Capacity Planning & Team Efficiency
Here is a truth that will save you enormous pain if you internalize it early: your team has a finite amount of energy, focus, and hours. It sounds obvious. Everyone nods when you say it. And then everyone proceeds to plan as if it isn't true. They stack the sprint full. They commit to three "top priorities" and two "quick favors." They say yes to everything. And then they're shocked — genuinely shocked — when half of it ships late, buggy, or not at all.
Capacity planning is the discipline of knowing how much your team can realistically deliver and then making decisions based on that number instead of wishful thinking. It's not complicated. But it requires a kind of honesty that most organizations resist, because the honest answer is almost always "less than you want."
Your job as a team leader is to be the person who tells the truth about capacity. Not the person who says "we'll figure it out." Not the person who heroically overcommits and hopes for the best. The person who knows the real number, defends it, and then delivers against it consistently.
That's what this guide is about.
1. What Is Capacity Planning at Team Level
Capacity planning at the team level is answering one question: how much work can this team complete in the next sprint or cycle, given reality?
Not given ideal conditions. Not given the fantasy where nobody gets sick, every task estimate is perfect, no production incident interrupts your Wednesday, and everyone spends eight focused hours a day writing code. Given reality.
Most teams get this wrong. They get it wrong in the same direction every time — they overestimate. They look at five engineers, multiply by ten working days, get fifty person-days, and commit to fifty person-days of work. Then they're surprised when they deliver thirty-five. So next sprint they commit to fifty again, because surely this time will be different. It never is.
This cycle — overcommit, under-deliver, repeat — is one of the most common dysfunctions in software teams. It destroys predictability. It erodes trust with stakeholders. It burns people out. And it's entirely preventable.
Good capacity planning doesn't require sophisticated tools or complex frameworks. It requires three things:
An honest assessment of available time. Not headcount. Not "butts in seats." Actual hours your team can spend on planned work after you subtract everything else.
A realistic understanding of velocity. How much has this team actually completed in recent sprints? Not how much they committed to. How much they finished. That's your baseline.
The discipline to plan against real numbers. This is the hard part. Not because the math is hard, but because someone will always push you to commit to more. "Can't you just squeeze in one more feature?" "What if we skip testing?" "What if the team works a little harder this sprint?" You need to hold the line.
