.
- Maze solving: DFS explores one path fully before trying another.
Topological Sort
A linear ordering of vertices in a DAG such that for every edge (u, v), u appears before v.
DFS-Based
Run DFS. Output vertices in reverse finish time order.
FUNCTION TOPOLOGICAL_SORT(graph)
n ← number of vertices
visited ← array of size n, all false
order ← empty list
PROCEDURE DFS(u)
visited[u] ← true
FOR EACH v IN neighbors of u
IF NOT visited[v] THEN DFS(v)
APPEND u TO order // add to front of ordering (reversed at end)
FOR u ← 0 TO n - 1
IF NOT visited[u] THEN DFS(u)
REVERSE(order)
RETURN order
Kahn's Algorithm (BFS-Based)
- Compute in-degree of all vertices.
- Add all vertices with in-degree 0 to a queue.
- While queue is non-empty: remove vertex u, add to ordering, decrement in-degree of neighbors. Add any neighbor with in-degree 0 to queue.
FUNCTION KAHN_TOPOLOGICAL(graph)
n ← number of vertices
in_degree ← array of size n, all 0
FOR u ← 0 TO n - 1
FOR EACH v IN neighbors of u
in_degree[v] ← in_degree[v] + 1
queue ← all vertices u WHERE in_degree[u] = 0
order ← empty list
WHILE queue is not empty
u ← DEQUEUE(queue)
APPEND u TO order
FOR EACH v IN neighbors of u
in_degree[v] ← in_degree[v] - 1
IF in_degree[v] = 0 THEN ENQUEUE(queue, v)
IF length(order) = n THEN RETURN order
ELSE RETURN NONE // cycle exists
Cycle detection: If the final order has fewer than n vertices, the graph has a cycle.
Strongly Connected Components (SCCs)
An SCC is a maximal set of vertices where every vertex is reachable from every other.
Tarjan's Algorithm
Single DFS pass. Uses a stack and low-link values.
low[u] = min(disc[u], min(low[v] for tree-child v), min(disc[w] for back-edge to w on stack))
When low[u] == disc[u], vertex u is the root of an SCC. Pop all vertices up to u from the stack — they form one SCC.
Time: O(V + E).
Kosaraju's Algorithm
Two-pass algorithm:
- Run DFS on the original graph. Push vertices to a stack in finish-time order.
- Transpose the graph (reverse all edges).
- Pop vertices from the stack and run DFS on the transposed graph. Each DFS from the stack produces one SCC.
Time: O(V + E). Conceptually simpler than Tarjan but requires two passes.
Biconnected Components and Bridges
Covered in detail in topic 02 (graph connectivity). Key algorithms use DFS with disc/low values:
- Bridge: Edge (u, v) where
low[v] > disc[u]. - Articulation point: Root with ≥ 2 DFS children, or non-root u with a child v where
low[v] ≥ disc[u].
Euler Tour
An Euler tour visits every edge exactly once. An Euler tour of a tree visits each edge twice (once going down, once coming back).
DFS-based Euler tour: Record the vertex at each entry and exit. This "flattens" the tree into an array, enabling range queries on subtrees using segment trees.
Tree: 1
/ \
2 3
/ \
4 5
Euler tour: 1, 2, 4, 4, 5, 5, 2, 3, 3, 1
Entry time: 1→0, 2→1, 3→7, 4→2, 5→4
Exit time: 1→9, 2→6, 3→8, 4→3, 5→5
Subtree of vertex u = range [entry[u], exit[u]] in the Euler tour array.
Iterative Deepening DFS (IDDFS)
Combines DFS's space efficiency with BFS's level-by-level exploration.
Run DFS with depth limit 0, then 1, then 2, ..., until the target is found.
Time: O(b^d) where b = branching factor, d = target depth. Same as BFS asymptotically (the repeated work is bounded by a constant factor: 1 + 1/b + 1/b² + ... ≈ b/(b-1)).
Space: O(d). Much better than BFS's O(b^d).
Used in: Game tree search (iterative deepening alpha-beta). IDA* for shortest path in large graphs.
Bidirectional BFS
Search simultaneously from the source and target. Meet in the middle.
Time: O(b^(d/2)) instead of O(b^d). Exponential speedup!
Requirement: Must be able to search backward (know the goal and reverse edges).
Applications in CS
- Build systems: Topological sort of dependency graphs (Make, Bazel, Cargo).
- Package managers: Dependency resolution = topological sort with version constraints.
- Compilers: DFS for dominators, loop detection, dead code elimination. Topological sort for instruction scheduling.
- Garbage collection: Mark phase of mark-and-sweep is DFS/BFS from roots.
- Web crawling: BFS from seed URLs. DFS for deep crawling.
- Social networks: BFS for shortest path (degrees of separation). DFS for connected components.
- Version control: Git commit graph traversal (merge-base finding, reachability).