Replication in Distributed Systems
Why Replicate?
Replication keeps copies of data on multiple machines to improve availability (survive node failures), reduce latency (serve reads from nearby replicas), and increase throughput (spread reads across replicas).
The fundamental challenge: keeping replicas consistent while handling concurrent updates and failures.
State Machine Replication (SMR)
Every replica executes the same sequence of deterministic commands in the same order, producing identical state.
Command log: [cmd1] [cmd2] [cmd3] [cmd4] [cmd5]
│ │ │ │ │
Replica A: S0 ──> S1 ──> S2 ──> S3 ──> S4 ──> S5
Replica B: S0 ──> S1 ──> S2 ──> S3 ──> S4 ──> S5
Replica C: S0 ──> S1 ──> S2 ──> S3 ──> S4 ──> S5
All replicas identical at every step.
Requires consensus (Paxos/Raft) to agree on command order. Used by etcd, ZooKeeper, CockroachDB.
Requirement: Deterministic execution. No reading wall clock, no random numbers, no thread races.
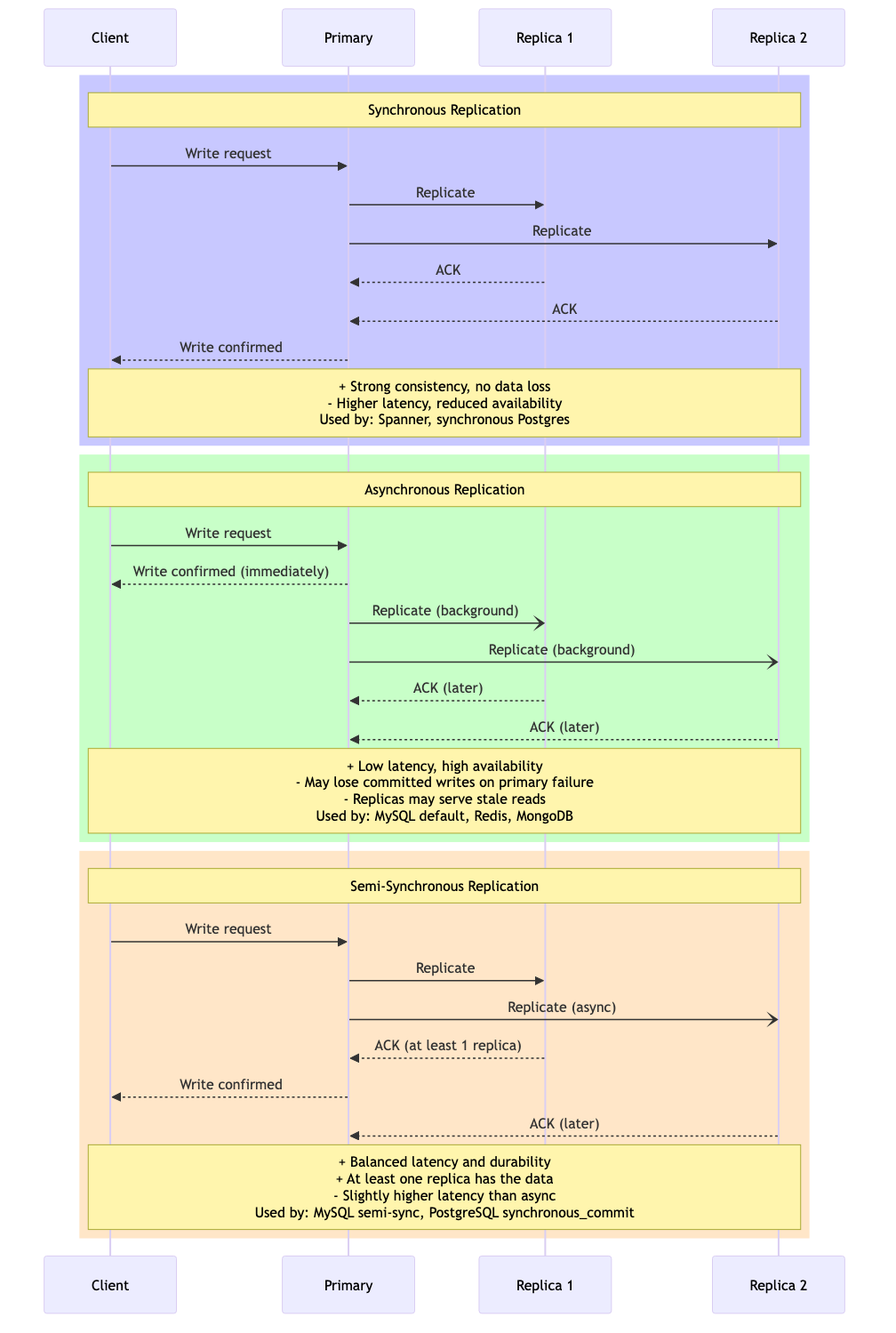
Primary-Backup Replication
One node is designated primary; it processes all writes and forwards updates to backups.
