Syntax Analysis (Parsing)
The parser takes a token stream from the lexer and builds a structured representation (parse tree or AST) according to the language's grammar.
Context-Free Grammars (Review)
A CFG G = (V, Σ, P, S) defines the syntax. Productions describe how to derive valid programs.
// Simple expression grammar
Expr → Expr '+' Term | Expr '-' Term | Term
Term → Term '*' Factor | Term '/' Factor | Factor
Factor → '(' Expr ')' | NUMBER | IDENTIFIER
This grammar encodes precedence (* binds tighter than +) and associativity (left-to-right) in its structure.
Parse Trees vs ASTs
Parse tree (concrete syntax tree): Includes all grammar symbols, including intermediate non-terminals.
AST (abstract syntax tree): Simplified tree retaining only essential structure. Drops parentheses, intermediate nodes.
Expression: 2 + 3 * 4
Parse tree: AST:
Expr +
/ | \ / \
Expr + Term 2 *
| | \ / \
Term Term * Factor 3 4
| | |
Factor Factor 4
| |
2 3
Ambiguity Resolution
Operator Precedence
Higher-precedence operators appear deeper in the grammar (closer to terminal rules).
Expr → Expr '+' Term | Term // + is lower precedence (closer to start)
Term → Term '*' Factor | Factor // * is higher precedence (deeper)
Associativity
Left-associative (most operators): Left-recursive production.
Expr → Expr '+' Term // left-recursive → left-associative: (a+b)+c
Right-associative (assignment, exponentiation): Right-recursive production.
Assign → IDENTIFIER '=' Assign | Expr // right-recursive: a = b = c → a = (b = c)
Dangling Else
if (a) if (b) s1 else s2
// Does 'else' belong to the inner or outer 'if'?
Convention: else matches the nearest unmatched if. Most parsers handle this by preferring shift over reduce (in LR parsers) or by restructuring the grammar.
Top-Down Parsing
Parse from the start symbol down to the terminal tokens.
Recursive Descent
Each non-terminal becomes a function. The function examines the next token(s) to decide which production to apply.
CLASS Parser
FIELDS: tokens (list), pos (integer)
FUNCTION PARSE_EXPR()
left ← PARSE_TERM()
WHILE CURRENT_TOKEN is Plus OR Minus
op ← ADVANCE()
right ← PARSE_TERM()
left ← BinaryExpr(left, op, right)
RETURN left
FUNCTION PARSE_TERM()
left ← PARSE_FACTOR()
WHILE CURRENT_TOKEN is Star OR Slash
op ← ADVANCE()
right ← PARSE_FACTOR()
left ← BinaryExpr(left, op, right)
RETURN left
FUNCTION PARSE_FACTOR()
IF CURRENT_TOKEN is LParen
ADVANCE() // consume '('
expr ← PARSE_EXPR()
EXPECT(RParen)
RETURN expr
ELSE IF CURRENT_TOKEN is Number(n)
ADVANCE()
RETURN NumberExpr(n)
ELSE
ERROR "unexpected token: ", PEEK()
Advantages: Simple, intuitive. Excellent error messages (know exactly where we are in the grammar). Easy to extend. No external tools needed.
Used by: GCC, Clang, rustc, Go, TypeScript, most hand-written parsers.
Limitation: Can't handle left-recursive grammars directly (infinite recursion). Must rewrite: E → E + T becomes E → T (('+') T)*.
LL(1) Parsing
Predictive parsing: Use a single lookahead token to decide which production to apply. No backtracking.
FIRST set: Set of terminals that can begin a derivation from a non-terminal.
FOLLOW set: Set of terminals that can appear immediately after a non-terminal.
LL(1) parse table: M[A, a] = production to use when non-terminal A sees lookahead token a.
LL(1) conflict: If a cell in the table has multiple entries, the grammar is not LL(1).
LL(k): Use k tokens of lookahead. More powerful but larger tables.
Parser Combinators
Build parsers by combining smaller parsers using higher-order functions.
// Parser combinator style
FUNCTION EXPR(input)
(input, first) ← TERM(input)
(input, rest) ← MANY(SEQUENCE(ONE_OF('+', '-'), TERM))(input)
RETURN (input, FOLD_LEFT(rest, first, (acc, (op, t)) -> BinaryExpr(acc, op, t)))
Advantages: Composable. No separate grammar file. Type-safe. Good for small-to-medium grammars.
