Intermediate Representations
An intermediate representation (IR) is a data structure used internally by the compiler. It bridges the gap between the source language and target machine code, enabling language-independent optimization.
Three-Address Code
Each instruction has at most three operands (two sources, one destination). Named after this property.
Source: a = b + c * d - e
Three-address code:
t1 = c * d
t2 = b + t1
t3 = t2 - e
a = t3
Instruction forms:
x = y op z(binary operation)x = op y(unary operation)x = y(copy)goto L(unconditional jump)if x relop y goto L(conditional jump)x = y[i](indexed access)x = call f, n(function call with n arguments)param x(pass parameter)return x(return value)
Advantages: Simple, uniform instructions. Easy to optimize (each instruction explicitly names its operands). Close to machine code.
Representation: Quadruples (op, arg1, arg2, result), triples (op, arg1, arg2 — result is implicit), or a structured IR.
Static Single Assignment (SSA)
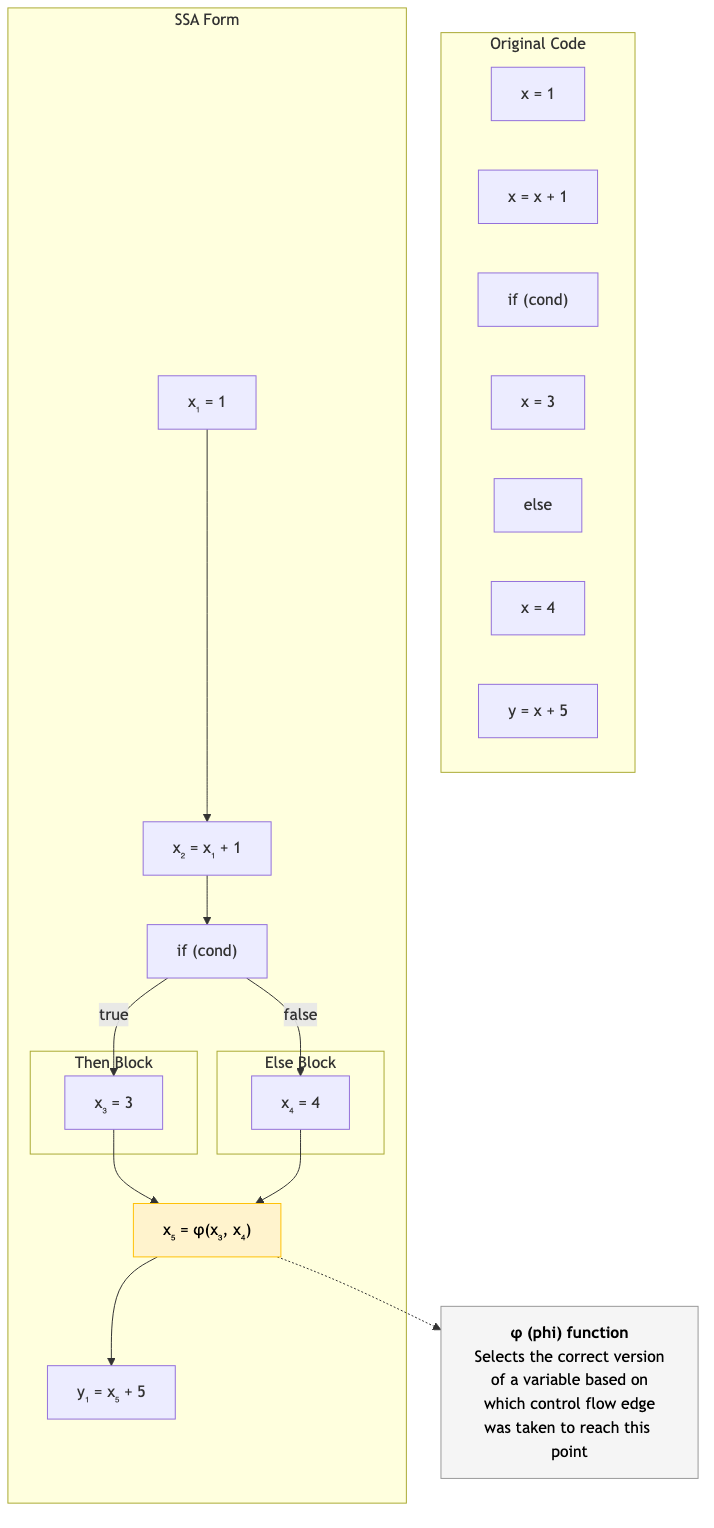
Each variable is assigned exactly once. If a variable is assigned multiple times in the source, create new versions.
Source: SSA:
x = 1 x₁ = 1
x = x + 1 x₂ = x₁ + 1
y = x + 2 y₁ = x₂ + 2
if (cond) if (cond)
x = 3 x₃ = 3
else else
x = 4 x₄ = 4
z = x + 5 x₅ = φ(x₃, x₄) ← phi function!
z₁ = x₅ + 5
Phi Functions (φ)
At merge points (where control flow joins), a φ function selects the correct version based on which predecessor block was executed.
x₅ = φ(x₃, x₄)
// If we came from the 'then' branch: x₅ = x₃
// If we came from the 'else' branch: x₅ = x₄
φ functions are not real instructions — they are eliminated during code generation (via register allocation or by placing copies at the end of predecessor blocks).