Writes Reads
Client ──────> Primary ──────> Client
│
┌──────┼──────┐
▼ ▼ ▼
Backup Backup Backup
B1 B2 B3
Synchronous: Primary waits for all backups to ACK before responding
Asynchronous: Primary responds immediately, replicates in background
Trade-offs:
- Synchronous: strong consistency but higher latency, reduced availability
- Asynchronous: lower latency but may lose committed writes on primary failure
Used by: PostgreSQL streaming replication, MySQL replication, Redis Sentinel.
Chain Replication
Nodes arranged in a chain. Writes enter at the head, propagate through the chain, and are committed at the tail.
Write Read
│ ↑
▼ │
[Head] ──> [Middle] ──> [Middle] ──> [Tail] ──── response
W W W W+R
Write path: Head → ... → Tail (committed when tail receives)
Read path: Tail only (always sees committed state)
Advantages over primary-backup:
- Reads always go to tail: strongly consistent without quorum
- Write load spread across chain: each node only sends to one other
- Simple failure handling: chain reconfiguration
CRAQ (Chain Replication with Apportioned Queries): Allows reads from any node. If the node has the latest committed version, respond immediately; otherwise, ask the tail for the committed version number.
Quorum Systems
Generalize replication by requiring operations to contact subsets (quorums) of replicas.
N = 5 replicas, W = 3 (write quorum), R = 3 (read quorum)
Write to {A, B, C} Read from {C, D, E}
A: v2 ✓ C: v2 ← latest
B: v2 ✓ D: v1
C: v2 ✓ E: v1
D: v1 (stale) Pick highest version: v2 ✓
E: v1 (stale)
Requirement: W + R > N (guarantees overlap)
STRUCTURE QuorumConfig
n: integer // total replicas
w: integer // write quorum size
r: integer // read quorum size
PROCEDURE NEW_QUORUM(n, w, r) → QuorumConfig or error
IF w + r ≤ n THEN RETURN error("W + R must be > N for strong consistency")
IF w ≤ n / 2 THEN RETURN error("W must be > N/2 to prevent write conflicts")
RETURN QuorumConfig(n, w, r)
// Common configurations
PROCEDURE MAJORITY(n) → QuorumConfig
q ← n / 2 + 1
RETURN QuorumConfig(n, w ← q, r ← q)
PROCEDURE WRITE_HEAVY(n) → QuorumConfig
// Optimize reads at cost of write availability
RETURN QuorumConfig(n, w ← n, r ← 1)
PROCEDURE READ_HEAVY(n) → QuorumConfig
// Optimize writes at cost of read availability
RETURN QuorumConfig(n, w ← 1, r ← n)
Sloppy Quorums and Hinted Handoff
Dynamo-style systems use sloppy quorums: writes can go to nodes not in the preference list during failures. A "hint" is left so the data is forwarded to the correct node when it recovers.
Normal: Write to {A, B, C}
A is down → Write to {B, C, D_hint}
D stores data with hint: "forward to A when A recovers"
A recovers → D sends data to A → D deletes hint
CRDTs (Conflict-free Replicated Data Types)
Data structures designed so concurrent updates can always be merged automatically without conflicts.
Mathematical foundation: CRDTs form a join-semilattice -- a partially ordered set where every pair of elements has a least upper bound (join/merge).
G-Counter (Grow-only Counter)
Each node maintains its own counter. Global value = sum of all.
Node A: [A:3, B:0, C:0] → value = 3
Node B: [A:0, B:5, C:0] → value = 5
Node C: [A:0, B:0, C:2] → value = 2
Merge: [max(3,0,0), max(0,5,0), max(0,0,2)] = [3, 5, 2]
Global value = 10
PN-Counter (Positive-Negative Counter)
Two G-Counters: one for increments, one for decrements. Value = sum(P) - sum(N).
