Architecture Governance
Why Architecture Governance Matters
Here's a truth that most CTOs learn the hard way: bad architecture doesn't just slow down one team. It slows down the entire company.
When I say architecture governance, I'm not talking about bureaucracy. I'm not talking about an ivory tower committee that reviews every design document and stamps "approved" or "rejected." I'm talking about creating a system where good architectural decisions happen consistently across your entire engineering organization.
At the scale a CTO operates -- hundreds or thousands of engineers, dozens of teams, multiple product lines -- you can't review every technical decision personally. You need a governance system that scales. That's what this chapter is about.
Enterprise Architecture Standards
Enterprise architecture standards are the non-negotiable rules that every team follows. They exist because some decisions need to be consistent across the organization. Not all decisions -- just the ones where inconsistency creates real pain.
What should be standardized:
Communication protocols. How services talk to each other. If team A uses REST, team B uses gRPC, and team C uses SOAP, integration becomes a nightmare. Pick one or two protocols and standardize.
Data formats and schemas. How data is structured and exchanged. This is especially important for event-driven architectures where teams publish and consume events.
Authentication and authorization. How identity and access are managed. This must be consistent for security and user experience.
Observability. How systems are monitored, logged, and traced. If every team uses different tooling, you can't debug cross-service issues.
Deployment. How code gets to production. Consistent deployment pipelines reduce risk and make it possible to enforce security and compliance requirements.
API design. How APIs are designed, versioned, and documented. Consistent APIs reduce the cognitive load for anyone integrating across teams.
What should NOT be standardized:
Internal implementation details. How a team structures their code internally is their business, as long as they meet the interface contracts.
Testing strategies. Different types of systems need different testing approaches. Let teams choose what works for their context.
Development workflow. Some teams do trunk-based development, others use feature branches. As long as they ship reliably, this is a team decision.
Choice of libraries within a language. If you've standardized on Python, don't also mandate which HTTP library every team uses. That's over-governing.
The key principle:
Standardize the interfaces between teams. Give autonomy on what happens inside teams. This gives you consistency where it matters and freedom where it doesn't.
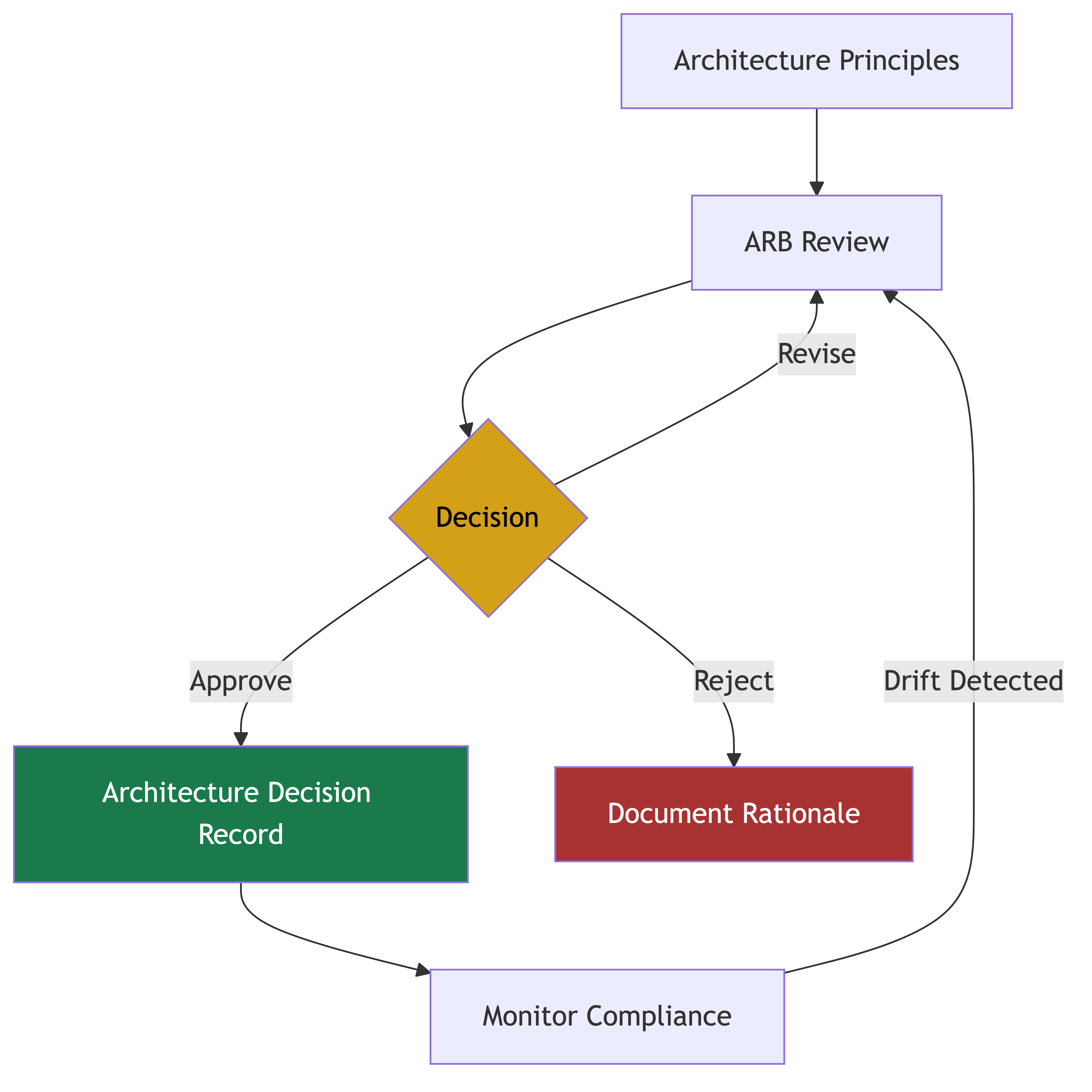
The Architecture Review Board (ARB)
The ARB is one of the most important governance mechanisms a CTO has. It's also one of the most frequently done poorly.
What an ARB should be:
