Portfolio Management
Why This Matters at the Director/VP Level
When you were a manager, you had one team and one set of projects. You could hold the whole picture in your head. Now you've got five teams, or ten, or twenty. Each one has their own projects, their own priorities, their own fires. And you have a fixed amount of engineering capacity to spread across all of them.
This is portfolio management, and it's one of the most important — and least taught — skills at the director and VP level. You're essentially an investment manager. Your capital is engineering time, and your job is to allocate it for maximum return. Get this right and your organization punches way above its weight. Get it wrong and you burn millions of dollars building things that don't matter while the things that do matter starve for resources.
The uncomfortable truth is that most engineering organizations are terrible at this. They spread resources too thin, keep zombie projects alive, and avoid the hard conversations about what to stop doing. If you can master portfolio management, you'll have a genuine competitive advantage.
Thinking Like an Investor
The Investment Mindset
Here's a mental model that will serve you well: think of every engineering initiative as an investment. Just like a financial portfolio, you want:
- Diversification: Don't put all your eggs in one basket. A mix of short-term wins and long-term bets.
- Expected returns: Every investment should have a thesis about what return it will generate.
- Risk management: Understand which bets are safe and which are speculative, and size them accordingly.
- Regular rebalancing: Review your portfolio regularly and shift resources based on what you're learning.
This isn't just a metaphor. If you have a 100-person engineering organization at 25M annually. You should be at least as thoughtful about that allocation as you would be managing a $25M investment fund.
Types of Engineering Investments
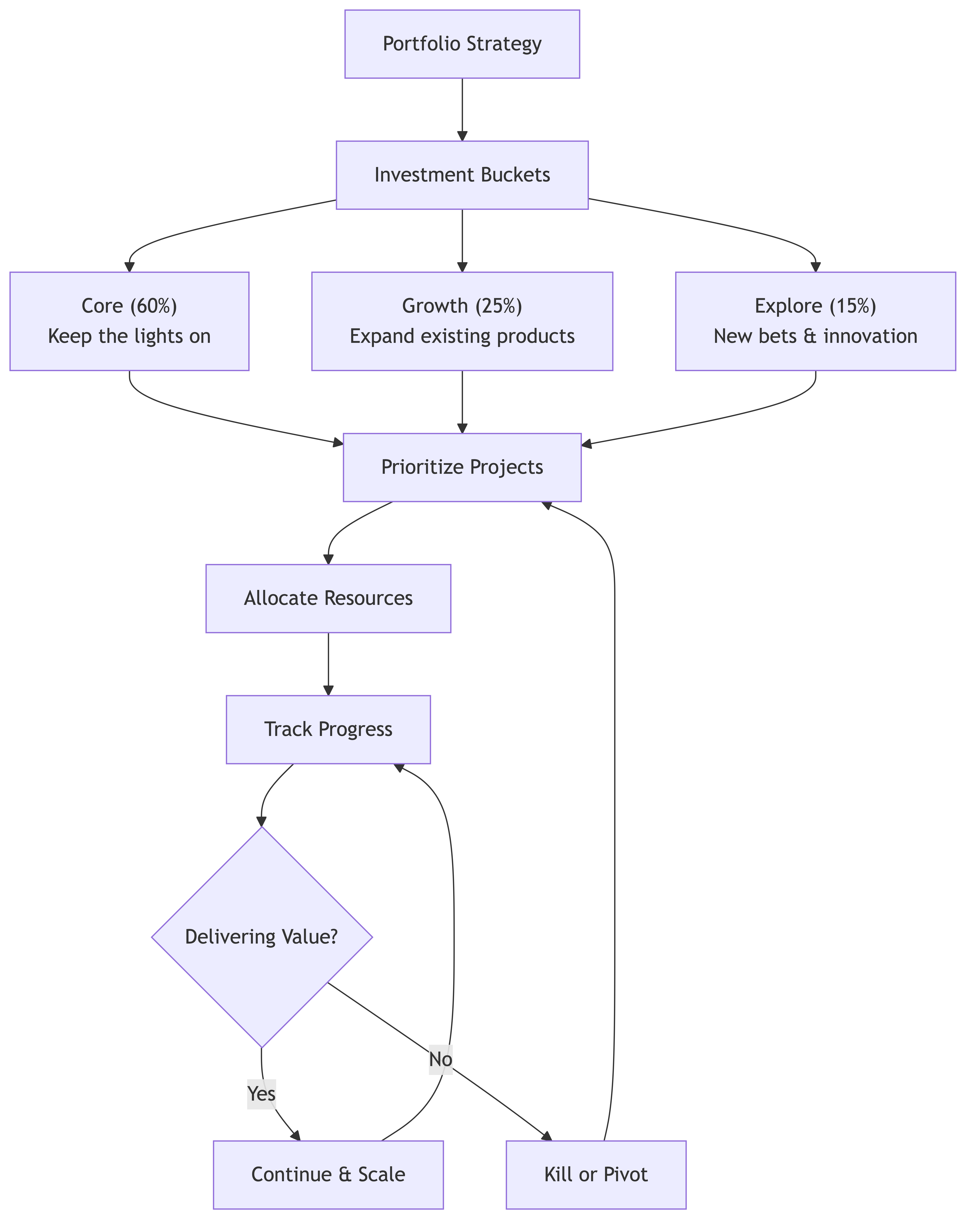
I find it helpful to categorize engineering work into four buckets:
1. Revenue-generating work (typically 40-50% of capacity) Features and products that directly drive new revenue or protect existing revenue. This is what the business cares about most, and it should get the largest share. Examples: new product capabilities, integrations that unlock new markets, features that close competitive gaps.
2. Scaling and reliability work (typically 15-25% of capacity) Infrastructure, performance, and reliability improvements that keep the business running and enable growth. This often gets under-invested because it's not as visible, but neglecting it creates a ticking time bomb. Examples: database migrations, service reliability improvements, capacity planning.
