Multi-Team Delivery
Why This Matters at the Director/VP Level
When you were a manager, delivery meant one team shipping one thing. Maybe two things in parallel if your team was big. Now you're looking at three, five, ten or more teams that all need to ship work that somehow fits together. The game changes completely.
The hardest part isn't any individual team's delivery. It's the spaces between teams. The handoffs, the dependencies, the assumptions one team makes about another team's timeline. That's where things break down. And when they break down at scale, you don't just miss one deadline — you create cascading failures that ripple across the entire organization.
Your job isn't to manage each team's delivery. That's what your managers are for. Your job is to create the conditions where multiple teams can deliver together without drowning in coordination overhead.
Business Value
Multi-team delivery done well is a genuine competitive advantage. Here's why executives care about this:
Speed to market. When ten teams can ship a coordinated release in the same time it used to take three teams, you compress time-to-market dramatically. That's revenue earlier, feedback earlier, learning earlier.
Reduced waste. Poor coordination means teams build things that don't integrate, duplicate effort, or sit idle waiting on dependencies. I've seen organizations where 30-40% of engineering capacity was consumed by coordination failure. Think about what that means in dollar terms.
Predictability. The board and your CEO care about whether you can deliver what you said you'd deliver, when you said you'd deliver it. Multi-team delivery discipline is what makes large-scale predictability possible.
Customer impact. Customers don't care about your team structure. They see one product. When teams can't deliver together, customers experience inconsistency, partial features, and integration bugs. Getting multi-team delivery right means the customer experience is coherent.
Talent retention. Engineers hate working in organizations where they're constantly blocked by other teams, where nothing ever ships on time, where coordination meetings eat their days. Good multi-team delivery means engineers spend more time building and less time waiting. They stay longer.
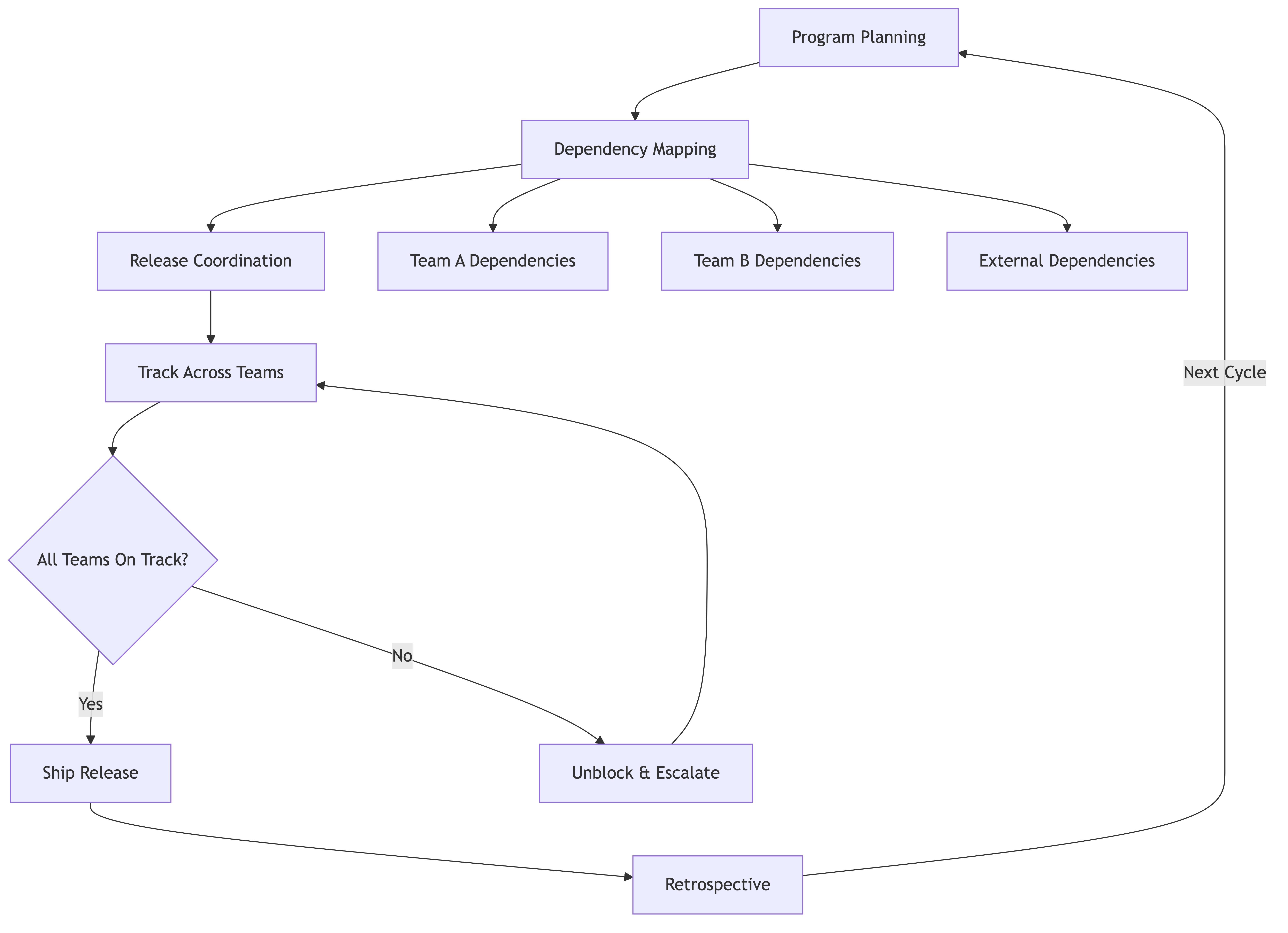
Program Increment Planning
Let's start with program increment (PI) planning. If you've worked in a SAFe environment, you know this term. But even if SAFe isn't your thing (and honestly, most of what SAFe prescribes is too heavy for most organizations), the core concept is sound: get all the teams in a room (or virtual equivalent) and plan together on a regular cadence.
Here's how I think about it practically:
Cadence matters more than perfection. Pick a planning horizon — 8 to 12 weeks works well for most organizations. Every cycle, bring the team leads together. Not to plan every sprint in detail, but to align on the big rocks. What are we trying to accomplish together? Where do teams need things from each other? What's the riskiest part?