A lightweight, collaborative forum where significant architectural decisions are reviewed, discussed, and aligned with the organization's technical direction.
What an ARB should NOT be:
A gatekeeping body that creates bottlenecks, stifles innovation, and makes teams feel like they need permission to do their jobs.
The difference between these two outcomes is entirely in how you set it up.
ARB composition:
- CTO or VP of Architecture (chair)
- Principal/Distinguished Engineers from major product areas
- Security lead (because security implications exist in every architecture decision)
- Infrastructure lead (because every system runs on something)
- Rotating members from different teams (this prevents the ARB from becoming disconnected from reality)
Keep it small -- six to eight people maximum. More than that and meetings become unwieldy.
What comes to the ARB:
Not everything. Use a clear threshold:
- New services or systems that will be long-lived
- Changes to shared infrastructure
- Adoption of new programming languages or frameworks
- Significant changes to data architecture
- Cross-team integration patterns
- Decisions that are expensive or difficult to reverse
Use a simple one-page template for submissions:
Architecture Decision Proposal
1. Context: What problem are we solving?
2. Decision: What are we proposing?
3. Alternatives: What else did we consider and why not?
4. Consequences: What are the trade-offs?
5. Impact: Which teams and systems are affected?
How to run an effective ARB:
Timebox ruthlessly. Each review gets 30 minutes maximum. If it needs more, break it into multiple sessions.
Decide or defer, never block. At the end of each review, the outcome is one of: approved, approved with modifications, or deferred for more information. Never "rejected and go back to the drawing board" -- that's demoralizing and often unnecessary.
Publish all decisions. Every ARB decision should be documented and accessible to the entire engineering organization. Transparency builds trust and helps teams learn the organization's architectural preferences.
Track implementation. An ARB decision that nobody follows is worse than no decision at all. Have a lightweight tracking mechanism to ensure decisions are actually implemented.
Making the ARB feel collaborative, not bureaucratic:
The single most important thing: the ARB should feel like a group of experienced architects helping a team make a better decision, not like a panel of judges deciding a team's fate.
Ask questions like "Have you considered..." not "You should have thought about..." The difference in framing is everything.
System Design Principles at Scale
When you're governing architecture across a large organization, you need design principles that are specific enough to be useful but general enough to apply broadly.
Principle 1: Design for failure
At scale, everything fails. Disks, networks, services, entire data centers. Your architecture needs to assume failure and handle it gracefully. This means circuit breakers, retries with backoff, graceful degradation, and chaos engineering.
