Cloud and Infrastructure Strategy
Why This Matters at the CTO Level
Infrastructure used to be someone else's problem. You bought servers, put them in a rack, and forgot about them until something caught fire. Those days are gone. Cloud infrastructure is now a strategic decision that affects your cost structure, your competitive agility, your security posture, and your ability to scale. And as CTO, you're the one who owns that decision.
Here's a number that should keep you up at night: for most software companies, cloud infrastructure is the second-largest line item after payroll. At scale, it can be tens of millions of dollars annually. And unlike payroll, where you can see people doing work, cloud spend is abstract, distributed, and shockingly easy to waste.
But infrastructure isn't just about cost. It's about capability. The right infrastructure strategy lets you enter new markets in weeks instead of months. The wrong one means you're fighting fires instead of shipping features. Your infrastructure is either a competitive advantage or an anchor dragging you down.
This section covers infrastructure strategy at the CTO level — the strategic decisions, the vendor relationships, the financial models, and the organizational structures that determine whether your infrastructure serves the business or just consumes its resources.
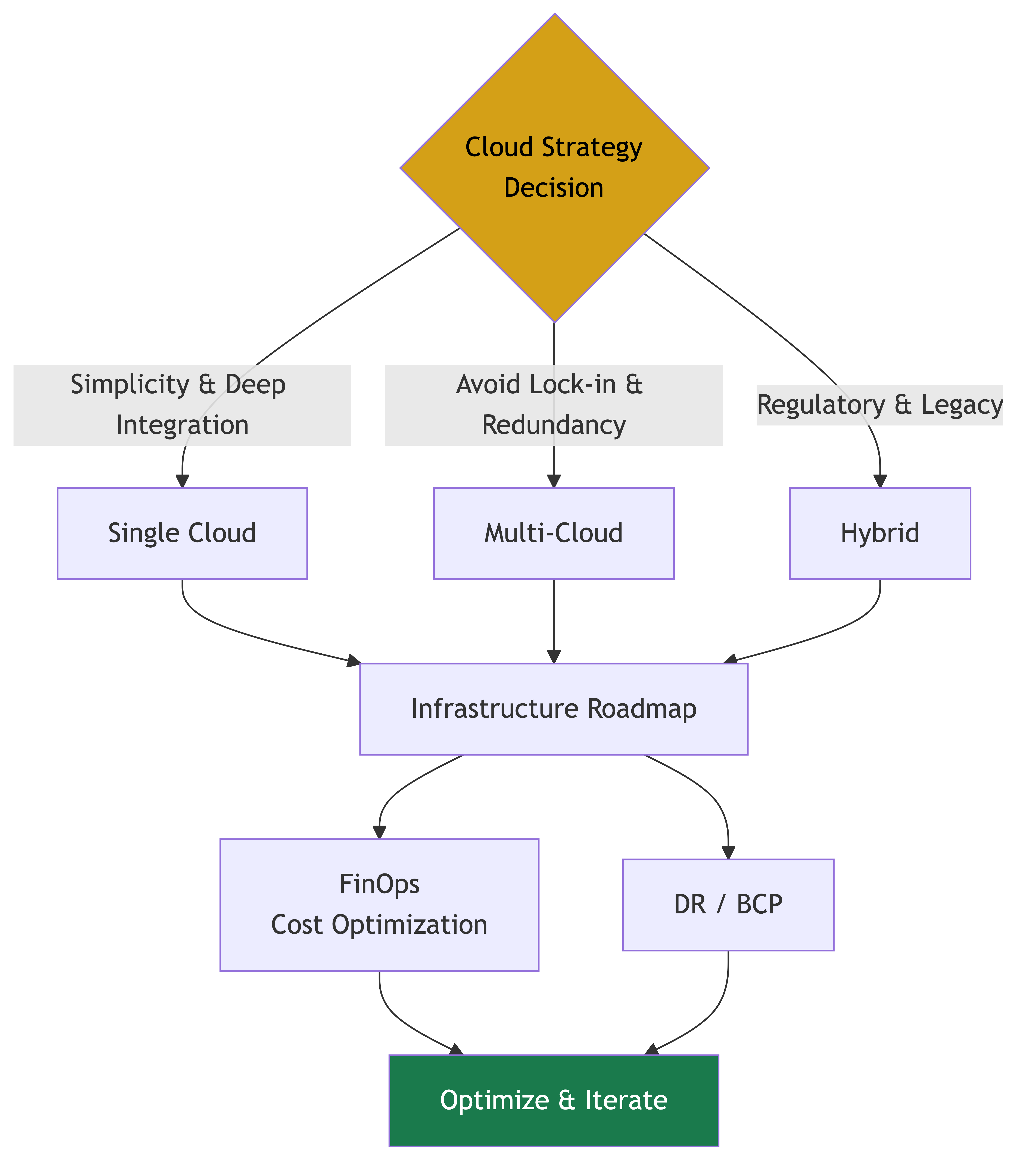
Multi-Cloud vs. Single Cloud vs. Hybrid
This is one of the most debated decisions in infrastructure strategy, and it's one where the conventional wisdom is often wrong.