Don't over-plan. The biggest mistake I see directors make is turning PI planning into a waterfall exercise with a different name. You're not trying to nail down every task for the next quarter. You're trying to surface dependencies, align on priorities, and build shared understanding. Leave room for teams to figure out the how.
Make it two-way. PI planning isn't you telling teams what to do. It's teams telling each other what they're planning, and everyone collectively identifying risks and conflicts. Your role is to facilitate, arbitrate when there are genuine conflicts, and make the final call on priorities when teams can't agree.
Use objectives, not feature lists. Frame the increment around outcomes. "We need the checkout flow to handle international currencies by end of Q2" is better than a list of 47 features across six teams. Objectives give teams autonomy on approach while keeping everyone aimed at the same target.
Cross-Team Dependency Maps
Dependencies are the silent killers of multi-team delivery. Here's a truth that took me years to internalize: the goal isn't to manage dependencies well. The goal is to eliminate as many as possible.
Visualize them first. You can't fix what you can't see. Every planning cycle, create a dependency map. It doesn't have to be fancy — a whiteboard with team names and arrows works fine. But you need to see the picture. When you've got ten arrows going in and out of one team, that's your bottleneck. That's where delivery will stall.
Categorize dependencies. Not all dependencies are equal:
- Hard technical dependencies: Team A literally cannot start until Team B ships an API. These are real and need sequencing.
- Knowledge dependencies: Team A needs information from Team B but doesn't need their code. These can often be resolved with a conversation.
- Preference dependencies: "We'd like Team B to build this because they know the code better." These are negotiable and often worth pushing through.
Break dependencies through architecture. This is the most powerful lever you have. If two teams always depend on each other, maybe the service boundary is wrong. Maybe you need to introduce an interface or contract that lets them work independently. Investing in architectural decoupling is investing in delivery speed.
Accept some dependencies gracefully. You won't eliminate all of them. For the ones that remain, make them explicit. Put them on the board. Assign owners. Check on them weekly. The worst dependencies are the ones nobody's tracking.
Release Train Coordination
The "release train" metaphor is useful even outside SAFe contexts. The idea is simple: releases happen on a predictable cadence whether or not every feature is ready. The train leaves the station on schedule. If your feature isn't ready, it catches the next train.