Principle 2: Minimize blast radius
When something fails, it should affect the smallest possible portion of your system. This means isolation -- between services, between tenants, between regions. A bug in the recommendation engine should never take down the checkout flow.
Principle 3: Make it observable
You can't manage what you can't see. Every system should emit metrics, logs, and traces that allow you to understand its behavior in production. Not just error cases -- normal behavior too, so you can spot anomalies.
Principle 4: Design for evolution
Requirements change. Scale changes. Technology changes. Your architecture should accommodate change without requiring a rewrite. This means loose coupling, well-defined interfaces, and modular design.
Principle 5: Keep it simple
The best architecture is the simplest one that meets the requirements. Every additional layer, every additional service, every additional technology adds operational cost. Complexity is not a sign of sophistication -- it's usually a sign of inadequate design.
Principle 6: Data is the hardest part
Most architectural mistakes are data mistakes. Where data lives, how it flows, who owns it, how it's kept consistent -- these decisions are the hardest to change and the most important to get right.
Managing Complexity at Scale
Complexity is the silent killer of engineering organizations. It accumulates slowly, and by the time you notice it, it's deeply embedded.
Sources of complexity:
Service proliferation. Teams keep creating new services, and before you know it, you have 500 services and nobody understands how they fit together. I've seen organizations where the service topology diagram looks like a bowl of spaghetti.
Technology sprawl. Different teams adopt different technologies, and suddenly you're running five different databases, three message queues, and four programming languages. Each one has its own operational overhead, its own talent requirements, and its own failure modes.
Integration complexity. As the number of services grows, the number of integration points grows exponentially. N services can have up to N*(N-1)/2 integration points. That's a lot of surface area for things to go wrong.
Organizational complexity. Conway's Law is real -- your architecture mirrors your org structure. If your org structure is complex and unclear, your architecture will be too.
How to manage complexity:
Set service limits. Not a hard cap, but a strong expectation. "Before creating a new service, justify why this can't be a module within an existing service." This forces teams to think about whether a new service is genuinely needed.
Enforce technology standards. Limit the number of approved programming languages, databases, and infrastructure components. Each new technology needs to earn its place.
Create platform teams. Platform teams provide shared infrastructure and tooling that product teams use. This reduces the amount of undifferentiated work each product team does and keeps infrastructure consistent.
Invest in documentation. Not verbose documentation that nobody reads. Concise, living documentation that shows how systems connect, who owns what, and how data flows.
Regular architecture reviews. Not just for new systems, but for existing ones. Schedule periodic reviews of your architecture to identify areas of unnecessary complexity.
Sunset aggressively. Old systems, deprecated services, unused features -- if they're not providing value, kill them. Every system that exists requires maintenance, monitoring, and cognitive load.
When to Standardize vs. Allow Autonomy
This is one of the hardest judgment calls a CTO makes. Standardize too much and you stifle innovation. Standardize too little and you get chaos.
The standardization spectrum:
Must standardize (interfaces):
- Service-to-service communication protocols
- Authentication and authorization
- Data exchange formats
- Security requirements
- Compliance requirements
- Deployment and release processes
Should standardize (platform):
- Cloud provider and core infrastructure
- Primary programming languages
- Observability stack
- CI/CD tooling
- Core data infrastructure
Can standardize (guidelines):
- API design conventions
- Code organization patterns
- Testing approaches
- Development workflow
Should NOT standardize (team autonomy):
- Internal code structure
- Library choices within approved languages
- Sprint rituals and team processes
- IDE and development environment
- Internal data structures
The decision framework:
Ask two questions about any potential standardization:
-
Does inconsistency here cause real pain? If team A uses Postgres and team B uses MySQL, does that actually cause problems? Maybe -- if teams need to share data or if you can't hire enough DBAs for both. Maybe not -- if teams are independent and self-sufficient.
-
Does standardization here kill a meaningful advantage? If one team has deep expertise in a particular technology and standardization forces them to use something they're less effective with, is the consistency worth the productivity loss?
When the answer to question 1 is yes and question 2 is no, standardize. Otherwise, don't.
Bad Architecture Slows the Entire Company
Let me tell you what bad architecture actually costs, because too many leaders treat it as a purely technical concern.
Slow feature delivery
When the architecture is tangled, every feature takes longer. Engineers spend more time understanding the existing system, navigating dependencies, and working around architectural limitations than they spend building the feature itself. I've seen teams where 70% of development time was spent dealing with architectural problems rather than building value.