G-Set (Grow-only Set)
Merge = union. Elements can be added but never removed.
OR-Set (Observed-Remove Set)
Each element tagged with a unique identifier. Remove removes specific tags, not the element globally.
Tag ← (node_id, sequence_number)
STRUCTURE ORSet
node_id: integer
counter: integer
elements: map of element → set of Tags
PROCEDURE ADD(set, element)
set.counter ← set.counter + 1
tag ← (set.node_id, set.counter)
IF element NOT IN set.elements THEN
set.elements[element] ← empty set
ADD tag TO set.elements[element]
PROCEDURE REMOVE(set, element)
// Remove all known tags for this element
DELETE element FROM set.elements
PROCEDURE MERGE(set, other)
FOR EACH (elem, other_tags) IN other.elements DO
IF elem NOT IN set.elements THEN
set.elements[elem] ← empty set
FOR EACH tag IN other_tags DO
ADD tag TO set.elements[elem]
PROCEDURE CONTAINS(set, element) → boolean
IF element IN set.elements THEN
RETURN set.elements[element] IS NOT empty
RETURN FALSE
PROCEDURE VALUES(set) → list of elements
RETURN KEYS(set.elements)
LWW-Register (Last-Writer-Wins Register)
Each write tagged with a timestamp. On merge, highest timestamp wins.
Node A writes "alice" at t=10: (value="alice", ts=10)
Node B writes "bob" at t=12: (value="bob", ts=12)
Merge: max timestamp wins → "bob"
Simple but requires synchronized clocks and silently drops concurrent writes.
CRDT for Collaborative Text (RGA / Yjs)
Sequence CRDTs assign unique, totally ordered identifiers to each character, enabling concurrent insertions without conflicts.
User A inserts 'X' after position 2: "HE_X_LLO"
User B inserts 'Y' after position 2: "HE_Y_LLO"
Unique IDs resolve ordering:
If ID(X) < ID(Y): "HEXYL_LO" → consistent on both nodes
Operational Transformation (OT)
Alternative to CRDTs for collaborative editing. Transforms operations against concurrent operations to preserve intent.
Initial state: "ABC"
User 1: Insert('X', pos=1) → "AXBC"
User 2: Delete(pos=2) → "AB" (deletes 'C')
User 1 receives Delete(pos=2):
Transform against Insert('X', pos=1):
Since insert was before delete position, shift: Delete(pos=3)
Result at User 1: "AXB" ✓
User 2 receives Insert('X', pos=1):
No transformation needed (insert pos < delete pos)
Result at User 2: "AXB" ✓
OT vs CRDTs:
| Aspect | OT | CRDTs |
|---|---|---|
| Server requirement | Central server (usually) | Peer-to-peer capable |
| Complexity | Complex transformation functions | Complex data structures |
| Used by | Google Docs | Yjs, Automerge, Figma |
| Metadata overhead | Low | Higher (unique IDs per element) |
Comparison of Replication Strategies
| Strategy | Consistency | Availability | Latency | Use Case |
|---|---|---|---|---|
| SMR (Raft/Paxos) | Strong (linearizable) | Majority required | Higher | Metadata, coordination |
| Primary-Backup (sync) | Strong | Primary + all backups | Higher | Traditional RDBMS |
| Primary-Backup (async) | Eventual | Primary only | Low | Read-heavy workloads |
| Chain Replication | Strong | All nodes in chain | Higher write | Storage systems |
| Quorum (W+R > N) | Strong | Quorum available | Medium | Dynamo-style stores |
| CRDTs | Strong eventual | Any node | Lowest | Collaborative editing |
Real-World Systems
| System | Strategy | Notes |
|---|---|---|
| etcd | SMR via Raft | Kubernetes config store |
| PostgreSQL | Primary-backup (streaming) | Sync/async configurable |
| Amazon DynamoDB | Quorum + sloppy quorum | Tunable consistency |
| Riak | CRDTs + quorum | Built-in CRDT support |
| Google Docs | OT | Server-mediated transforms |
| Figma | CRDTs | Client-side merging |
Key Takeaways
- State machine replication provides the strongest guarantees but requires consensus for every write.
- Quorum systems offer a tunable trade-off between consistency, availability, and latency.
- CRDTs eliminate coordination entirely by designing data structures that always merge, at the cost of metadata overhead and limited operation types.
- Choose your replication strategy based on your consistency needs, failure tolerance requirements, and latency budget.