Comparison-Based Sorting
Sorting is the most studied problem in computer science. These algorithms sort by comparing pairs of elements.
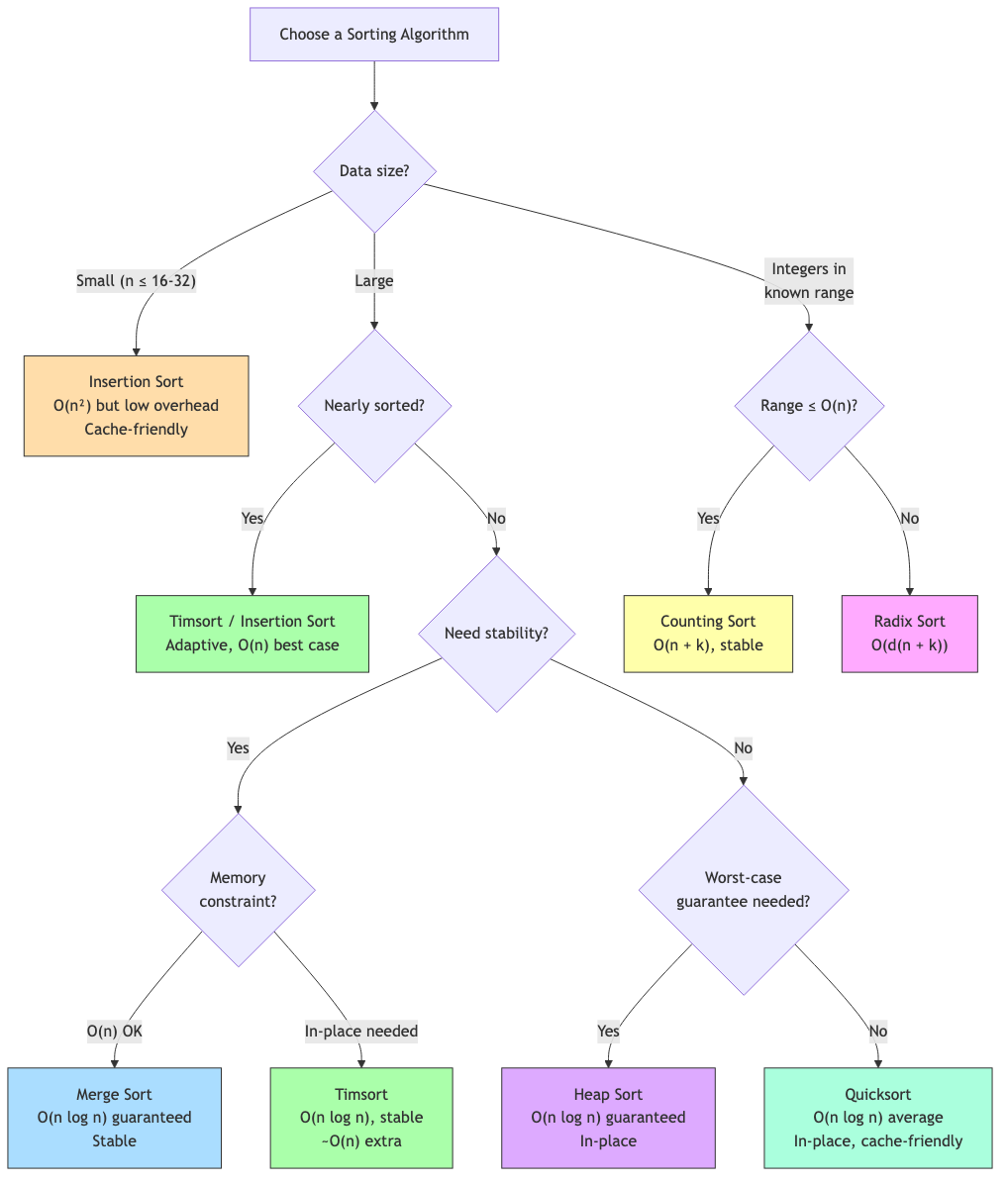
Elementary Sorts
Insertion Sort
Build the sorted array one element at a time. Insert each element into its correct position in the already-sorted portion.
PROCEDURE INSERTION_SORT(arr)
FOR i ← 1 TO length(arr) - 1
j ← i
WHILE j > 0 AND arr[j - 1] > arr[j]
SWAP(arr[j - 1], arr[j])
j ← j - 1
| Case | Time | Reason |
|---|---|---|
| Best | O(n) | Already sorted (inner loop never executes) |
| Average | O(n²) | Each element moves ~n/4 positions |
| Worst | O(n²) | Reverse sorted |
Properties: Stable. In-place (O(1) extra). Adaptive (fast for nearly sorted data). Online (can sort as data arrives). Best for small arrays (n ≤ 16-32) due to low overhead.
Selection Sort
Find the minimum element and swap it to the front. Repeat for the remaining array.
PROCEDURE SELECTION_SORT(arr)
n ← length(arr)
FOR i ← 0 TO n - 1
min_idx ← i
FOR j ← i + 1 TO n - 1
IF arr[j] < arr[min_idx]
min_idx ← j
SWAP(arr[i], arr[min_idx])
Always O(n²) — even for sorted input (always scans for minimum). Not adaptive. Not stable (in the standard implementation). In-place. Minimizes swaps: exactly n-1 swaps.
Bubble Sort
Repeatedly swap adjacent elements that are out of order.