The payoff for getting this right is enormous. When you plan realistically, you deliver consistently. When you deliver consistently, stakeholders trust your estimates. When stakeholders trust your estimates, they stop pressuring you to overcommit. It's a virtuous cycle, and it starts with honest capacity planning.
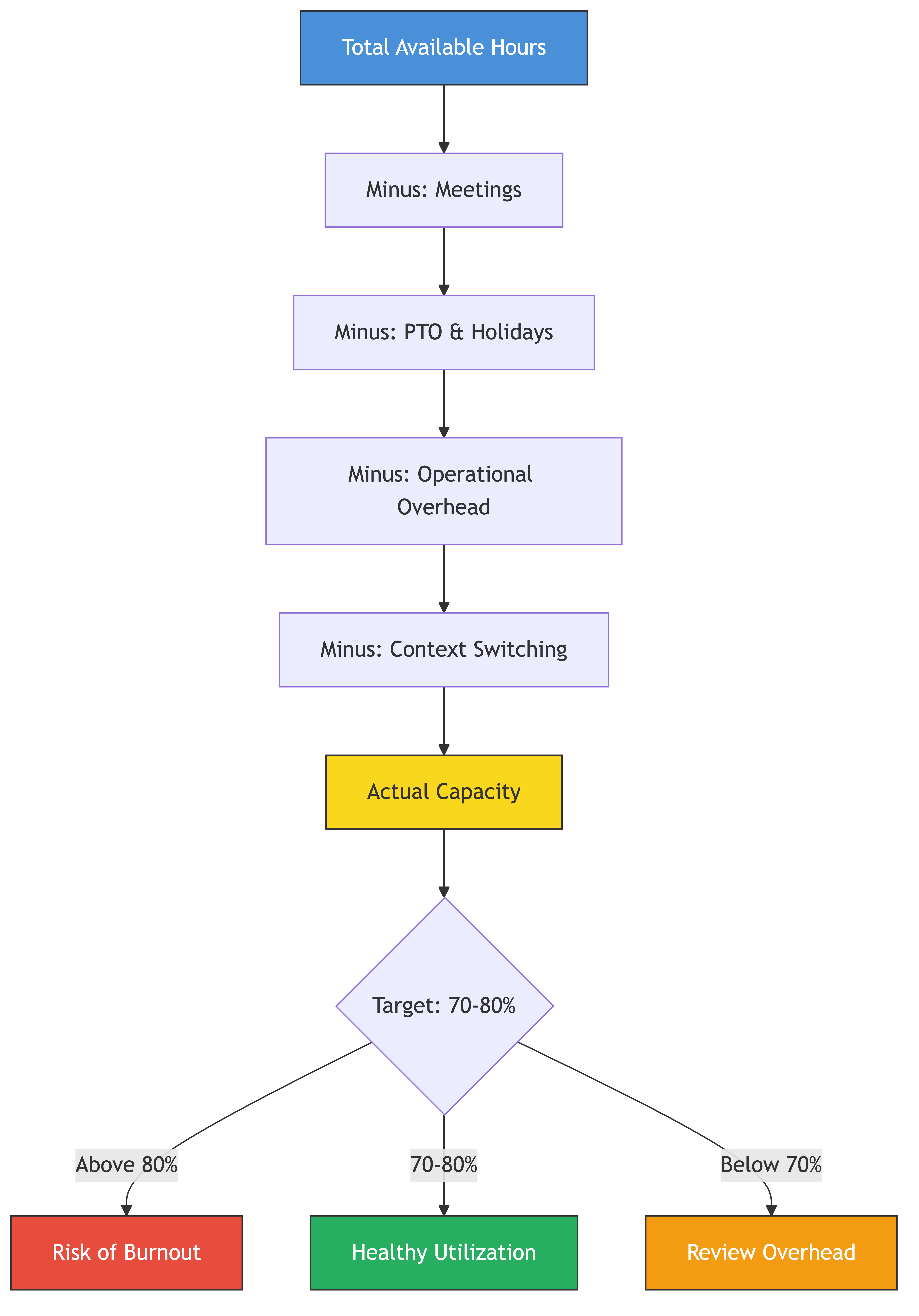
2. Calculating Team Capacity
Let's get concrete. Here's how you actually calculate team capacity for a two-week sprint. The math is simple. The discipline is in not rounding up.
Start with total available hours
Take each team member and count their working hours in the sprint. A standard two-week sprint is 10 working days. At 8 hours per day, that's 80 hours per person. For a team of five, that's 400 hours total.
That's your theoretical maximum. You will never hit it. Not once. Not ever.
Subtract PTO and holidays
This is the easy one. Check the calendar. If someone is out for three days, subtract 24 hours. If there's a company holiday, subtract 8 hours per person. Most teams remember to do this, though some don't even get this far.
Subtract meetings
This is where people start underestimating. Add up every recurring meeting for each team member: standup, sprint planning, retro, backlog grooming, 1:1s, team meetings, cross-team syncs, all-hands, architecture reviews. Be thorough.
For most engineers on a reasonably well-run team, meetings consume 6 to 10 hours per week. On a poorly-run team, it's more. That's 12 to 20 hours per sprint per person. For a five-person team, that's 60 to 100 hours gone. Just to meetings.
Subtract overhead and administrative work
Code reviews. Responding to Slack messages. Answering questions from other teams. Updating Jira tickets. Reading emails. Participating in on-call rotations. Helping with interviews. These activities are necessary, but they're not "sprint work."
Budget 5 to 10 hours per person per week for this. Yes, really. Watch someone's calendar and Slack activity for a week if you don't believe it.
Subtract context switching
This is the invisible tax. Every time someone switches between tasks, they lose time ramping back up. Studies consistently show this costs 15 to 25 minutes per switch, and engineers switch tasks multiple times per day. If someone is working on two projects simultaneously, they're not doing 50/50 — they're doing something closer to 40/40 with 20% lost to switching.
The real number
Let's run the math for one engineer on a two-week sprint:
- Total hours: 80
- PTO: 0 (they're here all sprint)
- Meetings: 16 (8 hours/week)
- Overhead: 12 (6 hours/week)
- Context switching: 6
Available for planned sprint work: 46 hours. That's 57% of their theoretical maximum. For a five-person team with no PTO, that's roughly 230 hours of actual capacity — not 400.
And that's a good sprint. Add one person out for two days, one production incident, and one unplanned request from another team, and you're closer to 180 to 200 hours.
This is why teams that plan for 400 hours of work consistently deliver 50 to 60% of their commitments. They're not bad at their jobs. They're bad at math. Or more precisely, they're bad at being honest about where the time goes.