3. Developer productivity work (typically 10-15% of capacity) Internal tools, CI/CD improvements, developer experience investments that make your teams faster. This has compounding returns — a 10% improvement in developer productivity pays dividends every quarter going forward. Examples: build system improvements, testing infrastructure, internal tooling.
4. Innovation and exploration (typically 5-10% of capacity) Experimental work, prototypes, and exploratory projects that might become the next big thing. Not every company can afford this, but those that can should protect it. Examples: new technology evaluations, proof-of-concept projects, hackathon follow-ups.
The percentages I listed are rough guidelines, not rules. Your actual allocation depends on your company's stage, competitive position, and current health of your systems. A growth-stage startup might put 60% into revenue-generating work. A mature company dealing with scale problems might put 40% into scaling and reliability.
Making the Allocation Explicit
The most important thing is to make your allocation explicit and intentional. Most organizations don't do this — they let allocation happen implicitly based on who shouts loudest, which projects have momentum, and what fires are burning this week. That's not management. That's chaos.
At the start of each quarter, write down:
- Here's how many engineering-weeks we have available (after accounting for on-call, vacations, hiring, etc.)
- Here's how we're allocating them across the four buckets
- Here's why
Share this with your leadership team, your peer executives, and your CEO. Make the tradeoffs visible. When someone asks for more resources on a revenue project, you can say "absolutely — which bucket should we take from, and what's the consequence?"
Prioritization Across Teams
The Problem with Local Optimization
Each of your teams has their own backlog, their own stakeholders, and their own view of what's most important. Left to their own devices, each team will optimize for their local priorities. That's natural and not inherently wrong — but it can lead to situations where the organization as a whole is sub-optimized.
Example: Team A is building a new feature that will generate 2M in annual churn. Team C is building internal tooling that will make Teams A and B 20% more productive next quarter. All three are doing important work. But if you could only fund two, which ones would you pick?
This is the kind of decision that only you can make, because only you can see across all the teams.
Frameworks for Cross-Team Prioritization
Framework 1: Weighted Scoring
Create a simple scoring model with the factors that matter most to your business. For example:
| Factor | Weight |
|---|---|
| Revenue impact | 30% |
| Customer retention impact | 25% |
| Strategic alignment | 20% |
| Engineering health impact | 15% |
| Time to value | 10% |
Score each major initiative on each factor, multiply by the weight, and rank. This isn't about getting a precise answer — the numbers are all estimates anyway. It's about forcing a structured conversation about tradeoffs.