PROCEDURE BUBBLE_SORT(arr)
n ← length(arr)
FOR i ← 0 TO n - 1
swapped ← false
FOR j ← 0 TO n - 2 - i
IF arr[j] > arr[j + 1]
SWAP(arr[j], arr[j + 1])
swapped ← true
IF NOT swapped THEN BREAK // optimization: stop if no swaps
Best O(n) with early termination. Average/worst O(n²). Stable. In-place. Rarely used in practice — insertion sort is better in every practical metric.
Merge Sort
Divide and conquer: Split array in half, recursively sort each half, merge the sorted halves.
PROCEDURE MERGE_SORT(arr)
n ← length(arr)
IF n ≤ 1 THEN RETURN
mid ← n / 2
left ← arr[0..mid]
right ← arr[mid..n]
MERGE_SORT(left)
MERGE_SORT(right)
MERGE(left, right, arr)
PROCEDURE MERGE(left, right, arr)
i ← 0, j ← 0, k ← 0
WHILE i < length(left) AND j < length(right)
IF left[i] ≤ right[j]
arr[k] ← left[i]
i ← i + 1
ELSE
arr[k] ← right[j]
j ← j + 1
k ← k + 1
WHILE i < length(left)
arr[k] ← left[i]; i ← i + 1; k ← k + 1
WHILE j < length(right)
arr[k] ← right[j]; j ← j + 1; k ← k + 1
| Case | Time | Space |
|---|---|---|
| All cases | O(n log n) | O(n) |
Properties: Stable. Not in-place (O(n) extra). Not adaptive (always O(n log n)). Consistent performance. Excellent for linked lists (O(1) extra space, no random access needed). Basis for external sorting.
Recurrence: T(n) = 2T(n/2) + O(n) → T(n) = O(n log n) by master theorem.
Quicksort
Divide and conquer: Choose a pivot, partition array into elements less than and greater than the pivot, recursively sort each partition.
Lomuto Partition
Pivot is the last element. Single scan left-to-right.
FUNCTION PARTITION_LOMUTO(arr, lo, hi)
pivot ← hi
i ← lo
FOR j ← lo TO hi - 1
IF arr[j] ≤ arr[pivot]
SWAP(arr[i], arr[j])
i ← i + 1
SWAP(arr[i], arr[hi])
RETURN i
Hoare Partition
Two pointers converging from both ends. More efficient (fewer swaps on average).
FUNCTION PARTITION_HOARE(arr, lo, hi)
pivot_val ← arr[lo] // simplified; should use median-of-three
i ← lo
j ← hi + 1
LOOP
REPEAT i ← i + 1 UNTIL i ≥ hi OR arr[i] ≥ pivot_val
REPEAT j ← j - 1 UNTIL j ≤ lo OR arr[j] ≤ pivot_val
IF i ≥ j THEN BREAK
SWAP(arr[i], arr[j])
SWAP(arr[lo], arr[j])
RETURN j
Pivot Selection
- First/last element: O(n²) on sorted input. Terrible.
- Random: Expected O(n log n). Simple and effective.
- Median-of-three: Median of first, middle, last. Avoids worst case for sorted/reverse-sorted input.
- Ninther (median of medians of three): Used in Introsort.
| Case | Time |
|---|---|
| Best | O(n log n) — balanced partitions |
| Average | O(n log n) — expected with random pivot |
| Worst | O(n²) — pivot always min or max |
Properties: Not stable (standard implementation). In-place (O(log n) stack space). Fastest comparison sort in practice for random data (cache-friendly, low overhead).
Why fastest in practice: Small constant factor. In-place (good cache behavior). Inner loop does simple comparisons. Compilers optimize it well.
Heapsort
Build a max-heap, repeatedly extract the maximum.
PROCEDURE HEAPSORT(arr)
n ← length(arr)
// Build max-heap
FOR i ← n/2 - 1 DOWNTO 0
SIFT_DOWN(arr, i, n)
// Extract elements
FOR i ← n - 1 DOWNTO 1
SWAP(arr[0], arr[i])
SIFT_DOWN(arr, 0, i)
Always O(n log n). In-place. Not stable. Not adaptive. Guaranteed worst-case O(n log n) — better than quicksort's worst case.
Disadvantage: Poor cache behavior (heap access pattern jumps around the array). About 2× slower than quicksort in practice.
Lower Bound for Comparison Sorting
Theorem: Any comparison-based sorting algorithm requires Ω(n log n) comparisons in the worst case.
Proof (decision tree argument):
- Any comparison sort can be modeled as a binary decision tree.
- n! possible permutations → at least n! leaves.
- Tree height ≥ log₂(n!) = Ω(n log n) (by Stirling's approximation).
This means merge sort, heapsort, and (average-case) quicksort are asymptotically optimal among comparison-based sorts.
Comparison Summary
| Algorithm | Best | Average | Worst | Space | Stable | Adaptive |
|---|---|---|---|---|---|---|
| Insertion | O(n) | O(n²) | O(n²) | O(1) | Yes | Yes |
| Selection | O(n²) | O(n²) | O(n²) | O(1) | No | No |
| Bubble | O(n) | O(n²) | O(n²) | O(1) | Yes | Yes |
| Merge | O(n log n) | O(n log n) | O(n log n) | O(n) | Yes | No |
| Quicksort | O(n log n) | O(n log n) | O(n²) | O(log n) | No | No |
| Heapsort | O(n log n) | O(n log n) | O(n log n) | O(1) | No | No |
Applications in CS
- Standard library sorts: Most use hybrid algorithms (Timsort, Introsort, pdqsort — covered in next file).
- Database query execution: ORDER BY, merge joins, sort-merge aggregation.
- Search preprocessing: Binary search requires sorted data.
- Computational geometry: Sweep line algorithms sort events.
- Data analysis: Percentiles, rank statistics, deduplication.