Track and adjust
Your first capacity estimate will be wrong. That's fine. What matters is that you track actuals and adjust. After each sprint, compare what you planned to deliver against what you actually delivered. Over three to four sprints, you'll converge on a reliable capacity number for your team. That number is gold. Protect it.
3. Sustainable Pace
Here's a principle that will feel counterintuitive until you see it play out: 100% utilization means 0% ability to handle anything unexpected.
Think about a highway. When it's at 100% capacity, what happens? Nobody moves. A single car braking causes a chain reaction that stops traffic for miles. At 70% capacity, traffic flows smoothly, and the system can absorb disruptions — a merge, a slow truck, a lane closure — without gridlock.
Your team works the same way. When every hour of every person is allocated to planned work, you have zero slack in the system. No buffer for the production bug that comes in Tuesday morning. No room for the VP who needs a quick analysis by Thursday. No time for the junior engineer who's stuck and needs help. No capacity for the tech debt that's making every feature take twice as long.
So what happens? Everything is late. Or people work nights and weekends to make it fit. Or both.
Target 70-80% planned capacity
This is the range that works for most teams. Plan 70 to 80% of your calculated capacity (not your theoretical maximum — 70 to 80% of the realistic number we calculated in the previous section). Leave the remaining 20 to 30% unplanned.
That unplanned buffer is not wasted time. It's where real work happens:
- Bug fixes and production support. Every team has them. Planning as if you won't is delusional.
- Helping teammates. Senior engineers helping juniors, pairing on hard problems, knowledge transfer. This is some of the highest-leverage work on your team, and it doesn't show up in sprint planning.
- Unplanned requests. They will come. They always come. Having buffer means you can say "yes, we can fit that in" occasionally without blowing up the sprint.
- Recovery. People need breathing room. Back-to-back sprints at maximum effort lead to burnout, and burnout leads to turnover, which is the most expensive capacity problem of all.
What sustainable pace looks like in practice
A team running at sustainable pace feels calm but productive. Standups are short because people aren't drowning. Sprint commitments are met consistently — 85 to 95% of the time. When something urgent comes in, the team absorbs it without panic. People leave at reasonable hours. Quality is high because people have time to think, review carefully, and test properly.
A team running at unsustainable pace feels chaotic. Standups are long because everyone is blocked or behind. Sprint commitments are missed regularly. Every urgent request triggers a crisis. People work late. Code reviews are rubber-stamped. Bugs multiply. And the team ships less, not more, because they're constantly firefighting instead of building.
This is the paradox that many leaders and stakeholders don't understand: a team running at 80% planned capacity will ship more than a team running at 100%. The 100% team spends so much energy on overhead, rework, context switching, and firefighting that their effective output is lower.
How to sell sustainable pace to your manager
Your manager will likely push back on this. "Why are we leaving 20% of capacity unused?" Here's how to frame it:
"We're not leaving 20% unused. We're reserving 20% for unplanned work that historically takes up exactly that amount. Would you rather we plan for 100%, miss our commitments 40% of the time, and scramble every sprint — or plan for 80%, deliver on our commitments 90% of the time, and have the ability to absorb urgent requests without disrupting everything?"
Frame it in terms of predictability and delivery. Managers love predictability.
4. Maximizing Output
When someone tells you to "improve team efficiency," the temptation is to interpret that as "get people to work harder or longer." Resist that temptation. That approach has a hard ceiling (burnout) and diminishing returns long before you reach it.
Real efficiency gains come from removing friction, not adding pressure. You want to get more output from the same number of hours, not more hours from the same number of people.
Here's where to focus.
Reduce work in progress
This is the single highest-leverage change most teams can make. When an engineer is working on three things simultaneously, they're finishing none of them quickly. When they focus on one thing at a time, they finish it faster, with fewer bugs, and move on to the next.
The math behind this is well-established. If an engineer has one task, it gets 100% of their productive time. Two tasks: each gets roughly 40% (20% lost to switching). Three tasks: each gets about 20% (40% lost to switching). The more WIP, the longer everything takes.
As a practical rule, aim for each engineer to have one primary task and at most one secondary task (like a code review or small bug fix). If your board shows three or four items "in progress" per person, you have a WIP problem.
Remove blockers relentlessly
Your most important job as a team leader is unblocking people. Every hour someone spends waiting — waiting for a code review, waiting for access to a system, waiting for a decision from product, waiting for another team's API — is an hour of capacity lost.