Single Cloud: The Default Choice
For most companies, single cloud is the right answer. Pick one cloud provider (AWS, Azure, GCP), go deep, and don't look back. Here's why:
Depth of integration. Cloud providers offer hundreds of services that work seamlessly together. When you go multi-cloud, you either use the lowest common denominator (containers and VMs only, missing out on managed services) or you maintain two versions of everything.
Team expertise. Your engineers become experts in one platform. Multi-cloud means either everyone learns multiple platforms (poorly) or you have separate teams for each cloud (expensive and siloed).
Negotiating leverage. Counterintuitively, committing to a single vendor can give you more negotiating power, not less. Vendors give their best pricing to committed customers. A $10M annual commitment gets you a dedicated account team, executive sponsors, and pricing that multi-cloud customers never see.
Operational simplicity. One set of IAM policies. One set of monitoring tools. One set of deployment patterns. One set of compliance certifications. Multi-cloud doubles or triples all of this operational overhead.
When Multi-Cloud Actually Makes Sense
Multi-cloud is sometimes the right answer, but only for specific reasons:
Regulatory requirements. Some jurisdictions or industries require data to be processed by specific providers or in specific regions that your primary cloud doesn't serve.
Acquisition integration. You acquire a company running on a different cloud. Migrating them immediately is risky and expensive. Running multi-cloud during a transition is pragmatic.
Best-of-breed services. GCP has the best ML/AI platform. AWS has the broadest set of services. Azure has the best Microsoft ecosystem integration. If you have a specific workload that one provider handles dramatically better, it might justify the multi-cloud complexity for that workload.
Genuine business continuity concerns. If your business literally cannot survive a major cloud provider outage (which is rare — most cloud outages are regional, not global), multi-cloud failover might be justified. But the cost is enormous, and you need to actually test it regularly.
Hybrid: On-Premises Plus Cloud
Hybrid infrastructure — running some workloads on-premises and some in the cloud — is common in large enterprises and is sometimes a genuine requirement:
- Data sovereignty: Some data can't leave your premises
- Latency requirements: Edge computing or factory-floor workloads
- Legacy systems: Mainframes and legacy systems that can't be easily migrated
- Cost optimization: Very predictable, high-volume workloads can be cheaper on owned hardware
The key with hybrid is having a clear strategy for what goes where and why. Don't let it become "we couldn't decide, so we did both." Every workload should have a rationale for its placement.
Infrastructure Roadmap
Your infrastructure roadmap is a multi-year plan that aligns infrastructure investments with business strategy. It should be a living document, reviewed quarterly and updated as business needs change.
Building the Roadmap
Start with business strategy. What markets are you entering? What products are you launching? What growth rate are you planning for? Infrastructure plans that don't connect to business plans are just technical wish lists.
Map current state honestly. Where are your systems today? What's the current architecture? What are the bottlenecks, risks, and technical debt? You can't plan a journey without knowing your starting point.
