Distributed System Models
Overview
A distributed system is a collection of independent computers that appears to its users as a single coherent system. Understanding the models that describe timing, failures, and communication is essential before building anything on top.
System Models
Synchronous Model
All processes execute in lock-step rounds. Messages are delivered within a known bounded delay, and processors have known bounded clock drift.
Assumptions:
- Message delay: bounded by known constant d
- Processing time: bounded by known constant p
- Clock drift: bounded by known rate ρ
Round 1 Round 2 Round 3
|-- send --|-- send --|-- send --|
| ≤ d ms | ≤ d ms | ≤ d ms |
This model is unrealistic for most real networks but useful for proving lower bounds and impossibility results.
Asynchronous Model
No timing assumptions at all. Messages can be delayed arbitrarily, processors can pause for arbitrary durations, and there are no clocks.
Process A: ──send──────────────────────recv──────>
\ /
Process B: ──────recv──process──send──────────────>
(arbitrary delay)
The asynchronous model is the hardest to work with but the most realistic for internet-scale systems.
Partially Synchronous Model
The most practical model. The system behaves asynchronously but eventually becomes synchronous (there exists an unknown Global Stabilization Time, GST, after which message delays are bounded).
Before GST: After GST:
delays ∈ [0, ∞) delays ∈ [0, Δ]
┌─?──?──?──?─┐ ┌──Δ──Δ──Δ──┐
│ chaos │ │ bounded │
└─────────────┘ └────────────┘
Most practical consensus protocols (Raft, PBFT) assume partial synchrony.
Failure Models
Failures are arranged in a hierarchy from least to most severe:
Byzantine (arbitrary/malicious)
│
Authenticated Byzantine
│
Omission (message loss)
│
Crash-Recovery (crash then restart)
│
Crash-Stop (fail and never return)
│
No failures
Crash-Stop Failures
A process halts and never recovers. Other processes can eventually detect the crash through timeouts (in partially synchronous models).
Crash-Recovery Failures
A process crashes but may restart later with stable storage intact. Protocols must handle processes that rejoin with stale state.
Omission Failures
Messages are lost (send omission or receive omission). The process itself continues executing. Network partitions are a form of omission failure.
Byzantine Failures
A process can behave arbitrarily: send conflicting messages, lie, collude with other faulty processes, or act maliciously. This is the strongest failure model.
Tolerance thresholds:
| Failure Type | Tolerance Bound |
|---|---|
| Crash (async) | Impossible for consensus (FLP) |
| Crash (partial sync) | f < n/2 |
| Byzantine (partial sync) | f < n/3 |
The FLP Impossibility Result
Fischer, Lynch, and Paterson (1985) proved that no deterministic consensus protocol can guarantee agreement in an asynchronous system if even one process can crash.
FLP Impossibility:
Given: Asynchronous network + 1 possible crash failure
Impossible: Deterministic consensus with all three:
1. Agreement (all correct processes decide same value)
2. Validity (decided value was proposed by some process)
3. Termination (all correct processes eventually decide)
Practical workarounds:
- Use randomized algorithms (probability-1 termination)
- Assume partial synchrony (Paxos, Raft)
- Use failure detectors (unreliable but useful abstractions)
- Weaken termination (allow finite periods of non-termination)
The Two Generals Problem
Two armies must coordinate an attack but communicate over an unreliable channel. No protocol with a finite number of messages can guarantee agreement.
General A General B
│ │
│──── "Attack at dawn" ────> │ (might be lost)
│ │
│ <──── "ACK" ──────────── │ (might be lost)
│ │
│──── "ACK of ACK" ────────> │ (might be lost)
│ ... │
│ (infinite regress) │
This demonstrates that reliable communication over unreliable channels is impossible with deterministic protocols. TCP "solves" this pragmatically, not theoretically.
The End-to-End Argument
Proposed by Saltzer, Reed, and Clark (1984): functions should be implemented at the endpoints, not in the communication infrastructure, unless doing so in the middle provides significant performance gains.