Build a habit of asking in standup: "Is anything blocking you?" And then actually fix those blockers. That same day. Don't wait. Don't put it on a list. Walk over to the person doing the code review and ask them to prioritize it. Send the Slack message to get the access request approved. Make the decision yourself if you can, or escalate to someone who can.
The best team leaders I've seen spend 30 to 50% of their time unblocking their team. It's the highest-ROI activity you can do.
Minimize meetings
Every meeting is a direct tax on capacity. And most meetings are longer than they need to be, include people who don't need to be there, or shouldn't exist at all.
Audit your team's meeting load. For each recurring meeting, ask:
- Does this meeting have a clear purpose?
- Do all attendees need to be here?
- Could this be shorter?
- Could this be an async update instead?
Kill the meetings that fail these tests. Shorten the ones that pass. Protect blocks of uninterrupted time for your engineers — ideally four-hour blocks, minimum two hours. Fragmented time is nearly worthless for deep engineering work.
Improve processes, not effort
Look at where time is wasted systematically:
- Deployments. If deploying takes two hours of manual steps, automate it. The investment pays for itself in weeks.
- Code reviews. If reviews sit for two days, establish a 24-hour SLA and make reviews the first thing people do each morning.
- Testing. If manual testing takes a day per feature, invest in automated tests. Every hour of test automation saves dozens of hours over a year.
- Onboarding. If every new team member takes three months to become productive, create better documentation and pair programming rotations.
- Decision-making. If decisions take weeks because nobody knows who has authority, clarify ownership and push decisions to the lowest level that makes sense.
Each of these changes is small individually. Together, they compound. A team that invests consistently in process improvement will be dramatically more efficient after six months than a team that just tries to work harder.
5. Balancing Tech Debt vs. Features
Every team accumulates tech debt. It's inevitable. You take shortcuts to meet a deadline. You build on a library that becomes deprecated. A feature that was designed for 100 users now serves 100,000. The codebase grows in ways nobody planned for.
The question isn't whether you have tech debt. The question is how you manage it.
The slow death of ignoring tech debt
Teams that never pay down tech debt experience a predictable decline. In month one, a feature takes a week. In month six, a similar feature takes two weeks because the codebase is harder to work with. In month twelve, it takes three weeks because everything is fragile, tests are flaky, deployments are scary, and engineers spend half their time working around problems instead of solving them.
This is the most expensive form of capacity loss because it compounds. Every sprint you don't address it, the tax gets heavier. Eventually, the team grinds to a near halt, and someone proposes a rewrite, which is the most expensive and risky option of all.
The split
Most effective teams allocate 70 to 80% of their capacity to feature work and 20 to 30% to tech debt and engineering improvements. Some teams do 80/20. Some do 70/30. The exact ratio depends on how much debt you've accumulated and how fast the business needs to move.
The key is that the allocation is explicit and protected. It's not "work on tech debt if you have spare time." There is no spare time. It's "20% of our sprint capacity is reserved for engineering improvements, and here are the specific items we're working on."
How to negotiate this with product
Product managers will often resist allocating capacity to tech debt because it doesn't directly produce features. Here's how to frame the conversation:
Make it concrete. Don't say "we need to pay down tech debt." Say "this particular service takes 45 minutes to deploy because of how we've configured the pipeline. If we spend two days fixing it, we'll save three hours per week forever, which is over 150 hours per year."
Connect it to delivery speed. "The reason the last feature took three weeks instead of one is that we had to work around these specific issues. If we fix them, the next three features will each be a week faster."
Show the trend. Track your velocity over time. If it's declining, that's almost certainly tech debt. Show the chart. "Six months ago we shipped 40 story points per sprint. Now we're at 25. The codebase is getting harder to work with. If we don't invest in improvements, this number will keep dropping."
Propose, don't demand. "I'd like to propose we dedicate 20% of each sprint to engineering improvements. Here's a prioritized list of what we'd tackle first, and here's the expected impact on delivery speed. Can we try this for three sprints and measure the results?"
Most reasonable product partners will agree to a trial. And three sprints is usually enough to show measurable improvement.
Prioritizing tech debt
Not all tech debt is equal. Prioritize ruthlessly:
- High-traffic areas first. Fix the debt in code you touch every sprint, not in a service nobody's looked at in six months.
- Pain-driven, not perfection-driven. Fix things that are actively slowing you down or causing bugs, not things that are merely inelegant.
