Adversarial Search
Adversarial search handles competitive environments where agents have conflicting goals — primarily two-player zero-sum games.
Minimax Algorithm
For two-player zero-sum games with perfect information. MAX tries to maximize the score. MIN tries to minimize it.
PROCEDURE MINIMAX(state, depth, maximizing) → integer
IF depth = 0 OR IS_TERMINAL(state) THEN
RETURN EVALUATE(state) // heuristic evaluation
IF maximizing THEN
best ← -INFINITY
FOR EACH move IN LEGAL_MOVES(state) DO
child ← APPLY_MOVE(state, move)
best ← MAX(best, MINIMAX(child, depth - 1, FALSE))
RETURN best
ELSE
best ← +INFINITY
FOR EACH move IN LEGAL_MOVES(state) DO
child ← APPLY_MOVE(state, move)
best ← MIN(best, MINIMAX(child, depth - 1, TRUE))
RETURN best
Complete: Yes (for finite games). Optimal: Yes (against an optimal opponent). Time: O(b^m). Space: O(bm) (DFS).
Alpha-Beta Pruning
Prune branches that can't affect the minimax decision. Maintains two values:
- α: Best (highest) value MAX can guarantee along the path so far.
- β: Best (lowest) value MIN can guarantee along the path so far.
Prune when α ≥ β — the current branch can't produce a better result than an already-found alternative.
PROCEDURE ALPHA_BETA(state, depth, alpha, beta, maximizing) → integer
IF depth = 0 OR IS_TERMINAL(state) THEN
RETURN EVALUATE(state)
IF maximizing THEN
value ← -INFINITY
FOR EACH move IN LEGAL_MOVES(state) DO
child ← APPLY_MOVE(state, move)
value ← MAX(value, ALPHA_BETA(child, depth - 1, alpha, beta, FALSE))
alpha ← MAX(alpha, value)
IF alpha ≥ beta THEN BREAK // beta-cutoff
RETURN value
ELSE
value ← +INFINITY
FOR EACH move IN LEGAL_MOVES(state) DO
child ← APPLY_MOVE(state, move)
value ← MIN(value, ALPHA_BETA(child, depth - 1, alpha, beta, TRUE))
beta ← MIN(beta, value)
IF alpha ≥ beta THEN BREAK // alpha-cutoff
RETURN value
Effectiveness: With perfect move ordering, reduces effective branching factor from b to √b. Time: O(b^(m/2)) — doubles the searchable depth! Random ordering: O(b^(3m/4)).
Move ordering is critical: try the best moves first. Techniques: iterative deepening (use previous depth's best move), killer heuristic (moves that caused cutoffs in sibling nodes), history heuristic.
Transposition Tables
Cache evaluated positions in a hash table. If the same position is reached via different move sequences, reuse the stored result.
Zobrist hashing: XOR-based incremental hash. Each (piece, square) pair has a random 64-bit number. Hash = XOR of all occupied squares' values. Update: XOR out old position, XOR in new position — O(1) incremental update.
Iterative Deepening Minimax
Run alpha-beta with increasing depth limits: 1, 2, 3, .... Use the best move from each depth as the first move to try at the next depth (improves move ordering).
Time control: Stop when time runs out. Return the best move from the deepest completed search.
Expectiminimax
For games with chance nodes (dice rolls, card draws).
MAX nodes: maximize over children
MIN nodes: minimize over children
CHANCE nodes: weighted average over children (by probability)
Time: O(b^m × n^m) where n = number of outcomes per chance node. Much more expensive than deterministic minimax.
