Technical Debt Negotiation
You will fight this battle for your entire career. Every team accumulates technical debt. The good teams manage it deliberately. The struggling teams either ignore it until everything breaks or obsess over it until they stop shipping. Your job as a team leader is to find the balance — and more importantly, to convince people who don't write code that the balance matters.
What Is Technical Debt
Technical debt is every shortcut, workaround, and "we'll fix it later" decision that speeds up delivery today but makes tomorrow's work harder. Ward Cunningham coined the term because it works exactly like financial debt: you borrow against the future to get something now, and you pay interest on that loan every time someone touches the affected code.
Here is the thing most people get wrong: not all debt is bad. Sometimes taking on debt is the smartest move you can make. Launching a feature with a quick-and-dirty implementation to validate the idea before investing in a polished one? That is strategic debt. Shipping a hardcoded config because you need to hit a deadline and the proper solution takes a week? That is a reasonable trade-off, as long as you write it down and come back to it.
The problem is never the existence of debt. The problem is untracked, unmanaged, accumulating debt that nobody talks about until the system is falling apart. Awareness is everything. If you know where your debt lives and roughly how much interest it costs you, you can manage it. If you don't, it manages you.
Types of Debt
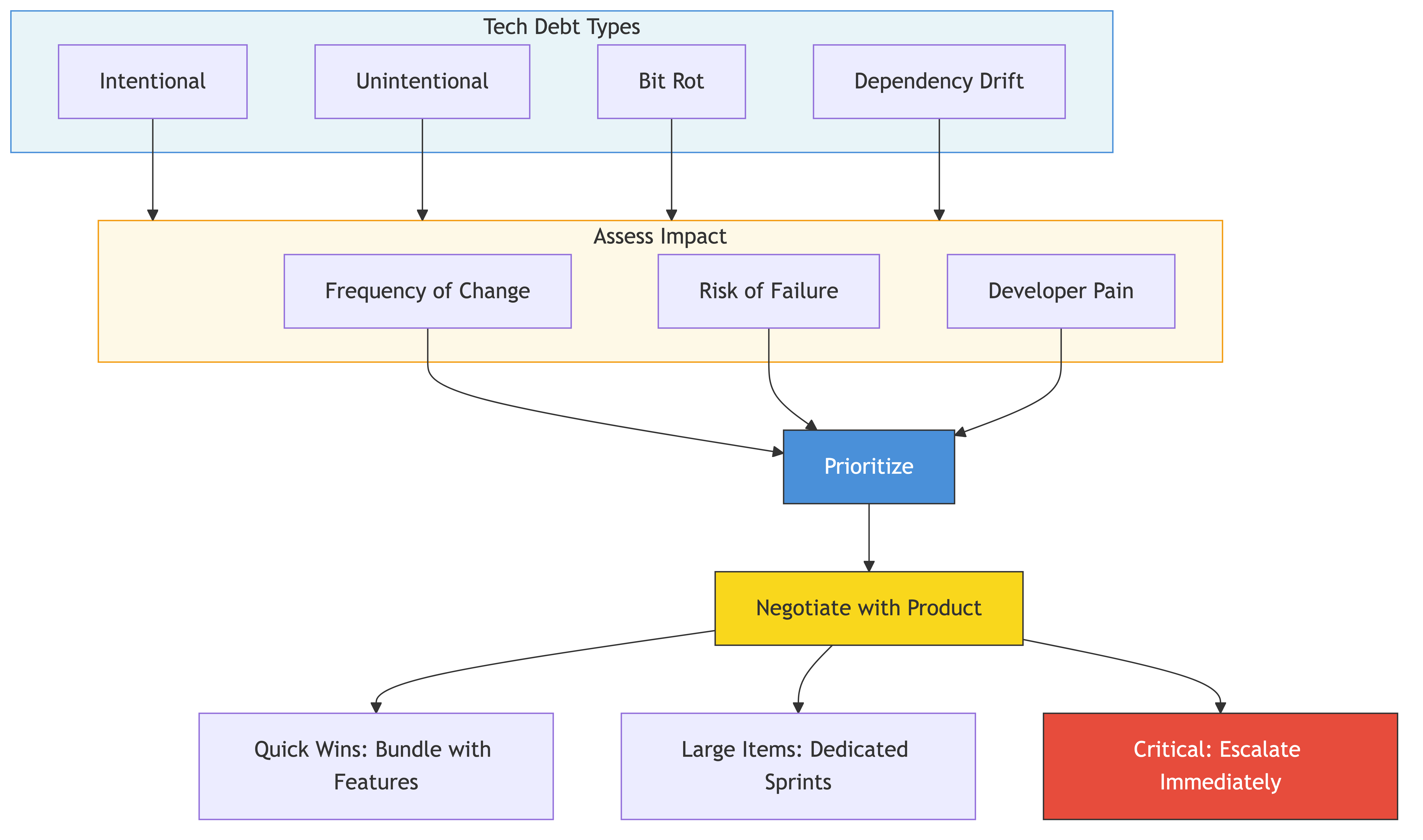
Debt comes in several flavors, and they demand different responses.
Intentional Debt
"We know this is a shortcut, and we're taking it on purpose." This is the healthiest kind because it comes with awareness. You made a conscious trade-off. The danger is when you take it on and never write it down. Three months later, nobody remembers it was supposed to be temporary.