Framework 2: The 2x2 Matrix
Plot initiatives on two axes: impact and effort. This gives you four quadrants:
- High impact, low effort: Do these first. These are your quick wins.
- High impact, high effort: Plan these carefully. These are your big bets.
- Low impact, low effort: Do these if you have spare capacity. Nice-to-haves.
- Low impact, high effort: Don't do these. Seriously, just don't.
The 2x2 is crude but effective for fast decisions. I use it most often in the middle of a quarter when new requests come in and I need to make a quick call.
Framework 3: Cost of Delay
For each initiative, ask: "What does it cost us for every week we don't do this?" Some projects have urgent cost of delay (a security vulnerability, a compliance deadline). Others have steady cost of delay (customer churn from a missing feature). Others have low cost of delay (a nice-to-have optimization).
Rank by cost of delay divided by duration. This naturally pushes you toward high-impact, fast-delivery work.
The Role of Dependencies
Cross-team dependencies are the silent killer of portfolio management. Team A can't start their work until Team B finishes a platform change. Team B is blocked on Team C's API. Team C is waiting on a vendor integration.
Map your dependencies explicitly at the start of each quarter. I like to do this on a whiteboard (or a virtual equivalent) with all my team leads in the room. Draw the teams, draw the dependencies, and look for:
- Chains: A depends on B depends on C. These are risky because any delay cascades.
- Bottlenecks: Multiple teams depend on one team. That team becomes the constraint.
- Cycles: A depends on B and B depends on A. These need to be broken by defining interfaces.
Once you see the dependency map, you can make better sequencing decisions and identify where you need to invest in decoupling.
Killing Projects That Don't Deliver ROI
Why This Is the Hardest Part
Let me be direct: killing projects is the single hardest thing you'll do as a director or VP. It's harder than firing someone. It's harder than re-orgs. And it's the thing that separates great portfolio managers from mediocre ones.
Here's why it's so hard:
-
Sunk cost fallacy. "We've already spent six months on this. We can't just throw that away." Yes, you can. Those six months are gone regardless. The only question is whether spending more time will generate a return.
-
People's identities are attached. A team that's been working on a project for months has their identity wrapped up in it. Killing the project feels like you're saying their work didn't matter. You need to handle this with enormous care and empathy.
-
Optimism bias. "We're almost there. Just one more quarter." This is almost always wrong. Projects that are struggling at month six rarely magically succeed at month nine.
-
Political consequences. Maybe the project was the CEO's idea. Maybe the VP of Sales promised it to a customer. Killing it means having uncomfortable conversations with powerful people.
-
Fear of being wrong. What if you kill it and it would have succeeded? This fear is real but overblown. The cost of continuing a failing project is almost always higher than the cost of killing one that might have succeeded.
How to Know When to Kill a Project
Look for these signals:
- The goalposts keep moving. The team keeps redefining what "success" means, usually in a less ambitious direction.
- The original thesis is no longer valid. The market changed, the customer need evolved, or you learned something that undermines the fundamental assumption.
- Opportunity cost is too high. Even if the project might succeed, the engineers could generate more value elsewhere.
- The team has lost conviction. When the people doing the work don't believe in it anymore, that's a powerful signal.
- You can't articulate the ROI. If you can't explain, in one sentence, why this project justifies the investment, it probably doesn't.
How to Kill a Project Well
-
Make the decision clearly and quickly. Don't let a project die a slow death of starvation. That's cruel to the team and wasteful. Make a clear decision and communicate it.
-
Explain the why. Help the team understand that this isn't about their performance — it's about portfolio allocation. The decision to stop is as strategic as the decision to start.
-
Honor the work. Acknowledge what the team accomplished and what was learned. Killing a project doesn't mean the work was worthless. Often you learn things that inform future decisions.
-
Have a plan for the people. Before you announce the project is killed, know where the people are going. "Your project is cancelled and we'll figure out what you do next" is devastating. "Your project is wrapping up, and here's the exciting thing you're moving to" is energizing.
-
Document what you learned. Write a brief post-mortem. Not to assign blame, but to capture lessons. What was the thesis? What did you learn? What would you do differently?
-
Do it regularly. If you've never killed a project, you're not managing your portfolio — you're just accumulating projects. Make portfolio review and pruning a quarterly practice.