Identify capability gaps. What can your infrastructure do today? What does the business need it to do in 12, 24, 36 months? The gap between these is your roadmap.
Prioritize ruthlessly. You can't do everything at once. Prioritize based on business impact, risk reduction, and dependencies. A common framework:
- Must do: Things that will cause business failure if not addressed (capacity limits, security vulnerabilities, compliance requirements)
- Should do: Things that significantly improve capability or reduce cost (platform modernization, tooling improvements)
- Nice to do: Things that would be beneficial but aren't critical (optimization, nice-to-have features)
Plan in phases. Break the roadmap into quarterly milestones. Each quarter should deliver tangible value, not just progress toward a distant goal. Nobody wants to hear "we'll see the benefits in two years." Ship value incrementally.
Common Roadmap Elements
- Cloud migration: Moving workloads from on-premises or legacy systems to cloud
- Containerization: Moving from VMs to containers for better density and portability
- Platform standardization: Reducing the number of platforms, frameworks, and tools
- Observability: Building comprehensive monitoring, logging, and tracing
- Security hardening: Implementing zero-trust, encryption, access controls
- Cost optimization: Right-sizing, reserved instances, architecture improvements
- Scaling preparation: Building for the next order of magnitude of growth
Cost Optimization: FinOps at the CTO Level
Cloud cost management at the CTO level isn't about finding idle EC2 instances. It's about building an organizational capability for understanding, managing, and optimizing cloud spend as a strategic lever.
The FinOps Framework
FinOps — cloud financial management — has matured into a discipline with its own frameworks and practices. At the CTO level, you need to establish:
Visibility. Everyone who spends money on cloud should be able to see what they're spending. Implement tagging standards so every resource can be attributed to a team, product, and environment. If you can't tell where the money is going, you can't manage it.
Accountability. Each team should know their cloud spend and be accountable for it. This doesn't mean making every engineer obsess over cost — it means making cost a consideration in architectural decisions, just like performance and reliability.
Optimization. Continuous improvement of cloud spend efficiency. This operates at multiple levels:
- Resource optimization: Right-sizing instances, shutting down unused resources, using spot/preemptible instances for appropriate workloads
- Rate optimization: Reserved instances, savings plans, committed use discounts, enterprise agreements
- Architecture optimization: Redesigning systems for cost efficiency (serverless for spiky workloads, better caching, data lifecycle management)
Unit Economics of Infrastructure
The metric that matters most for infrastructure cost isn't total spend — it's cost per unit of business value. Define your unit and track it:
- Cost per transaction: For payment or e-commerce platforms
- Cost per monthly active user: For consumer products
- Cost per API call: For API-first businesses
- Cost per GB processed: For data-intensive businesses
When your total cloud bill goes up 30% but your cost per transaction goes down 10%, that's a good story. When both go up, you have a problem.
Negotiating Cloud Contracts
As CTO, you'll negotiate enterprise agreements with cloud providers. Some things I've learned:
Commit to what you'll actually use. Enterprise discount programs (AWS EDP, Azure MACC, GCP CUDs) require spending commitments in exchange for discounts. Don't over-commit to get a bigger discount — you'll end up paying for capacity you don't use.
Negotiate beyond pricing. The best enterprise agreements include more than just discounts:
- Credits for new services or experimentation
- Dedicated solution architects
- Priority support with faster SLAs
- Training credits for your team
- Co-marketing opportunities
Time your negotiations. Cloud vendors have quarterly and annual targets. Negotiating at the end of their fiscal quarter or year often yields better terms.
Get multiple quotes. Even if you're committed to a single cloud, having a credible alternative gives you leverage. You don't need to actually plan to use GCP to use a GCP proposal as leverage in your AWS negotiation.
Bring your finance team. Cloud negotiations are fundamentally financial transactions. Have your finance team involved from the start. They'll catch things you miss and bring credibility to the negotiation.
Disaster Recovery and Business Continuity Planning
Disaster recovery (DR) is one of those things that feels like a waste of money until you need it, at which point it's the most important investment you ever made.