Libraries: nom (Rust, widely used), chumsky (Rust, better errors), parsec (Haskell), megaparsec (Haskell).
Bottom-Up Parsing
Parse from the terminal tokens up to the start symbol. More powerful than top-down — handles left-recursive grammars naturally.
Shift-Reduce Parsing
Maintain a stack. Two operations:
Shift: Push the next input token onto the stack.
Reduce: Replace the top of the stack (matching a production's right side) with the production's left side.
Input: 2 + 3 * 4
Stack Input Action
2+3*4$
2 +3*4$ Shift 2
Factor +3*4$ Reduce Factor → 2
Term +3*4$ Reduce Term → Factor
Expr +3*4$ Reduce Expr → Term
Expr + 3*4$ Shift +
Expr + 3 *4$ Shift 3
Expr + Factor *4$ Reduce
Expr + Term *4$ Reduce
Expr + Term * 4$ Shift *
Expr + Term * 4 $ Shift 4
Expr + Term * Factor $ Reduce
Expr + Term $ Reduce (Term → Term * Factor)
Expr $ Reduce (Expr → Expr + Term)
ACCEPT
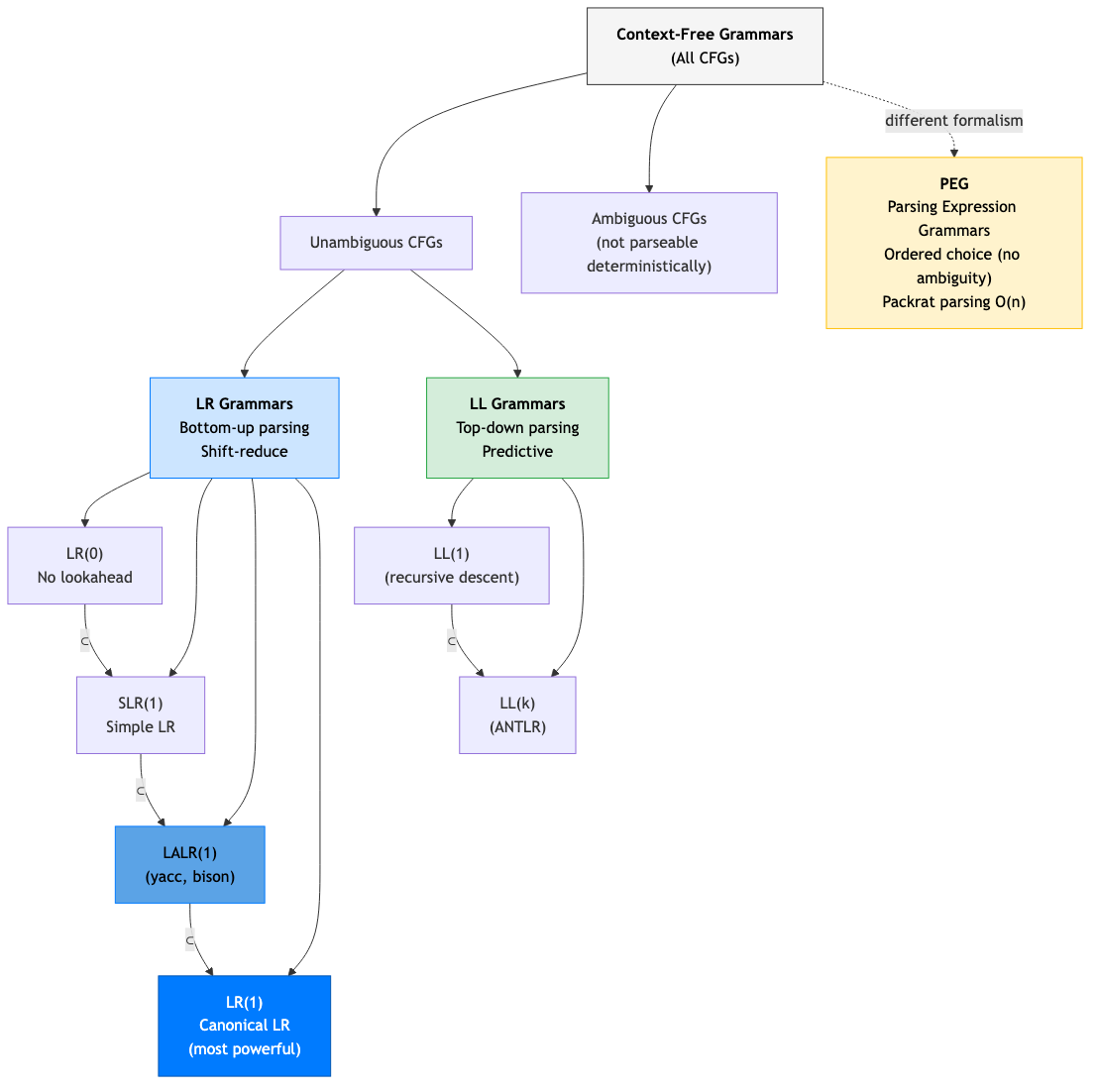
LR Parsing Family
LR(k): Left-to-right scan, Rightmost derivation, k tokens of lookahead.