Resource Balancing
The Staffing Problem
You have a finite number of engineers and an effectively infinite number of things you could build. How do you decide team sizes and staffing?
First, recognize that there are two types of staffing decisions:
Structural staffing: How many teams do you have, and what is each team's charter? This should change slowly — maybe once or twice a year. Frequent re-orgs are destructive.
Tactical staffing: Within your existing structure, where do you add people, borrow people, or shift focus? This can change quarterly.
Principles for Resource Balancing
Principle 1: Staff to your strategy, not to your backlog.
If your strategy says "retention is the top priority," your retention-related teams should be your largest and best-staffed. It doesn't matter that the new product team has a huge backlog — if retention is the priority, that's where the resources go.
Principle 2: Minimum viable team size.
A team smaller than three engineers is almost never effective. They can't handle on-call, vacations, and context-switching. If you can't afford to put at least three engineers on something, either don't do it or find a way to scope it so a larger team can absorb it.
Conversely, teams larger than eight or nine engineers start to have communication overhead that kills productivity. If a team needs to grow beyond this, split it into two teams with clear boundaries.
Principle 3: Avoid the "one engineer on it" trap.
I see this constantly. "We have one engineer working on that." One engineer can't take vacation, can't get sick, can't get hit by a bus. One engineer has nobody to review their code, nobody to debate design decisions with, nobody to share on-call with. One-person "teams" are almost always a mistake. Either invest properly or don't invest at all.
Principle 4: Borrow, don't permanently transfer.
When you need to surge resources on a high-priority project, consider temporary assignments (4-8 weeks) rather than permanent transfers. This gets you the capacity you need without the disruption of a re-org. Just be honest with the person: "I need you on this for six weeks to help us hit this milestone. Then you're going back to your team."
Principle 5: Protect your platforms.
Platform and infrastructure teams are the easiest to raid when a product team needs help. Resist this temptation. Under-investing in platforms creates compound problems that are much more expensive to fix later. Treat your platform investment like a non-negotiable minimum, not a nice-to-have.
Program-Level Tracking
What to Track
At the portfolio level, you need a different set of metrics than what individual teams track. You're not looking at story points or sprint velocity. You're looking at:
Health metrics:
- Are teams on track against their quarterly OKRs? (Green/yellow/red is fine for this.)
- What's the distribution of engineering time across the four investment buckets?
- How many projects are in each stage (planned, in progress, delivered, measuring results)?
Flow metrics:
- How long does it take from "we decided to do this" to "it's in customers' hands"?
- How many projects are in progress simultaneously? (Too many means you're spreading thin.)
- What percentage of planned work actually gets completed each quarter?
Outcome metrics:
- For completed projects, did they achieve the expected outcome?
- What's the overall ROI of engineering investment this quarter?
- Are we hitting the business metrics that engineering is contributing to?
How to Track It
Keep it simple. I've seen directors build elaborate Jira dashboards with dozens of custom fields and reports that nobody looks at. Here's what actually works:
A one-page portfolio view that lists every major initiative with:
- Name and one-sentence description
- Team responsible
- Current status (on track, at risk, blocked, completed)
- Expected outcome and current progress toward it
- Key risks or dependencies
Update this weekly. Review it with your leadership team. Share it with your executives monthly.
A quarterly portfolio review where you do a deeper assessment:
- Which investments paid off?
- Which didn't?
- What are we learning?
- How should we adjust the portfolio for next quarter?
The Danger of Over-Tracking
More tracking is not better tracking. Every metric you add is a metric someone has to maintain, and a metric that someone might start gaming. Track the minimum set of things that help you make decisions. If a metric isn't changing any decisions, stop tracking it.
I've seen organizations where teams spend 20% of their time on reporting and status updates. That's insane. If your tracking system requires that much overhead, it's broken.
Opportunity Cost Thinking
What Is Opportunity Cost?
Opportunity cost is the value of the best alternative you're giving up when you make a choice. It's the most important concept in portfolio management, and it's the one most engineering leaders ignore.
When you decide to build Feature X, you're not just deciding to spend 500K on Feature Y, Feature Z, the platform improvement, the developer tools upgrade, and everything else you could have done with those resources.