- Small, continuous improvements over big rewrites. A two-day refactor every sprint is almost always better than a six-week rewrite once a year.
6. Saying No
Your team can't do everything. Every "yes" is a "no" to something else. If you say yes to five things and your team can only deliver three, you haven't actually said yes to five things — you've said "maybe, poorly" to five things.
Learning to say no is one of the hardest and most important skills for a team leader. It feels bad. It feels like you're letting people down. It feels political. But the alternative — saying yes to everything and delivering on nothing reliably — is worse for everyone.
How to say no without burning bridges
The secret is that you almost never say the word "no." Instead, you make the trade-off visible and let the requestor make the decision.
"Yes, and here's the cost." — "We can absolutely do this. To fit it in, we'd need to push back Feature X by two weeks. Are you okay with that trade-off?"
"Yes, but not now." — "This is a great idea and we should do it. Right now our sprint is fully committed. Can we slot it into the next sprint?"
"Yes, if we can reduce scope." — "We can deliver the core functionality this sprint if we defer the edge cases to next sprint. Would a smaller version work for now?"
"Help me prioritize." — "We currently have items A, B, and C committed for this sprint. This new request is roughly the same size as B. Which one should we drop to make room?"
Each of these approaches does the same thing: it makes the constraint visible. You're not saying "no, I don't want to." You're saying "here is reality, and here are the options." This shifts the conversation from whether you'll do the work to which work you'll do, which is a much healthier conversation.
When you do need to say a hard no
Sometimes there's no trade-off to offer. A request is genuinely unreasonable — the timeline is impossible, the scope is absurd, or it requires skills your team doesn't have. In these cases, be direct and kind:
"I've looked at this carefully and I don't believe we can deliver it by that date at acceptable quality. Here's what I think is realistic, and here's why."
Don't hedge. Don't say "maybe" when you mean "no." False hope is worse than a clear no because it leads to planning decisions based on fiction.
Protect your team
Part of saying no is shielding your team from the chaos above them. Your engineers don't need to know that three VPs are fighting over your team's capacity. They don't need to absorb the stress of constantly shifting priorities. Your job is to absorb that chaos, resolve it (or escalate it), and give your team a clear, stable set of priorities.
When you fail to say no and your team gets overloaded, they pay the price — not you, not the VP who made the request, not the product manager who added "just one more thing." Your engineers pay it with their evenings, their weekends, their mental health, and eventually with their resignation letters.
7. Signs of Overload
An overloaded team doesn't always announce itself. People don't usually come to you and say "we're overloaded." They try to power through. They absorb the pressure. The signs are subtle at first, then obvious — but by the time they're obvious, you've already done damage.
Learn to spot the early signs.
Quality declines
This is usually the first casualty. When people are rushing, they cut corners. Code reviews become cursory. Test coverage drops. Edge cases are ignored. You'll see it in the bug rate — if bugs per sprint are trending up, your team is probably overloaded.
Deadlines slip
Not one deadline. A pattern. If your team is consistently delivering late, it means the plan is consistently wrong. And the most common reason the plan is wrong is that it assumes more capacity than actually exists.
People work late
If you notice engineers online at 9 PM or working weekends without being asked, that's a red flag. Some people will do this voluntarily because they care. That doesn't make it sustainable. If the work requires late nights to get done, the workload is too high. Period.
Communication decreases
When people are overwhelmed, they go quiet. They stop participating in discussions. They skip optional meetings. They give shorter answers in standup. They stop asking questions because they "don't have time." This is dangerous because it means problems are going unnoticed and people are suffering in silence.
Cynicism and disengagement
Listen for changes in tone. People who used to be enthusiastic becoming sarcastic. People who used to propose ideas going silent. "Whatever, just tell me what to build" is the sound of someone who's given up on the process and is just trying to survive.
How to course-correct
When you spot these signs, act quickly. The longer you wait, the harder it is to recover.
Reduce scope immediately. Cut something from the current sprint. Not next sprint — this sprint. Talk to product, explain the situation, and identify what can be deferred. This is a hard conversation, but it's necessary.
Cancel or shorten meetings. If your team is drowning, freeing up even a few hours can make a meaningful difference. Cancel that retro. Shorten standup to 10 minutes. Push the brainstorming session to next week.
Acknowledge the problem publicly. Tell your team: "I know we've been overloaded. That's on me. Here's what I'm doing to fix it." This matters more than you think. People need to know their leader sees the problem and is doing something about it.