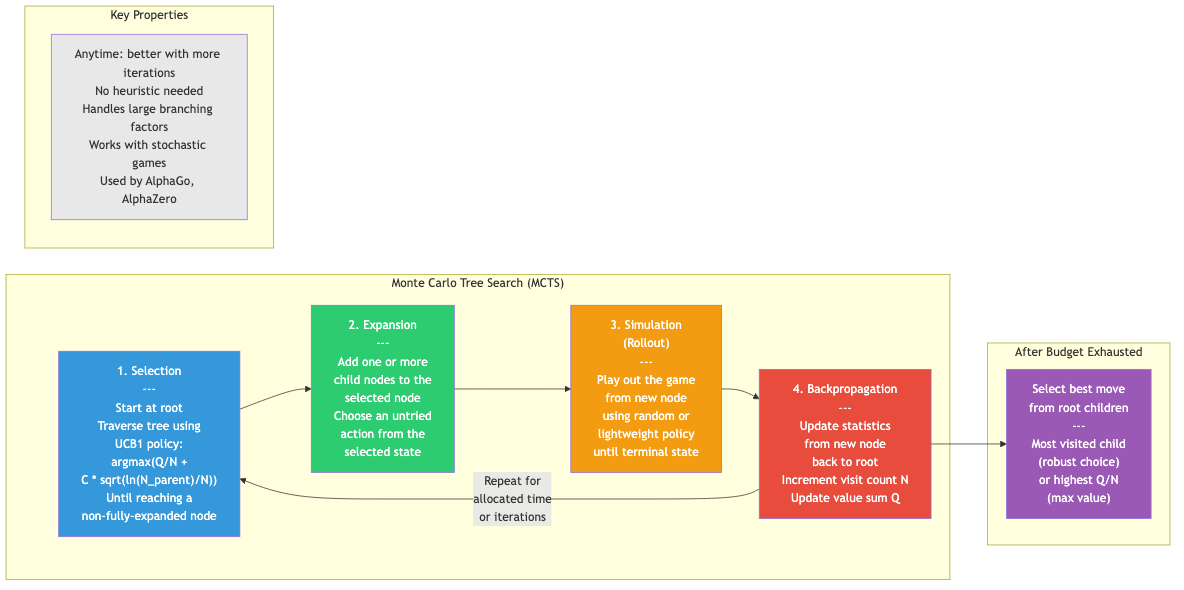
Monte Carlo Tree Search (MCTS)
Build the game tree selectively using random simulations. No evaluation function needed.
Algorithm (UCT)
1. SELECTION: Start at root. Descend by choosing child that maximizes
UCB1 = win_rate + C × √(ln(parent_visits) / child_visits)
Until reaching an unexpanded node.
2. EXPANSION: Add one new child node.
3. SIMULATION (rollout): Play a random game from the new node to completion.
4. BACKPROPAGATION: Update win counts and visit counts along the path back to root.
Repeat many times. Choose the root's most-visited child as the best move.
UCB1 formula balances:
- Exploitation: win_rate (choose moves that win often)
- Exploration: C × √(ln(N)/nᵢ) (choose less-explored moves)
C ≈ √2 (theoretically optimal). Tuned per application.
MCTS Properties
- Anytime: Can return a move at any time. More computation → better moves.
- No evaluation function needed (learns from simulations).
- Handles large branching factors (doesn't explore uniformly — focuses on promising branches).
- Handles stochastic games naturally.
AlphaGo / AlphaZero
AlphaGo (2016): MCTS + deep neural networks.
- Policy network: Predicts good moves (guides selection). Trained from human games + self-play.
- Value network: Evaluates board positions (replaces random rollouts). Trained from self-play outcomes.
AlphaZero (2017): Tabula rasa — learns entirely from self-play, no human data. Uses a single neural network for both policy and value. Defeated the best chess, shogi, and Go programs.
MuZero (2019): Learns a model of the environment (not given game rules). Plans in a learned latent space. Applies to Atari games as well as board games.
Games of Imperfect Information
Poker and Bluffing
Information sets: Group game states that are indistinguishable to the acting player (can't see opponent's cards).
Nash equilibrium: A strategy profile where no player can improve by changing their strategy alone. For two-player zero-sum games, the minimax value = Nash equilibrium value.
Counterfactual Regret Minimization (CFR): Iterative algorithm that converges to Nash equilibrium. Used by Libratus and Pluribus (superhuman poker AIs).
Pluribus (2019): Beat top human professionals in 6-player no-limit Texas Hold'em. Used modified CFR + real-time search.
Applications in CS
- Game AI: Chess engines (Stockfish: alpha-beta + NNUE), Go (AlphaGo/KataGo: MCTS + DNN), poker (Pluribus: CFR).
- Decision making: Multi-agent systems, negotiation, auction strategy.
- Cybersecurity: Attacker-defender models as adversarial games.
- Economics: Mechanism design, market simulations.
- Verified AI: Adversarial robustness testing — find worst-case inputs.