How to Apply It
Every time someone proposes a new project, don't just ask "is this worth doing?" Ask "is this the best use of these resources?"
A project can be genuinely valuable and still be the wrong thing to do if there's something more valuable you could do instead. This is a really hard concept for people to internalize, because it means saying "your project is good, but it's not good enough."
The Trap of Sunk Costs
Opportunity cost also applies to projects you've already started. If you have 10 engineers on a project that's going sideways, the question isn't "should we cancel and waste the 6 months we've already invested?" The question is "what's the best use of these 10 engineers for the next 6 months?"
The past investment is gone. You can't get it back. The only thing you can control is what happens next. This is emotionally brutal but logically clear.
Making Opportunity Cost Visible
One technique I love: when presenting a proposal for a new project, require that the proposal include what you'd stop doing to fund it. "We want to build X. To staff it, we'd pull two engineers from Y and delay Z by a quarter. Here's why that tradeoff is worth it."
This makes the opportunity cost concrete and forces honest conversations about priorities.
Real-World Examples
Example 1: The Portfolio That Was All Big Bets
An engineering org I advised had eight teams, and six of them were working on new product initiatives. The remaining two were split between infrastructure and support. Within a year, the infrastructure was crumbling, deployments were taking days, and incidents were a weekly occurrence. The new product initiatives were also delayed because the unreliable platform kept causing regressions.
The fix was painful: they moved two teams from product work to infrastructure for a full quarter. Product velocity dropped in the short term. But once the platform was stable, all six remaining product teams moved faster than the original eight had. Net result: more product delivery with fewer product-focused teams, because the foundations were solid.
The lesson: portfolio balance isn't just about maximizing revenue work. Under-investing in foundations creates drag that slows everything down.
Example 2: The Project Nobody Would Kill
A company had a "strategic platform" project that had been running for 18 months with a team of twelve. The original plan was nine months. Every quarter, the team said they were "almost done." The VP knew the project was in trouble but was afraid to kill it because the CEO had championed it.
Eventually, the VP did a rigorous analysis: the project had consumed 2M per year. Even if they shipped tomorrow, it would take over two years to break even — and they weren't shipping tomorrow. Meanwhile, the twelve engineers could be generating $6M in value on other projects.
The VP presented this analysis to the CEO with a clear recommendation to stop the project. The CEO wasn't happy, but the math was undeniable. The project was stopped, the team was redeployed, and within two quarters the org was outperforming its targets.
The lesson: make the math visible. It's hard to argue with clear ROI analysis.
Example 3: The Successful Portfolio Rebalance
A mid-stage company was allocating roughly 70% of engineering to new features, 10% to reliability, 10% to developer tools, and 10% to exploration. They were growing fast but customer churn was rising — customers loved the new features but were frustrated by downtime and bugs.
The director proposed a one-quarter rebalance: 40% new features, 35% reliability, 15% developer tools, 10% exploration. It was a tough sell to the product team, who had a long list of features they wanted. But the data was clear: churn was costing more than new features were generating.
After one quarter of the rebalanced portfolio, uptime went from 99.5% to 99.95%, the number of customer-facing bugs dropped by 40%, and churn decreased measurably. They then rebalanced again to 55% features, 20% reliability, 15% dev tools, 10% exploration — a healthier long-term mix.
The lesson: portfolio allocation isn't static. It should respond to what the business needs right now.
Common Mistakes
Mistake 1: Peanut Butter Spreading
Distributing resources equally across all projects regardless of priority. If you have ten projects and a hundred engineers, putting ten on each feels "fair" but is almost always wrong. Some projects deserve thirty engineers. Some deserve three. Some deserve zero.
Mistake 2: Never Killing Anything
If you've never cancelled a project, you're not managing a portfolio — you're running a project graveyard where dead initiatives continue to consume resources because nobody has the courage to officially end them. Make project cancellation a normal, expected part of portfolio management.
Mistake 3: Ignoring Maintenance Costs
Every system you build needs to be maintained. Every service needs to be monitored, patched, and updated. When you approve a new project, you're not just approving the build cost — you're approving an ongoing maintenance tax. Factor this into your portfolio decisions.