Why fixed cadence works. It eliminates the coordination problem of "when are we releasing?" It creates natural integration points. It forces teams to break work into increments that fit the cadence. And it gives stakeholders predictability — they know when to expect new capabilities.
Typical cadences I've seen work:
- Every 2 weeks: Good for mature CI/CD environments, web products
- Monthly: Common for B2B SaaS with customer communication needs
- Quarterly: Usually too long, but sometimes necessary for hardware-adjacent software or heavily regulated environments
Feature flags are your best friend. Release trains work brilliantly when combined with feature flags. Teams can merge code continuously, and you control when features are visible to customers independently of deployment. This decouples "deploy" from "release" and gives you enormous flexibility.
Integration environments matter. With multiple teams shipping to the same product, you need environments where their work comes together before production. Invest in staging environments that mirror production. Invest in automated integration testing. This is infrastructure that pays for itself many times over.
Reducing Coordination Cost
Here's a number that should scare you: as the number of teams grows, the potential communication pathways grow quadratically. Five teams have 10 potential pairwise connections. Ten teams have 45. Twenty teams have 190.
You cannot let coordination cost grow quadratically with team count. You'll grind to a halt. Here's how to fight it:
Align teams to value streams, not components. If Team A owns the frontend, Team B owns the backend, and Team C owns the database, every single feature requires all three teams to coordinate. Instead, organize teams around customer-facing capabilities. A "payments team" that owns the full stack of payment functionality can move independently.
Standardize interfaces. Internal APIs should have the same rigor as external APIs. Versioning, documentation, backward compatibility. When teams can rely on stable contracts, they don't need to coordinate on implementation details.
Reduce meeting load ruthlessly. I've seen organizations where team leads spend 60% of their week in cross-team coordination meetings. That's a sign the organizational structure is wrong, not that you need better meetings. Every recurring cross-team meeting should have a clear purpose, and you should be suspicious of any that have more than eight people.
Invest in async communication. Not everything needs a meeting. Well-written RFCs, architecture decision records, and even simple Slack updates can replace hours of synchronous coordination. Create the culture and tooling for async-first communication.
Empower teams to resolve dependencies directly. If two teams need to coordinate, they should be able to do it without escalating to you. Your job is to create the norms and channels, not to be the switchboard.
Managing Delivery Across 3-10+ Teams
Let me get specific about what changes as you scale:
At 3-5 teams, you can probably still know what every team is doing in reasonable detail. Weekly syncs with your managers, a shared board, and occasional deep-dives are enough. Dependencies are manageable because there aren't too many of them.
At 5-8 teams, you need more structure. You can't track everything yourself. This is where you need clear ownership of cross-team initiatives, some kind of program-level tracking (even a simple spreadsheet), and regular cross-team demos where teams show each other what they've built. You start needing someone — maybe a senior manager or program manager — to help coordinate across groups.
At 8-10+ teams, you need to create organizational layers. Group teams into clusters (sometimes called "tribes" or "pillars") with a senior manager or director owning each cluster. Your job shifts from coordinating teams to coordinating cluster leads. You need formalized planning processes, dedicated program management, and real investment in tooling and dashboards.
The meta-principle: at each scale, your goal is to push coordination down to the lowest level where it can be resolved effectively. Don't centralize what can be distributed. But do centralize what genuinely needs a single point of decision — like release sequencing, major architectural choices, and priority conflicts.
Program Management at Engineering Org Level
Let's talk about program management, because it's a role that engineering leaders often misunderstand or undervalue.
A good program manager (or technical program manager, TPM) at the org level does several things:
They create visibility. They maintain the cross-team view of what's happening, what risks are emerging, and where things are off track. They're the nervous system of your delivery organization.
They facilitate, not dictate. A program manager who tells teams what to do is a project manager cosplaying as an org leader. A good program manager surfaces conflicts, facilitates resolution, and ensures decisions get made. They don't make the technical or priority decisions themselves.
They track the stuff that falls between teams. Integration testing, cross-team dependencies, shared environment issues, release coordination — this is the work that nobody naturally owns. Program managers own it.
They protect engineering time. A great TPM shields engineers from status update meetings, stakeholder management overhead, and process bureaucracy. They gather the information, synthesize it, and present it so engineers don't have to.