Defining Your Requirements
RTO (Recovery Time Objective): How long can you be down before the business suffers unacceptable damage? For an e-commerce site during Black Friday, the answer might be minutes. For an internal HR system, it might be hours or days.
RPO (Recovery Point Objective): How much data can you afford to lose? If your RPO is zero, you need synchronous replication. If you can tolerate losing the last hour of data, you have more affordable options.
These are business decisions, not technical decisions. The CEO and CFO should weigh in. The difference between a 1-hour RTO and a 1-minute RTO might be a 10x cost difference. Make sure the business is making that tradeoff explicitly.
DR Architecture Patterns
Backup and restore. Cheapest option. You back up data regularly and restore it to new infrastructure when needed. RTO: hours to days. RPO: time since last backup. Appropriate for non-critical systems.
Pilot light. Core infrastructure is always running in a secondary region (database replicas, core networking), but application servers aren't provisioned until needed. RTO: tens of minutes. Moderate cost.
Warm standby. A scaled-down version of your full production environment is always running in a secondary region. RTO: minutes. RPO: near-zero with async replication.
Multi-region active-active. Your full application runs in multiple regions simultaneously, serving traffic from all of them. RTO: near-zero (traffic just shifts away from the failed region). Most expensive but most resilient.
Testing DR: The Part Everyone Skips
A DR plan that hasn't been tested is not a plan — it's a hypothesis. And in my experience, untested DR plans fail about 70% of the time when you actually need them.
Schedule regular DR tests. Quarterly at minimum. Actually fail over to your secondary environment. Run production traffic through it. Find the things that break.
Game days. Netflix popularized chaos engineering with Chaos Monkey, but you don't need to be Netflix. Start simple: pick a Wednesday morning, announce it to your team, and intentionally fail a critical component. See how your systems respond and how your team responds. The process of recovering teaches you more than any amount of documentation.
Document everything. DR runbooks should be step-by-step, assuming the person executing them is stressed, sleep-deprived, and possibly unfamiliar with the system. Don't say "restore the database." Say "run this exact command, expect this output, wait for this condition, then proceed to the next step."
Uptime Is Revenue
This isn't just a slogan. Downtime has a quantifiable cost, and as CTO, you need to know what that number is.
Calculating the Cost of Downtime
Direct revenue loss. If your platform processes 416K in revenue. Obviously not all of that is permanently lost (some customers will come back), but some of it is.
Customer trust erosion. Every outage erodes customer trust. Enterprise customers track vendor reliability and use it in procurement decisions. Consumer customers just leave.
SLA penalties. If you've committed to uptime SLAs, breaches trigger credits or penalties. These are real dollars coming off your revenue.
Employee productivity. When your systems are down, your employees can't work either. If you have 500 employees and your internal systems are down for 4 hours, that's 2,000 person-hours of lost productivity.
Incident response costs. Engineers working on incidents aren't working on features. Senior engineers who should be designing next quarter's architecture are instead debugging why the database fell over.
Building a Culture of Reliability
Reliability isn't just about technology — it's about culture and incentives.
Celebrate reliability as much as features. If your organization only celebrates shipping new features, reliability will always be an afterthought. Create visibility for reliability work. Include reliability metrics in executive dashboards.
Blameless postmortems. When incidents happen (and they will), focus on learning, not blame. If people are punished for outages, they'll hide problems instead of fixing them.
On-call as a first-class responsibility. On-call shouldn't be a punishment or an afterthought. It should be well-compensated, well-supported, and well-staffed. If your on-call rotation is painful, fix the system, don't just accept the pain.
Error budgets. As discussed in the SRE framework, error budgets turn reliability from a vague goal into a concrete resource that gets managed alongside feature delivery.
Infrastructure as Competitive Advantage
The best infrastructure organizations don't just keep the lights on — they create capabilities that give the business an edge.
Speed as Advantage
If you can deploy to production in minutes while your competitors take weeks, you can iterate faster, respond to market changes faster, and deliver customer value faster. This is a real competitive advantage, even though it doesn't show up on any feature comparison sheet.