Application Layer: [Checksums, Retries, Ordering] <-- correctness here
│
Transport Layer: [Best-effort delivery]
│
Network Layer: [Routing, forwarding]
│
Link Layer: [Hop-by-hop reliability] <-- optimization only
Implications for distributed systems:
- Reliability at the network layer doesn't guarantee end-to-end reliability
- Exactly-once delivery must be implemented at the application level
- Idempotent operations are a practical application of this principle
Fallacies of Distributed Computing
Peter Deutsch and James Gosling identified eight false assumptions developers make:
1. The network is reliable ──> packets drop, links fail
2. Latency is zero ──> speed of light is finite
3. Bandwidth is infinite ──> congestion is real
4. The network is secure ──> adversaries exist
5. Topology doesn't change ──> nodes join/leave/move
6. There is one administrator ──> organizational boundaries
7. Transport cost is zero ──> serialization, encryption
8. The network is homogeneous ──> mixed hardware/software
Practical Impact
// Fallacy #1 & #2: Assuming reliable, zero-latency network
// BAD: Synchronous call chain
PROCEDURE GET_USER_PROFILE(user_id) → Profile or error
user ← user_service.GET(user_id) // network call
prefs ← pref_service.GET(user_id) // network call
history ← history_service.GET(user_id) // network call
// Total latency = sum of all three calls
// Any failure = total failure
RETURN Profile(user, prefs, history)
// BETTER: Parallel calls with timeouts and fallbacks
ASYNC PROCEDURE GET_USER_PROFILE(user_id) → Profile or error
(user, prefs, history) ← AWAIT ALL IN PARALLEL(
TIMEOUT(200 ms, user_service.GET(user_id)),
TIMEOUT(200 ms, pref_service.GET(user_id)),
TIMEOUT(200 ms, history_service.GET(user_id))
)
RETURN Profile(
user ← user (required, propagate error),
prefs ← prefs OR DEFAULT_PREFERENCES,
history ← history OR empty list
)
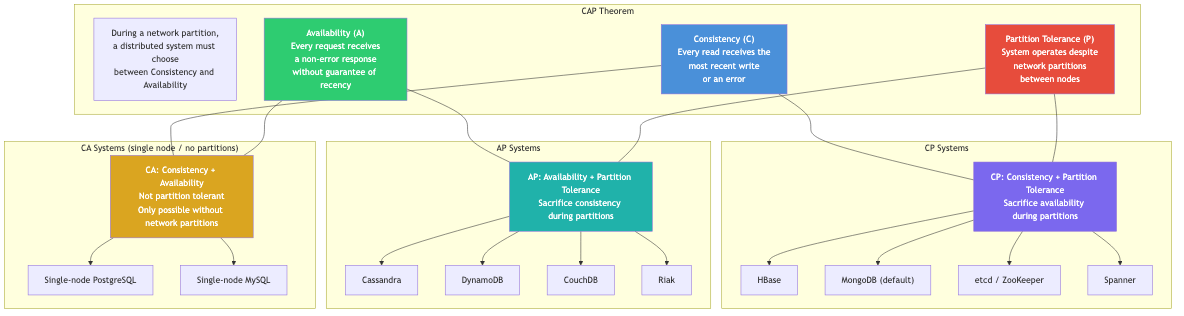
CAP Theorem Connection
The system models directly inform the CAP theorem (Brewer, 2000):
Consistency
/\
/ \
/ CP \ CA systems assume no partitions
/──────\ (single-node databases)
/ \
/ You pick \ CP: consistent but may be unavailable
/ two \ during partitions (ZooKeeper, etcd)
/ \
/________________\ AP: available but may return stale data
Availability ── Partition during partitions (Cassandra, DynamoDB)
Tolerance
Since partitions are inevitable in distributed systems,
the real choice is between CP and AP.
Real-World Applications
| System | Model | Failure Assumption | Trade-off |
|---|---|---|---|
| etcd/Raft | Partial sync | Crash-recovery, f < n/2 | CP: strong consistency |
| Cassandra | Async | Crash, tunable quorum | AP: high availability |
| Bitcoin | Async | Byzantine, f < n/3 (hash power) | Probabilistic finality |
| Spanner | Partial sync | Crash, f < n/2 + TrueTime | CP: external consistency |
| PBFT | Partial sync | Byzantine, f < n/3 | CP: BFT consensus |
Key Takeaways
- The synchronous model is too strong for real systems; the asynchronous model is too weak for useful guarantees. Partial synchrony is the sweet spot.
- FLP says deterministic async consensus is impossible with even one crash -- but practical systems sidestep this with timeouts, randomization, or partial synchrony.
- The two generals problem shows that perfect agreement over unreliable channels is impossible; systems must tolerate uncertainty.
- Design for the fallacies: assume everything fails, add timeouts, retries, and graceful degradation from the start.