Prevent recurrence. After the crisis passes, figure out what went wrong. Did you overcommit? Did unplanned work eat the buffer? Did someone add scope mid-sprint? Fix the root cause so it doesn't happen again.
8. Tracking Efficiency
You can't improve what you don't measure. But you can easily drown in metrics that tell you nothing useful. Here are the metrics that actually matter for a team leader tracking efficiency.
Cycle time
Cycle time is how long it takes for a unit of work to go from "started" to "done." Not from "planned" to "done" — from the moment someone actually begins working on it to the moment it's shipped.
This is arguably the most important efficiency metric. If your team's average cycle time for a medium-sized feature is five days, and it starts creeping up to eight days, something is wrong. Maybe reviews are taking longer. Maybe deployments are harder. Maybe the codebase is getting harder to work with. The number tells you to dig deeper.
Track it at the team level, not the individual level. Cycle time is a team metric. Using it to compare individuals is toxic and will destroy trust.
Throughput
Throughput is how many units of work your team completes per sprint. Items shipped, story points delivered, pull requests merged — whatever unit makes sense for your team. The specific unit matters less than the trend.
Stable or increasing throughput means your team is maintaining or improving efficiency. Declining throughput means something is getting worse, and you need to find out what.
Bug rate
Track the number of bugs found in production per sprint (or per release). This is your quality signal. A rising bug rate almost always indicates that the team is rushing, cutting corners, or working beyond their capacity.
Bug rate is also a useful counterbalance to throughput. A team can artificially inflate throughput by shipping sloppy code. Bug rate catches that.
Sprint commitment accuracy
What percentage of committed work does the team actually complete each sprint? If you're consistently at 85 to 95%, your capacity planning is solid. If you're at 60%, you're overcommitting. If you're at 100% every single sprint, you're probably sandbagging — committing to too little.
What to do with these metrics
Track them on a simple dashboard that you review every sprint. Look for trends, not individual data points. A single bad sprint means nothing. Three bad sprints in a row mean something.
Share them with your team. Not as a judgment tool — as a diagnostic tool. "Our cycle time has increased by two days over the last three sprints. Let's discuss in retro what might be causing that."
Share them with your manager. These metrics are how you make the case for changes — more headcount, less scope, more time for tech debt. Numbers are more persuasive than feelings.
9. Real-World Examples
Theory is useful, but let's look at what this looks like in practice. Here are three scenarios drawn from patterns that play out on real teams every day.
Scenario 1: The well-managed team
Team Alpha has six engineers. Their leader, Sam, has been tracking capacity for six months. She knows the team's effective capacity is about 55 story points per sprint after accounting for meetings, overhead, and unplanned work.
Each sprint, Sam commits to 45 to 50 points of feature work, leaving a buffer. She reserves 20% of capacity for tech debt items that the team prioritizes together. When the product manager asks for a feature that would push them to 65 points, Sam shows the capacity data and asks which existing item to drop. The product manager makes the trade-off.
The result: Team Alpha hits their sprint commitments 90% of the time. Stakeholders trust their estimates. When something urgent comes up, the team has buffer to absorb it without panic. The codebase stays healthy because they're consistently chipping away at tech debt. Morale is high. Turnover is low. This team has been together for two years, and their throughput has steadily increased as they've improved their processes and reduced friction.
Scenario 2: The overloaded team
Team Beta also has six engineers. Their leader, Jake, is under pressure from three different product managers, each with "top priority" features. Jake says yes to all of them because he doesn't want to disappoint anyone. The team is committed to 80 story points per sprint — 45% more than their realistic capacity.
Every sprint follows the same pattern: the first week feels fine, the second week is a scramble. Engineers work late to try to finish their commitments. Code reviews are rushed. Testing is minimal. They ship 50 to 55 points of work, but 30% of it has bugs that require hotfixes in the next sprint, further eating into capacity.
Nobody trusts the team's estimates because they miss them every sprint. The product managers are frustrated. The engineers are exhausted and resentful. Two of them have started interviewing elsewhere. The tech debt is piling up because there's "never time" to address it, so features take longer and longer to build.
Jake works 60-hour weeks trying to hold everything together and genuinely believes the problem is that his team isn't working hard enough. The actual problem is that he never learned to say no.