Reliability problems that cost revenue
Bad architecture causes outages. Tight coupling means a failure in one system cascades to others. Missing observability means problems take longer to diagnose. These outages cost real money -- lost transactions, customer churn, SLA penalties, and emergency response costs.
Inability to scale
When the architecture wasn't designed for scale, you hit walls. And those walls always appear at the worst possible time -- when business is growing and you should be capitalizing on momentum, not firefighting infrastructure problems.
Talent loss
Good engineers don't want to work with bad architecture. They'll tolerate it for a while, but eventually they leave for companies with cleaner systems. This creates a vicious cycle: the best people leave, the architecture gets worse, and it becomes harder to attract good people.
Slow onboarding
New engineers take longer to become productive in a complex, poorly architected system. Instead of weeks, onboarding takes months. This is an invisible cost that most organizations don't measure but should.
The business case for architecture governance:
All of these costs are quantifiable. If your average feature takes 30% longer because of architectural problems, that's 30% more labor cost for every feature. If you have 100 engineers at an average fully loaded cost of 7.5 million per year in wasted effort. That number gets the CFO's attention.
Technical Decision-Making at Org Level
As CTO, you need a system for how technical decisions get made across the organization. Without one, decisions happen inconsistently -- some teams over-deliberate, others make hasty choices, and nobody learns from anyone else's experience.
Decision categories:
Strategic decisions (CTO makes or approves):
- Platform bets
- Major architecture changes
- Technology standards
- Build vs. buy for significant investments
- Vendor selection for critical systems
Tactical decisions (teams make, ARB reviews):
- New service design
- Cross-team integration approaches
- Data model changes that affect multiple teams
- Adoption of new technologies within approved standards
Local decisions (teams make independently):
- Internal implementation choices
- Library selection within approved languages
- Testing strategy
- Performance optimization approaches
Architecture Decision Records (ADRs):
ADRs are lightweight documents that capture significant technical decisions. They're one of the best governance tools I know because they:
- Force clear thinking (writing a decision down reveals fuzzy thinking)
- Create institutional memory (future engineers can understand why decisions were made)
- Enable learning (you can review past decisions and learn from outcomes)
A simple ADR template:
Title: [Short description]
Date: [When decided]
Status: [Proposed | Accepted | Deprecated | Superseded]
Context: Why is this decision needed?
Decision: What did we decide?
Consequences: What are the trade-offs?
Make ADRs mandatory for ARB-level decisions and encouraged for team-level decisions. Store them in a searchable, accessible location.
Real-World Examples
Example 1: The service explosion
A company grew from 20 to 200 engineers in three years without architecture governance. They went from 10 services to 350. Nobody could draw the system architecture. Deploy times went from minutes to hours because of cascading dependencies. Incident resolution time tripled because nobody could trace failures across services.
The new CTO implemented an ARB, froze new service creation for six months, and consolidated services where possible. They ended up at 120 services -- still a lot, but each one had a clear purpose and owner. Deploy times dropped by 60% and incident resolution time was cut in half.
Example 2: The technology zoo
A CTO at a mid-size company inherited an environment with seven programming languages, four database technologies, three cloud providers, and two container orchestration platforms. Every team had chosen what they liked, and nobody had said no.
The CTO didn't mandate an immediate switch. Instead, they established standards for new projects (two languages, one cloud, one orchestration platform) and created a gradual migration plan for existing systems. Within two years, they'd reduced to three languages, two databases, one cloud, and one orchestration platform. Operational costs dropped by 35% and the team needed fewer specialized ops engineers.
Example 3: The ARB that worked
A CTO set up an ARB that met weekly for one hour. Each meeting reviewed two to three proposals. The key to its success was the culture: the ARB was positioned as "the place where architects help each other," not "the place where ideas go to die." Senior engineers actually looked forward to presenting because they got valuable feedback from experienced peers.
Over 18 months, the ARB reviewed 140 proposals. Only three were sent back for significant rework. The rest were either approved as-is or approved with minor modifications. The real value wasn't the reviews -- it was the consistency and cross-pollination of ideas.
Common Mistakes
Mistake 1: Over-governing
Creating so many standards and review processes that teams can't move. If your ARB has a two-month backlog, you're a bottleneck, not a governance body.
