Memory Management
The OS memory manager allocates physical memory to processes, provides virtual address spaces, and implements demand paging. Most concepts were introduced in the computer architecture topic; this file focuses on the OS perspective.
Address Spaces
Each process has its own virtual address space — a contiguous range of addresses that maps to scattered physical memory via page tables.
64-bit Virtual Address Space (Linux)
0xFFFFFFFFFFFFFFFF ┌──────────────────┐
│ Kernel space │ (top half — shared by all processes)
0xFFFF800000000000 ├──────────────────┤
│ (non-canonical) │ (unused gap)
0x00007FFFFFFFFFFF ├──────────────────┤
│ Stack │ ↓ grows down
│ ... │
│ Memory-mapped │ (shared libraries, mmap)
│ ... │
│ Heap │ ↑ grows up (brk/sbrk)
│ BSS │
│ Data │
│ Text │
0x0000000000000000 └──────────────────┘
Paging (OS Perspective)
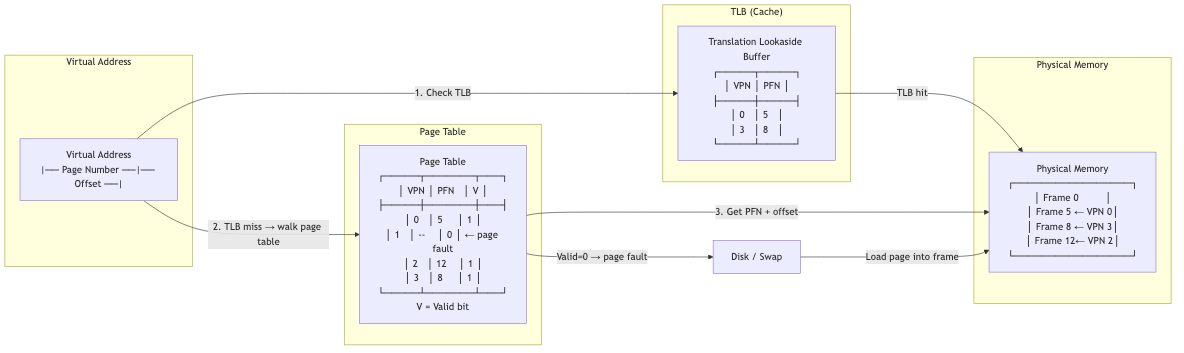
Page Fault Handling
When a process accesses a page not in physical memory:
- Hardware trap: MMU raises a page fault exception.
- Kernel handler: Determines fault type:
- Valid but not resident: Page exists on disk (swapped out). Load it.
- Valid, first access: Allocate a new zero-filled frame (demand zeroing).
- COW fault: Copy the shared page.
- Invalid access: Segmentation fault (SIGSEGV). Kill the process.
- Find a free frame: If none available, evict a page (page replacement).
- Load the page from disk/swap into the frame.
- Update page table: Map virtual page to physical frame.
- Restart the faulting instruction.
Page Replacement Algorithms
FIFO: Replace the oldest page. Simple but suffers from Bélády's anomaly (more frames can cause more faults).
Optimal (OPT): Replace the page that won't be used for the longest time. Impossible to implement (requires future knowledge). Used as benchmark.
LRU: Replace the least recently used page. Good approximation of optimal. Exact LRU is expensive (must track access order for all pages).
Clock (Second-Chance): Circular list of pages with reference bits. On eviction: if R=1, clear R and advance. If R=0, evict. O(1) amortized. The practical approximation of LRU used in most OS.
Clock hand → [R=1] → [R=0] → [R=1] → [R=1] → ...
clear R EVICT!
Enhanced Clock: Consider both reference (R) and dirty (D) bits:
- (0,0): Not referenced, not dirty → best candidate (clean, unused)
- (0,1): Not referenced, dirty → write back first
- (1,0): Referenced, not dirty → recently used, give second chance
- (1,1): Referenced, dirty → worst candidate
Working Set: Keep the set of pages accessed in the last Δ time units in memory. If a page hasn't been accessed in Δ time, it can be evicted.
Page Fault Frequency (PFF): Monitor fault rate per process. If too high, allocate more frames. If too low, reclaim frames.
Thrashing
When the combined working sets of all processes exceed physical memory, the system spends most of its time paging rather than doing useful work.