| Parser | Power | Table Size | Use |
|---|---|---|---|
| LR(0) | Weakest | Small | Too weak for most grammars |
| SLR(1) | Medium | Small | Simple grammars |
| LALR(1) | Strong | Medium | Most programming languages (yacc/bison) |
| LR(1) | Strongest | Large | Very complex grammars |
| GLR | Universal | Medium | Ambiguous grammars (multiple parses) |
LALR(1) is the sweet spot for generated parsers — handles most programming languages with compact tables.
Parser Generators
yacc / bison (C): The classic. Define grammar + actions → generate C parser.
// bison grammar excerpt
expr: expr '+' term { $$ = make_binary('+', $1, $3); }
| expr '-' term { $$ = make_binary('-', $1, $3); }
| term { $$ = $1; }
;
ANTLR (Java, multi-target): LL(*) parser generator. Generates parsers in Java, Python, C#, JavaScript, Go, C++. Excellent tooling (ANTLRWorks, syntax diagrams).
tree-sitter (C, multi-language): Incremental parser generator. Used by editors (Neovim, Helix, Zed) for syntax highlighting, code folding, structural navigation. Handles incomplete/erroneous code gracefully.
lalrpop (Rust): LALR(1) parser generator for Rust.
pest (Rust): PEG parser generator.
Error Recovery
Parsers should report multiple errors per compilation, not just the first one.
Panic Mode
On error: skip tokens until a synchronization token is found (;, }, keyword). Resume parsing from there.
PROCEDURE SYNCHRONIZE()
ADVANCE() // skip the error token
WHILE NOT AT_END()
IF PREVIOUS_TOKEN = Semicolon THEN RETURN
IF CURRENT_TOKEN IN {Fn, Let, If, Return} THEN RETURN
ADVANCE()
Phrase-Level Recovery
Insert or delete specific tokens to fix the parse locally.
Expected ')' but found ';' → Insert ')' before ';', continue parsing
Error Productions
Add grammar rules for common mistakes.
// Common mistake: missing semicolon
stmt → expr ';'
| expr error { report("missing semicolon") } // error production
PEG Grammars
Parsing Expression Grammars: Similar to CFGs but with ordered choice (try alternatives in order, commit to the first match).
Expr ← Term (('+' / '-') Term)*
Term ← Factor (('*' / '/') Factor)*
Factor ← '(' Expr ')' / NUMBER / IDENTIFIER
Key difference from CFG: PEG's / (ordered choice) always picks the first successful match. No ambiguity.
Advantages: No ambiguity. Scannerless (can integrate lexing). Supports unlimited lookahead.
Disadvantages: Left recursion requires special handling. Ordered choice can mask bugs. No formal theory of "the language" as rich as CFG.
Tools: pest (Rust), PEG.js (JavaScript), packrat parsers.
Applications in CS
- Compilers: Central phase — determines whether code is syntactically valid and builds the structure for subsequent phases.
- IDEs: Incremental parsing (tree-sitter) enables syntax highlighting, code folding, and structural navigation that updates as you type.
- Linters/Formatters: Parse code to AST, analyze or reformat, emit modified source.
- Domain-specific languages: Custom parsers for configuration files, query languages, template languages.
- Data formats: JSON, XML, YAML, TOML, protobuf — all defined by grammars and parsed by specialized parsers.