Scenario 3: The recovery
Team Gamma was in Team Beta's position six months ago. Their new leader, Maria, recognized the pattern in her first two weeks. Here's what she did:
Week 1-2: Observed. Tracked where time was actually going. Found that engineers were averaging 25 hours per week of productive coding time, not the 40 hours the plan assumed.
Week 3-4: Had honest conversations with each product stakeholder. Showed the data. "We've missed our commitments in eight of the last ten sprints. We're planning for 40 hours of work per person but delivering 25. I'd like to try something different."
Month 2: Reduced sprint commitments by 30%. Introduced a 20% tech debt allocation. Started tracking cycle time and throughput.
Month 3-4: The team started hitting commitments. Morale improved. Two engineers who had been interviewing elsewhere decided to stay. Cycle time dropped by 25% as the tech debt work started paying dividends.
Month 5-6: Throughput actually increased past the old inflated commitments — but this time the work was clean, tested, and reliable. Stakeholders, who had been skeptical at first, became the biggest advocates for the new approach because they finally had predictable delivery.
Maria didn't add people. She didn't implement some new framework. She just told the truth about capacity and managed to it.
10. Common Mistakes
These are the capacity planning mistakes I see most often. You will be tempted to make every one of them.
Planning for 100% capacity
This is the most common and most damaging mistake. We covered this in detail in Section 3, but it bears repeating: if your plan has zero slack, any disruption — and there will always be disruption — breaks the plan. Build in buffer. Always.
Ignoring unplanned work
Every team has unplanned work: production bugs, urgent stakeholder requests, infrastructure issues, security patches. If you don't account for it in your capacity plan, you're pretending it doesn't exist. Track how much unplanned work your team does each sprint. For most teams, it's 15 to 25% of total capacity. Plan for it.
Not accounting for meetings
I've seen leaders count "person-days" as if an engineer with six hours of meetings has the same capacity as one with two hours. They don't. Not even close. An engineer with six hours of meetings in a day has maybe two hours of productive work — not because they're lazy, but because the remaining time is fragmented into slots too short for deep work.
Map your team's actual meeting load. If it's excessive, cut it. If you can't cut it, at least account for it honestly in your planning.
Treating all team members as interchangeable
A senior engineer with five years on the codebase and a junior engineer in their first month are not fungible resources. They have different speeds, different strengths, different areas of expertise. A task that takes the senior two days might take the junior a week — and that's fine and expected, because the junior is learning.
Plan with individual capabilities in mind. This doesn't mean micromanaging task assignments. It means being realistic about who can do what, and how long it will actually take specific people on your specific team.
Measuring effort instead of output
"The team worked really hard this sprint" is not a success metric. "The team shipped three features with zero critical bugs" is. Hours worked and perceived effort are inputs. Delivered value is the output. Focus on the output.
Confusing busy with productive
A team where everyone is in meetings all day, responding to Slack constantly, and juggling five tasks simultaneously looks busy. They might even feel productive. But look at what they actually shipped. Often it's surprisingly little, because all that activity isn't focused work — it's thrashing.
If your team looks busy but throughput is low, you don't have a laziness problem. You have a focus problem. Reduce WIP, reduce meetings, and create space for deep work.
Never adjusting the plan
Capacity planning is not a one-time exercise. Your team's capacity changes as people join and leave, as the codebase evolves, as processes improve or degrade. Review and adjust your capacity model every few sprints. What was true three months ago might not be true today.
Business Value
Everything in this guide ultimately connects to business outcomes. Let's make that connection explicit, because you'll need it when justifying these practices to leadership.
Predictability
A team with good capacity planning delivers consistently. When you tell a stakeholder "this will be done in three sprints," it actually gets done in three sprints. This predictability has enormous business value because it enables better planning at every level: marketing can plan launches, sales can make commitments to customers, leadership can make roadmap promises to the board.
Unpredictable teams create chaos upstream. Nobody can plan around them. Dates slip. Launches are delayed. Customers get frustrated. Eventually, the business stops trusting engineering's estimates entirely, which leads to adversarial relationships between engineering and the rest of the company.
Efficiency gains compound
A team that invests 20% of capacity in process improvements and tech debt gets slightly faster every sprint. Over six months, a team that was delivering 40 story points might be delivering 55 — without adding a single person. That's a 37% efficiency gain, which is equivalent to hiring two more engineers at zero cost.
Show this math to your leadership. They understand ROI.
The cost of burnout and turnover
This is the business case that most leaders fail to make, and it's the most financially compelling one.