Deployment frequency. How often can you ship changes? Moving from monthly to weekly to daily to multiple-times-per-day deployments is one of the highest-leverage infrastructure investments you can make.
Environment provisioning. How fast can a developer spin up a complete test environment? If it takes a day, developers avoid testing. If it takes a minute, testing is part of the natural workflow.
New service creation. How long does it take to go from "we need a new service" to "it's running in production with monitoring, logging, and CI/CD"? If it's weeks, teams avoid creating services (leading to monolith bloat) or create them without proper operational setup (leading to outages).
Scale as Advantage
If your infrastructure can handle 10x your current traffic without architectural changes, you can pursue growth opportunities that your competitors can't. You can handle viral moments, seasonal spikes, and enterprise customers who bring massive workloads.
This doesn't mean over-provisioning. It means designing for horizontal scalability — so that handling more traffic is a matter of adding resources, not redesigning systems.
Global Presence as Advantage
If your infrastructure spans multiple regions, you can serve customers with lower latency, comply with data residency requirements, and enter new markets quickly. For some businesses, being able to say "your data stays in your country" is a deal-winning capability.
Real-World Examples
Example 1: The Multi-Cloud Mistake
A Series C startup decided to go multi-cloud "for redundancy." They split their infrastructure between AWS and GCP. The result:
- Two sets of IAM policies, two sets of networking configurations, two sets of monitoring dashboards
- Engineers who were mediocre at both platforms instead of excellent at one
- A "multi-cloud abstraction layer" that took six months to build and was constantly breaking
- 40% higher infrastructure costs compared to a single-cloud deployment
After 18 months, they consolidated onto AWS. The migration took four months but immediately saved them 30% on infrastructure costs and dramatically simplified operations.
The lesson: multi-cloud for redundancy sounds good in theory, but the operational overhead usually outweighs the benefit for companies below $100M in revenue.
Example 2: The FinOps Transformation
A SaaS company's cloud bill was growing at 50% year-over-year while revenue was growing at 25%. The CTO implemented a FinOps program:
- Week 1-2: Implemented tagging standards and cost allocation. For the first time, teams could see their actual spend.
- Month 1: Identified $200K/month in waste: unused resources, over-provisioned instances, forgotten development environments.
- Month 2-3: Negotiated a 3-year committed use agreement, saving 30% on baseline compute.
- Month 3-6: Architectural optimizations — moving batch workloads to spot instances, implementing auto-scaling, adding caching layers.
Result: Cloud cost growth rate dropped from 50% to 15% year-over-year, while revenue growth continued at 25%. The cloud cost as a percentage of revenue dropped from 22% to 16%, directly improving margins.
Example 3: The DR Test That Saved the Company
An e-commerce company ran their first DR test and discovered their database backups had been silently failing for three months. The backup process was running and reporting success, but the backup files were corrupted.
If they had experienced a real disaster during those three months, they would have lost all customer data, order history, and financial records. It would have been business-ending.
The DR test took one day. Discovering and fixing the backup issue took one week. It prevented what could have been a company-killing data loss.
Lesson: test your backups. Test your DR. Test them regularly. The investment is negligible compared to the risk.
Common Mistakes
Mistake 1: Cloud Lift-and-Shift Without Optimization
Moving your on-premises architecture directly to the cloud without rearchitecting. You end up paying cloud prices for on-premises patterns. Cloud is often more expensive than on-premises for workloads that don't take advantage of cloud-native services, auto-scaling, and managed offerings.
Mistake 2: No Cost Governance Until the Bill Is Shocking
Ignoring cloud costs during the growth phase and then panicking when the CFO notices. By the time the bill is painful, you have years of architectural decisions baked in that are expensive to change. Start cost governance early.
Mistake 3: Over-Engineering for Scale You Don't Have
Building infrastructure for millions of users when you have thousands. Every architectural decision has a cost, and building for premature scale wastes money and slows you down. Design for 10x your current scale, not 1000x.
Mistake 4: Treating DR as a One-Time Project
Building a DR plan once and never testing or updating it. Systems change, dependencies change, and DR plans go stale. DR is an ongoing practice, not a project.