CPU utilization
^
| /\
| / \
| / \ ← thrashing point
| / \
|/ \_______
+----------------→
Degree of multiprogramming
Detection: High page fault rate + low CPU utilization.
Solutions: Reduce multiprogramming (suspend processes), increase RAM, use working set model to limit active processes.
Memory-Mapped Files
Map a file directly into the virtual address space:
file ← OPEN("data.bin", read_write: true)
mmap ← MEMORY_MAP(file, read_write: true)
// Access mmap[i] as if it were an array
// OS handles page faults to load file pages on demand
Advantages: No explicit read()/write() calls. OS manages caching via page cache. Efficient for random access. Multiple processes can share the same mapping.
Used by: Database buffer pools, shared libraries (.so), the page cache itself.
Copy-on-Write (COW)
On fork(), parent and child share physical pages. Pages are marked read-only. On write:
- Page fault (write to read-only page).
- Kernel copies the page to a new frame.
- Maps the new frame as read-write for the writer.
- Original page remains shared (read-only) for the other process.
Benefit: fork() is nearly free regardless of process size. Most pages are never written (especially in fork+exec pattern).
Huge Pages
Standard pages: 4 KB. Huge pages: 2 MB or 1 GB.
Benefits: Fewer TLB entries needed (each covers more memory). Fewer page table levels traversed. Less page table memory.
Linux: hugetlbfs (explicit), Transparent Huge Pages (THP, automatic).
When to use: Large contiguous allocations — databases, VMs, scientific computing, ML training.
Drawbacks: Internal fragmentation (2 MB granularity). Allocation may fail (need contiguous physical memory). THP can cause latency spikes during compaction.
NUMA-Aware Allocation
In NUMA systems, memory access latency depends on which processor's local memory is accessed.
First-touch policy (Linux default): Page is allocated on the node where the first accessing thread runs.
Interleave: Spread pages across all nodes (good for shared data accessed by all CPUs).
mbind() / numactl: Explicitly control memory placement policy.
Kernel Memory Allocation
Buddy System
Allocate memory in blocks of 2^k pages. On request: find the smallest block ≥ requested size. If too large, split in half. On free, coalesce with buddy if both free.
Request 8KB (2 pages):
32 → split → 16 | 16 → split → 8 | 8 | 16
^
allocated
Advantages: Fast coalescing. O(log n) allocation. Simple. Disadvantages: Internal fragmentation (round up to power of 2).
Linux uses the buddy allocator for page-level allocation.
Slab Allocator
For kernel objects (inodes, task_structs, etc.) that are allocated/freed frequently in the same size.
Slab: A pre-allocated cache of objects of a specific size. Allocation = take from freelist. Deallocation = return to freelist.
Slab cache for "task_struct" (size: 8256 bytes):
Slab 1: [obj][obj][obj][obj][free][free]
Slab 2: [obj][free][free][free][free][free]
SLUB (unqueued allocator): Linux's current default. Simpler than the original slab allocator. Per-CPU freelists for lock-free allocation.
Advantages: No fragmentation (objects are fixed size). Fast (no search, just pop from freelist). Cache-friendly (warm objects).
OOM Killer
When the system runs out of memory and can't reclaim enough:
- Linux invokes the OOM killer.
- Scores each process based on memory usage, oom_score_adj, and other factors.
- Kills the process with the highest score (sends SIGKILL).
- Frees the victim's memory.
Overcommit: Linux allows processes to allocate more virtual memory than physical memory (malloc succeeds even without backing frames). Pages are allocated on first access. If too many pages are accessed → OOM.
vm.overcommit_memory: 0 = heuristic (default), 1 = always overcommit, 2 = never overcommit (strict).
Applications in CS
- Database buffer pools: Custom page replacement (LRU-K, clock sweep). Pinned pages. Direct I/O bypasses page cache.
- JVM/GC: Heap management interacts with OS virtual memory. Large heap → huge pages. GC pauses affected by page faults.
- Containers: Memory limits via cgroups. OOM kills within container scope.
- Virtualization: Two levels of paging (guest virtual → guest physical → host physical). Extended page tables (EPT/NPT) in hardware.
- Embedded systems: No virtual memory (flat physical addressing). Static allocation. Memory protection units (MPU) instead of MMU.