Mistake 2: Under-governing
Letting every team make independent decisions about everything. This feels empowering but creates chaos at scale. You end up with incompatible systems that can't work together.
Mistake 3: Governance without enforcement
Setting standards that nobody follows. This is worse than no standards at all because it creates a false sense of order. If you set a standard, enforce it. If you can't enforce it, don't set it.
Mistake 4: Static governance
Never updating your standards and processes as the organization evolves. What works for 50 engineers doesn't work for 500. Review and update your governance model regularly.
Mistake 5: Governance by committee
Having too many people involved in every decision. Governance bodies should be small and decisive. If your ARB has 15 members, it's a town hall meeting, not a decision-making body.
Mistake 6: Ignoring Conway's Law
Designing your ideal architecture without considering your organizational structure. Architecture and org structure are deeply linked. If you want to change your architecture, you may need to change your organization first.
Mistake 7: All stick, no carrot
Making governance feel like policing rather than enabling. The best governance systems make it easier for teams to do the right thing, not just harder to do the wrong thing. Provide great platform tooling, templates, and examples that embody your standards.
Business Value
Architecture governance creates enormous business value, even though it's often seen as purely technical:
-
Faster feature delivery. Clean, well-governed architecture enables teams to ship features faster. This is directly measurable -- track the time from idea to production.
-
Lower operational cost. Fewer technologies, more consistent systems, and better observability reduce the cost of running your infrastructure. This shows up directly on the P&L.
-
Better reliability. Governed architecture with clear failure isolation means fewer outages. Fewer outages means more revenue and lower emergency response costs.
-
Faster scaling. When you need to enter a new market or handle a traffic spike, well-architected systems scale smoothly. Poorly architected ones require emergency re-engineering.
-
Reduced talent risk. Standardized technologies mean you can move engineers between teams more easily. If someone leaves, it's easier to find a replacement. This reduces key-person risk.
-
Faster onboarding. New engineers become productive faster in a consistent, well-documented architecture. At scale, this saves millions in ramp-up time.
-
Better M&A integration. When you acquire a company, integrating their technology is vastly easier if you have clear architectural standards. This can be the difference between a six-month integration and a two-year one.
Architecture governance isn't about control. It's about creating the conditions where hundreds of engineers can build cohesive, high-quality systems together. That's a capability worth investing in.
Common Pitfalls
-
Over-governing to the point of bottleneck. Creating so many review processes and standards that teams cannot ship. If your ARB has a multi-month backlog, you are a bottleneck, not a governance body.
-
Under-governing and calling it empowerment. Letting every team make fully independent technology decisions feels empowering but produces incompatible systems that cannot work together at scale.
-
Setting standards you cannot or will not enforce. Unenforced standards create a false sense of order and teach the organization that governance can be ignored. If you set a standard, enforce it.
-
Ignoring Conway's Law. Designing an ideal architecture without considering the organizational structure guarantees misalignment. Architecture and org structure are deeply linked, and changing one often requires changing the other.
-
Making the ARB feel like a tribunal. When the Architecture Review Board is perceived as a panel of judges rather than a collaborative forum, teams avoid it, hide decisions, and morale suffers.
-
Never updating governance as the organization scales. What works for 50 engineers does not work for 500. Governance models must evolve with the organization or they become irrelevant or actively harmful.
Key Takeaways
-
Architecture governance is not bureaucracy. It is a system for ensuring good architectural decisions happen consistently across the entire engineering organization.
-
Standardize the interfaces between teams while giving autonomy on what happens inside teams. This provides consistency where it matters and freedom where it does not.
-
The ARB should be small (six to eight people), lightweight, and collaborative. Its purpose is helping teams make better decisions, not blocking them.
-
Use Architecture Decision Records to force clear thinking, create institutional memory, and enable the organization to learn from past decisions.
-
Complexity is the silent killer of engineering organizations. Manage it through service limits, technology standards, platform teams, and aggressive sunsetting of unused systems.
-
Bad architecture has quantifiable business costs: slower feature delivery, reliability problems, inability to scale, talent loss, and slow onboarding. Frame these costs in dollar terms to get executive attention.
-
Decision-making authority should be explicitly categorized: strategic decisions at the CTO level, tactical decisions reviewed by the ARB, and local decisions made independently by teams.