Mistake 5: Vendor Lock-In Paranoia
Avoiding managed services and building everything yourself to avoid vendor lock-in. The cost of abstraction almost always exceeds the cost of migration. Use the best tools available today. If you need to migrate later, you'll figure it out — it's a solvable problem.
Mistake 6: No Infrastructure Roadmap
Making infrastructure decisions reactively instead of proactively. Without a roadmap, every decision is made in isolation, leading to an incoherent architecture that nobody can explain or maintain.
Business Value
Infrastructure strategy is easy to dismiss as a cost center, but it has direct, measurable business impact:
Revenue protection. Every minute of uptime is revenue preserved. Calculate your revenue per minute of uptime and multiply by the improvement your reliability investments deliver. For a company doing 50K in protected revenue — and much more in customer trust.
Margin improvement. Cloud cost optimization directly improves margins. A 20% reduction in cloud spend for a company spending 1M straight to the bottom line. This is one of the highest-ROI investments available.
Speed to market. Faster deployment, faster environment provisioning, and faster scaling let you ship features faster and respond to opportunities faster. Quantify this as the revenue impact of shipping features weeks or months earlier.
Risk reduction. DR and business continuity reduce the expected cost of catastrophic failures. If there's a 5% chance per year of a major outage that would cost 400K per year.
Market expansion. Global infrastructure enables geographic expansion. Data residency capabilities enable enterprise sales. Scale readiness enables you to pursue large customers. These are revenue-enabling capabilities.
When presenting infrastructure strategy to the board, translate everything into business terms. Don't say "we need to migrate to Kubernetes." Say "this infrastructure investment will reduce our deployment time from two weeks to two hours, allowing us to respond to market opportunities 7x faster while reducing our infrastructure cost per customer by 25%."
The CTO who can connect infrastructure decisions to business outcomes will never struggle to get infrastructure investment approved.
Common Pitfalls
-
Going multi-cloud for redundancy without doing the cost analysis. Multi-cloud doubles operational overhead, fragments team expertise, and typically increases costs by 30-40% without delivering the resilience benefits companies expect.
-
Performing a lift-and-shift migration without rearchitecting. Moving on-premises patterns directly to the cloud means paying cloud prices without gaining cloud benefits like auto-scaling, managed services, and elastic capacity.
-
Ignoring cloud costs until the bill becomes shocking. By the time the CFO notices, years of architectural decisions are baked in and expensive to change. Start cost governance and tagging standards early.
-
Over-engineering infrastructure for scale you do not have. Building for millions of users when you serve thousands wastes money and slows delivery. Design for 10x current scale, not 1000x.
-
Treating disaster recovery as a one-time project. Systems change, dependencies change, and DR plans go stale. An untested DR plan fails roughly 70% of the time when actually needed. DR is an ongoing practice requiring regular testing.
-
Avoiding managed services out of vendor lock-in paranoia. The cost of building abstraction layers almost always exceeds the cost of a future migration. Use the best tools available today and address migration if and when it is actually needed.
Key Takeaways
-
For most companies, single cloud is the right default. The depth of integration, team expertise, negotiating leverage, and operational simplicity outweigh the theoretical benefits of multi-cloud.
-
Cloud infrastructure is typically the second-largest line item after payroll. Treat it as a strategic decision, not a technical detail.
-
FinOps requires visibility (tagging and cost allocation), accountability (teams owning their spend), and continuous optimization at the resource, rate, and architecture levels.
-
The metric that matters most for infrastructure cost is cost per unit of business value (per transaction, per active user, per API call), not total spend.
-
Disaster recovery requirements (RTO and RPO) are business decisions that the CEO and CFO should weigh in on. The difference between a one-hour and one-minute RTO can be a 10x cost difference.
-
Infrastructure as competitive advantage means faster deployment, faster environment provisioning, horizontal scalability, and global presence. These capabilities directly enable business growth.
-
When presenting infrastructure strategy to the board, translate everything into business terms: deployment time reductions, cost per customer improvements, and revenue protection from reliability investments.