When to Use Program Managers
Not every organization needs dedicated program managers. Here's my rough guide:
You probably don't need one if:
- You have fewer than 5 teams
- Your teams are mostly independent (few cross-team dependencies)
- Your managers are experienced and good at coordination
You probably need one if:
- You have 5+ teams working on interconnected deliverables
- You're running a major cross-cutting initiative (platform migration, new product launch)
- Your managers are spending more time coordinating than leading their teams
- Stakeholders keep asking "what's the status?" and nobody has the full picture
You definitely need one (or more) if:
- You have 10+ teams
- You're managing delivery across multiple offices, time zones, or organizations
- You have significant external dependencies (vendors, partners, regulatory bodies)
- Delivery predictability is critical and currently poor
How to hire well for this role: Look for people who combine technical credibility with organizational skill. They need to earn respect from engineers (which means they need to understand the work) while also being able to manage up and out to stakeholders. The best TPMs I've worked with were former engineers who discovered they were more interested in the system-level coordination than the code.
Metrics for Multi-Team Delivery
You need to measure multi-team delivery differently than single-team delivery. Here are the metrics I've found most useful:
Cross-team cycle time. How long does it take for a feature that touches multiple teams to go from idea to production? Compare this to single-team cycle time. The gap tells you how much your coordination is costing you.
Dependency wait time. When a team is blocked by another team, how long does the block last? Track this. It's a direct measure of coordination health.
Integration failure rate. When multiple teams' work comes together, how often does it break? High integration failure rates mean teams aren't communicating enough or your integration testing is insufficient.
Plan accuracy. At the end of each planning increment, how much of what you planned did you actually deliver? This isn't about hitting 100% — that usually means you're sandbagging. 70-80% is healthy. Below 50% consistently means your planning process is broken.
Coordination cost ratio. What percentage of engineering time is spent in coordination activities vs. building? Track this at the org level. If it's creeping up, you need to simplify your organizational structure or invest in tooling.
Lead time distribution. Don't just look at averages. Look at the distribution. A few very long lead times usually point to specific dependency bottlenecks you can address.
Real-World Examples
Example 1: The E-Commerce Platform Rebuild
A VP of Engineering at a mid-size e-commerce company needed to rebuild their monolithic platform into microservices while keeping the existing product running. Eight teams, each taking ownership of a domain (catalog, pricing, cart, checkout, fulfillment, search, recommendations, and user accounts).
The initial approach was a big-bang cutover planned 18 months out. After 6 months, they were hopelessly behind because every team depended on every other team.
What they changed: They introduced the "strangler fig" pattern. Each team could independently extract their domain from the monolith and put a new service behind a feature flag. They set up a shared integration environment and ran both old and new code paths simultaneously. A TPM tracked the cross-team integration points and facilitated weekly dependency reviews.
Result: They completed the migration in 14 months (shorter than the original plan) and had zero customer-facing outages during the transition. The key insight was reducing cross-team dependencies by letting each team move at their own pace with well-defined interfaces.
Example 2: The Feature Factory Problem
A director at a B2B SaaS company had 6 teams, each assigned to different product areas. Quarterly planning was a horse-trading exercise where stakeholders lobbied for their features. Teams churned out features but nothing felt cohesive.
She restructured planning around customer outcomes. Instead of "Team A builds feature X, Team B builds feature Y," she said "This quarter, our organizational objective is to reduce churn in the mid-market segment. Here are the three biggest drivers of churn. Teams, propose what you'd build to address these."
The result was that teams started collaborating because they were aimed at the same goal. Two teams voluntarily combined their planned work into a single, more impactful initiative. Churn dropped 15% in one quarter — more than the previous four quarters combined.
Example 3: Scaling From 4 to 12 Teams
A director was promoted to VP when his org grew from 4 teams to 12 over 18 months (acquisitions plus aggressive hiring). He tried to keep running things the same way — weekly 1:1s with every manager, a single planning session with all teams, one big standup board.
It broke around team 8. He was in meetings from 8am to 6pm. Decisions bottlenecked through him. Teams were frustrated waiting for his input.
His fix: He grouped teams into three pillars of 4 teams each, promoted three senior managers to run them, and shifted his focus to pillar-level coordination. Each pillar ran its own planning and daily coordination. He met with pillar leads weekly and held a monthly all-hands demo. He also hired a TPM to manage the cross-pillar dependencies.