Why SSA?
Simpler analysis: Each use of a variable has exactly one definition → def-use chains are trivial. No need to track "which assignment is visible here."
Enables optimizations:
- Constant propagation: If x₁ = 5, every use of x₁ is 5.
- Dead code elimination: If x₃ has no uses, the assignment is dead.
- Common subexpression elimination: Easier when each expression has a unique name.
- Register allocation: SSA variables map naturally to virtual registers.
Constructing SSA
- Build the control flow graph (CFG).
- Compute dominance frontiers (where φ functions are needed).
- Insert φ functions at dominance frontiers for each variable.
- Rename variables (walk the dominator tree, assign versions).
Dominance
Block A dominates block B if every path from the entry to B goes through A.
Immediate dominator (idom): The closest dominator (not the block itself).
Dominator tree: Tree of immediate dominator relationships. The entry block is the root.
Dominance frontier of A: The set of blocks where A's dominance "ends" — where a φ function might be needed.
Entry
│
A
/ \
B C
\ /
D ← dominance frontier of B and C (merge point)
Control Flow Graphs (CFG)
A directed graph where:
- Nodes = basic blocks (straight-line code, no jumps except at the end)
- Edges = control flow (jumps, branches, fall-through)
Basic Blocks
A maximal sequence of instructions with:
- One entry point (the first instruction — no jumps into the middle)
- One exit point (the last instruction — a jump, branch, or fall-through)
Block B1: Block B2: Block B3:
x = 1 t = x + y z = x * 2
y = 2 if t > 10 goto B3 return z
goto B2
Leaders
The first instruction of each basic block:
- The first instruction of the program.
- Any target of a jump/branch.
- Any instruction immediately following a jump/branch.
Other IRs
Sea of Nodes (Click)
Used by HotSpot C2 (JVM JIT), Graal, TurboFan (V8).
No explicit control flow graph — instead, a graph where both data dependencies and control dependencies are edges. Very flexible for optimization (reordering is natural).
A-Normal Form (ANF)
All intermediate results are bound to variables. No nested expressions.
// Direct style: (f (g x) (h y))
// ANF: let a = g(x)
// let b = h(y)
// f(a, b)
Similar to SSA but for functional languages. Used in ML compilers.
Continuation-Passing Style (CPS)
Every function takes an explicit continuation — a callback representing "what to do next."
// Direct: let x = f(a) + g(b) in h(x)
// CPS: f(a, λv₁. g(b, λv₂. let x = v₁ + v₂ in h(x, halt)))
Advantages: Makes control flow explicit. Tail calls are obvious. Enables powerful optimizations. Used in SML/NJ, some Scheme compilers.
Relationship to SSA: CPS and SSA are equivalent in expressive power (Kelsey, 1995). φ functions correspond to continuation parameters.
LLVM IR
The IR used by the LLVM compiler framework. SSA-based, typed, portable.
define i32 @factorial(i32 %n) {
entry:
%cmp = icmp eq i32 %n, 0
br i1 %cmp, label %base, label %recurse
base:
ret i32 1
recurse:
%n_minus_1 = sub i32 %n, 1
%result = call i32 @factorial(i32 %n_minus_1)
%product = mul i32 %n, %result
ret i32 %product
}
Key features: Typed (i32, i64, float, pointers), SSA form, explicit control flow, target-independent (same IR for all architectures), well-documented.
Bytecode
A compact, portable IR designed for interpretation or JIT compilation.
JVM Bytecode
Stack-based. Each instruction operates on an operand stack.
// Java: int x = a + b * c;
iload_1 // push a
iload_2 // push b
iload_3 // push c
imul // pop b,c; push b*c
iadd // pop a,b*c; push a+b*c
istore_4 // pop result; store in x
WebAssembly (Wasm)
A portable bytecode for the web (and beyond). Stack-based with structured control flow.
(func $factorial (param $n i32) (result i32)
(if (i32.eq (local.get $n) (i32.const 0))
(then (i32.const 1))
(else
(i32.mul
(local.get $n)
(call $factorial (i32.sub (local.get $n) (i32.const 1)))))))
Design goals: Safe (sandboxed), fast (near-native speed with JIT), portable (runs in browsers, servers, embedded). Compile target for C, C++, Rust, Go, and more.
CLR IL (.NET)
Stack-based bytecode for the .NET runtime. JIT-compiled to native code.
Applications in CS
- Compiler development: IR design determines what optimizations are possible and how complex they are.
- Cross-language tooling: LLVM IR enables tools (sanitizers, profilers, optimizers) to work across all LLVM-based languages.
- Portable computation: WebAssembly enables running code anywhere (browsers, servers, edge, embedded).
- Program analysis: SSA form simplifies many analyses (constant propagation, reaching definitions, liveness).
- JIT compilation: Bytecode is compact and fast to interpret; hot paths are JIT-compiled to native code.