Mistake 4: Portfolio of One
Betting everything on a single massive initiative. If it succeeds, you're a hero. If it fails — and large initiatives have a high failure rate — you've wasted a year. Prefer a portfolio with a mix of sizes and risk profiles.
Mistake 5: Letting Urgency Override Importance
Fires and urgent requests constantly pull resources away from important-but-not-urgent work like platform improvements and developer tools. Over time, this creates a doom loop: the platform degrades, which causes more fires, which pulls more resources away from platform work. Break this cycle by protecting a fixed allocation for foundational work regardless of what fires are burning.
Mistake 6: Not Involving Your Teams
Portfolio decisions made in a vacuum by leadership, without input from the teams doing the work, tend to be disconnected from reality. Your team leads have crucial information about feasibility, risk, and opportunity that you need. Include them in the portfolio discussion — not to make the decision by committee, but to make a better-informed decision.
Mistake 7: Treating All Projects as Equal
Not all projects are the same type of investment. A compliance project has a binary outcome (you're compliant or you're not) and non-negotiable timeline. An exploration project has uncertain outcomes and flexible timeline. An optimization project has predictable returns and low risk. Manage each type differently. Don't apply the same tracking, reporting, and success criteria to a compliance sprint and an innovation experiment.
Business Value
Portfolio management is where directors and VPs have their highest-leverage impact on the business. Consider:
- The difference between a well-managed engineering portfolio and a poorly-managed one is typically 30-50% in effective output. That means a 100-person team with good portfolio management delivers what a 130-150 person team delivers with bad portfolio management. At 7.5M-$12.5M in effective value per year.
- Projects that should have been killed but weren't are one of the largest sources of waste in engineering organizations. Industry research suggests that 15-25% of engineering effort goes to projects that ultimately don't deliver meaningful value. For a 3.75M-$6.25M in waste that good portfolio management can recover.
- Opportunity cost is real and measurable. Every quarter you spend engineering resources on the wrong things is a quarter you're not spending them on the right things. In competitive markets, this time can never be recovered. The competitor who allocated resources better gets to market first, captures the customers, and builds the moat.
- The companies that consistently win are not the ones with the most engineers. They're the ones who allocate their engineers most effectively. Portfolio management is the discipline that makes this possible.
When you do this well, you earn something invaluable: the trust of your CEO and board that engineering investment is being managed with the same rigor as financial investment. That trust translates into budget, headcount, and strategic influence. When you do it poorly, you get the dreaded question: "What exactly are all those engineers doing?"
Have a good answer. Better yet, have the data to prove it.
Common Pitfalls
- Peanut butter spreading resources. Distributing engineers equally across all projects regardless of priority feels fair but starves high-impact work and over-invests in low-impact work.
- Never killing projects. Keeping zombie projects alive because of sunk cost fallacy or political fear consumes resources that could generate far more value elsewhere.
- Ignoring opportunity cost. Evaluating projects only on whether they are "worth doing" without asking "is this the best use of these resources" leads to chronically suboptimal allocation.
- Implicit allocation without transparency. Letting resource allocation happen based on who shouts loudest rather than making explicit, intentional decisions shared with leadership creates chaos and misalignment.
- Under-investing in platforms and infrastructure. Raiding platform teams to surge product work creates a doom loop where degraded foundations cause more fires, which pull more resources from foundational work.
- Treating all projects as equal investments. Applying the same tracking, reporting, and success criteria to a compliance sprint and an innovation experiment wastes effort and misses the point of each.
Key Takeaways
- Think of engineering capacity as an investment portfolio with diversified bets across revenue, reliability, developer productivity, and innovation.
- Make resource allocation explicit and intentional at the start of each quarter, and share it with leadership.
- Use prioritization frameworks (weighted scoring, 2x2, cost of delay) to force structured tradeoff conversations.
- Map cross-team dependencies at the start of each quarter and invest in architectural decoupling to reduce them.
- Killing projects is the hardest and most important portfolio management skill. Make it a regular quarterly practice.
- Staff to your strategy, not to your backlog. Avoid one-person teams and protect minimum viable team sizes.
- Track portfolio-level metrics: health, flow, and outcomes -- not just team-level sprint velocity.
- The difference between a well-managed and poorly-managed portfolio is 30-50% in effective engineering output.