Within two months, delivery velocity increased 40% and his managers reported feeling more empowered and less bottlenecked.
Common Mistakes
Mistake 1: Treating multi-team delivery like scaled-up single-team delivery. You can't just do what one team does, but bigger. The dynamics are fundamentally different. A Scrum-of-Scrums that's just a bigger standup doesn't work. You need different processes, different metrics, different leadership approaches.
Mistake 2: Over-centralizing coordination. If every cross-team decision flows through you, you're the bottleneck. Push decisions down. Create norms and frameworks that let teams coordinate directly.
Mistake 3: Ignoring architecture. Organizational problems are often architecture problems in disguise. If teams can't deliver independently, the answer might not be better coordination — it might be better service boundaries.
Mistake 4: Planning theater. Spending a week doing elaborate PI planning with detailed story-level estimates for 12 weeks of work, then ignoring the plan the moment it's done. Either plan meaningfully or don't plan. Don't do planning theater.
Mistake 5: Not investing in tooling. At scale, you need good CI/CD, good environments, good monitoring, good dashboards. These aren't luxuries. They're the infrastructure that makes multi-team delivery possible. Underinvesting here means over-spending on coordination.
Mistake 6: Measuring teams individually but not collectively. If each team hits their sprint goals but the product doesn't ship, you've optimized the wrong thing. Measure the outcome, not just each team's output.
Mistake 7: Letting dependencies fester. When you see two teams that are always blocked on each other, don't just manage the dependency better. Eliminate it. Change the team structure, change the architecture, change something. Persistent dependencies are a structural problem, not a scheduling problem.
Mistake 8: Copying a framework wholesale. SAFe, LeSS, Spotify model, whatever — these are starting points, not blueprints. Every organization is different. Take the ideas that make sense, adapt them to your context, and be willing to evolve your approach as you learn what works.
Closing Thought
Multi-team delivery is ultimately about creating a system where teams can move fast independently while still producing a coherent result together. That's a design problem — you're designing the organizational system, not just managing it. Think about team boundaries, interfaces, communication channels, and feedback loops the same way a good architect thinks about system design. The best multi-team delivery organizations I've seen look a lot like well-designed distributed systems: loosely coupled, highly cohesive, with clear contracts and good monitoring.
Get this right and you unlock the ability to throw more people at problems without slowing down. Get it wrong and every person you add makes things slower. That's the difference between organizations that scale and organizations that stall.
Common Pitfalls
- Treating multi-team delivery like scaled-up single-team delivery. The dynamics are fundamentally different -- a Scrum-of-Scrums that is just a bigger standup fails because the coordination challenges are qualitatively different, not just bigger.
- Over-centralizing coordination through yourself. If every cross-team decision flows through you, you become the bottleneck and prevent teams from developing the muscle to resolve dependencies directly.
- Ignoring architecture as the root cause of delivery problems. Teams that cannot deliver independently often have an architecture problem disguised as a coordination problem. Better meetings will not fix bad service boundaries.
- Planning theater. Spending a week on elaborate PI planning with story-level estimates and then ignoring the plan wastes everyone's time and breeds cynicism about the planning process.
- Letting persistent dependencies fester. Managing a recurring dependency better is not the same as eliminating it. Persistent dependencies are structural problems that require architectural or organizational changes.
- Measuring teams individually but not collectively. If each team hits their sprint goals but the product does not ship, you have optimized the wrong thing and missed the entire point of multi-team delivery.
Key Takeaways
- Your job is to create conditions where multiple teams deliver together without drowning in coordination overhead -- not to manage each team's delivery directly.
- Program increment planning should surface dependencies and align on big rocks, not plan every sprint in detail.
- The goal with dependencies is to eliminate as many as possible through architectural decoupling, not to manage them better.
- Release trains with fixed cadences and feature flags decouple deployment from release and create natural integration points.
- Coordination cost grows quadratically with team count. Fight it by aligning teams to value streams, standardizing interfaces, and investing in async communication.
- As you scale past 8-10 teams, create organizational layers (pillars/tribes) and push coordination to the lowest level where it can be resolved.
- Program managers create visibility, facilitate resolution, and protect engineering time -- they do not dictate.
- Measure cross-team cycle time, dependency wait time, integration failure rate, and plan accuracy to understand delivery health.