Replacing an engineer costs between 50% and 200% of their annual salary when you account for recruiting, interviewing, onboarding, and the ramp-up period before the new person is fully productive. For a senior engineer making 90,000 to $360,000 per departure.
Now consider that the average ramp-up time for a new engineer on an established team is three to six months. During that time, they're consuming capacity (asking questions, needing code reviews, making mistakes that need to be caught) while producing at maybe 30 to 50% of a fully ramped engineer.
A team with high burnout and high turnover is running on a treadmill. They're constantly losing experienced people and replacing them with people who need months to get up to speed. They never build the institutional knowledge and team cohesion that makes great teams fast.
The math is clear: retaining one engineer through good capacity management is worth more than the output of pushing the whole team past their limits. And you don't retain people by paying them more or giving them better titles. You retain them by giving them a sustainable, well-managed work environment where they can do good work without burning out.
Revenue impact
Overloaded teams don't just ship less — they ship worse. Buggy software leads to customer churn. Missed deadlines lead to lost deals. Slow feature delivery leads to competitive disadvantage. These are real revenue impacts, even if they're hard to quantify precisely.
A well-managed team that ships reliable software on predictable timelines is directly contributing to revenue growth, customer retention, and market position. That's the business case for everything in this guide.
Pulling It All Together
Capacity planning isn't glamorous. Nobody writes blog posts about the team leader who correctly estimated sprint capacity. There are no conference talks about saying no to your product manager's pet feature. But this is the foundation that everything else rests on.
When capacity is well-managed, your team delivers consistently. Quality stays high. People are engaged and growing. Stakeholders trust you. You have room to invest in the future. Problems get caught early and fixed quickly.
When capacity is mismanaged, everything else falls apart. It doesn't matter how talented your engineers are, how elegant your architecture is, or how visionary your product roadmap is. If your team is overloaded, overcommitted, and burning out, none of that matters.
Be the leader who tells the truth about capacity. Be the leader who protects sustainable pace. Be the leader who says "not now" when necessary and "absolutely" when possible. Your team, your stakeholders, and your business will all be better for it.
Common Pitfalls
- Planning for 100% capacity. This is the most common and most damaging mistake. If your plan has zero slack, any disruption breaks it. Real teams have meetings, overhead, context switching, and unplanned work that consume 40-50% of theoretical capacity.
- Ignoring unplanned work in your capacity model. Production bugs, urgent stakeholder requests, and infrastructure issues consume 15-25% of most teams' capacity every sprint. Pretending they will not happen guarantees you will miss commitments.
- Treating all team members as interchangeable resources. A senior engineer with five years on the codebase and a junior engineer in their first month have very different speeds and capabilities. Planning without accounting for individual differences produces unrealistic estimates.
- Measuring effort and busyness instead of delivered output. "The team worked really hard this sprint" is not a success metric. Hours worked are inputs; shipped features with acceptable quality are outputs. Focus on what actually got delivered.
- Never saying no to incoming requests. Saying yes to everything means delivering nothing reliably. Every unmanaged yes erodes your team's capacity and teaches requestors that the prioritization process can be bypassed.
- Neglecting tech debt until it cripples velocity. Teams that never invest in engineering improvements experience compounding slowdowns. A similar feature that took one week six months ago takes three weeks today because the codebase has degraded.
Key Takeaways
- Capacity planning answers one question: how much can this team realistically complete given reality, not ideal conditions? The honest answer is almost always less than stakeholders want.
- Calculate real capacity by subtracting PTO, meetings, overhead, and context-switching costs from theoretical hours. For most engineers, available sprint work is roughly 55-60% of total hours.
- Target 70-80% of calculated capacity for planned work. The remaining buffer handles bugs, support, helping teammates, and unplanned requests. A team at 80% planned capacity ships more than a team at 100% because the overloaded team spends its time firefighting.
- Real efficiency gains come from removing friction, not adding pressure. Reduce WIP, remove blockers relentlessly, minimize meetings, and improve processes like deployments, code reviews, and testing.
- Allocate 20-30% of capacity explicitly for tech debt and engineering improvements. Frame the investment in business terms: connect it to delivery speed, incident reduction, and developer retention.
- Learn to say no by making trade-offs visible: "We can do that, but here is what we would need to drop." This shifts the conversation from whether to do the work to which work to prioritize.
- Track cycle time, throughput, bug rate, and sprint commitment accuracy. Look for trends across sprints and share them with your team and your manager to drive data-informed decisions.