Unintentional Debt
"We didn't know better at the time." You designed something that seemed right, but as the system grew, it turned out to be the wrong abstraction. Nobody is at fault here. Codebases evolve, requirements change, and what was a good decision last year can be a bad one today. This is the most common type, and the hardest to prevent.
Bit Rot
Code ages even when nobody touches it. The ecosystem moves forward, conventions change, team knowledge shifts. That service written two years ago by someone who left the company? It still works, but nobody understands it well enough to change it confidently. The patterns it uses are different from everything else in the codebase. It is becoming a liability simply by existing.
Dependency Debt
Your libraries, frameworks, and tools get old. Security patches pile up. Major version upgrades become multi-week projects because you put them off for too long. The longer you wait, the bigger the jump, and the scarier the migration. Dependency debt compounds faster than any other kind because you are at the mercy of external maintainers and their timelines.
Why Product and Business Doesn't Care (Yet)
Put yourself in your product manager's shoes for a moment. They have a roadmap full of features that customers are asking for. Sales is pressuring them for that one integration that will close a big deal. Leadership wants to see progress on the quarterly goals. And you walk in and say "we need to spend two weeks refactoring the payment service."
They cannot see debt. Features are visible — you can demo them, customers react to them, revenue follows them. Debt is invisible. The codebase looks the same from the outside whether it is clean or a disaster. Nobody outside the engineering team can tell the difference.
This will remain true right up until one of three things happens:
Velocity drops. Features that used to take a week now take three. The team spends more time working around problems than solving them. Sprint commitments start getting missed regularly.
Incidents increase. That fragile area of the code starts breaking in production. On-call becomes miserable. Customers notice.
Developers quit. Working in a codebase full of unmanaged debt is demoralizing. Your best people — the ones with options — leave first. Then you are trying to hire into a codebase that nobody wants to work in.
By the time any of these become obvious, you are already deep in trouble. Your job is to make the case before the crisis, not after.
Framing Debt in Business Terms
This is the most important skill in this entire guide. The words you use determine whether anyone listens to you.
Don't say: "The code is messy and we need to refactor it."
Nobody outside engineering knows what that means, and it sounds like you just want to rewrite things because you don't like how they look.
Do say: "This feature should take two days, but because of accumulated shortcuts in this part of the system, it will take two weeks. Here's why."
Do say: "We had three production incidents last month, all in the same area. Each one took an engineer offline for half a day. That is six engineer-days of unplanned work in one month from one area of technical debt."
Do say: "Our deployment process requires four manual steps that each carry risk of human error. Automating them would cost us one sprint and save us two hours per deployment, plus reduce our rollback rate."
Speak in time, money, risk, and customer impact. These are the currencies your product and business partners understand. "The code is messy" is an engineering concern. "We are shipping slower and breaking things more often" is a business concern.
The Velocity Impact
Data is your most powerful ally. If you are not tracking your team's velocity in some form, start now. You don't need anything fancy — even a rough count of story points or features delivered per sprint over time will do.
When you see the pattern, show it. "Six months ago we were shipping eight features per sprint. Now we are shipping four. Here is what changed." Then connect it to specific areas of debt. "Forty percent of our sprint is going to working around problems in the notification system. If we spend three sprints fixing the underlying issues, we project getting back to six or seven features per sprint."
You can also track:
- Time to complete similar tasks over time. If adding a new API endpoint used to take a day and now takes three, that is measurable debt interest.
- Incident frequency by area. If one service is responsible for most of your pages, that is a debt hotspot.
- Onboarding time. If new engineers take longer and longer to become productive, debt is likely a factor.
- Code change failure rate. If changes to certain areas frequently cause bugs, the code is telling you something.
The goal is to take something that feels subjective — "the code is hard to work with" — and make it objective. Numbers are harder to argue with than feelings.
Negotiation Strategies
You have several models to choose from. Different ones work for different teams and organizational cultures.
The 20% Rule
Dedicate twenty percent of every sprint to technical debt and maintenance work. This is the most common approach and the easiest to negotiate because it is predictable. Product knows they get eighty percent of the team's capacity for features, and engineering gets a consistent allocation for keeping the codebase healthy.
The advantage is simplicity. The risk is that twenty percent feels arbitrary, and some sprints you need more while others you need less.
The Tax Model
Treat debt work as a tax on feature work. Every feature that touches a debt-heavy area includes time to improve that area. If a feature estimate is five days, and two of those days are because of debt, you include a day of cleanup in the estimate. The debt work ships alongside the feature.
This works well because it ties debt paydown directly to business priorities. The areas that get the most feature work — which are presumably the most important areas — also get the most cleanup.
Bundling
Package debt work with feature work so that it is invisible to the roadmap. "We are building the new dashboard" includes "and while we are in there, we are fixing the data layer." This is pragmatic but can feel dishonest if taken too far. Be transparent with your EM about what you are doing.
The Boy Scout Rule
Leave every file better than you found it. This is not a negotiation strategy so much as a team practice. When you touch code to build a feature, you clean up what you see — rename confusing variables, extract a function, add a missing test. Small improvements, constantly, that add up over time.
This works best for preventing new debt from accumulating. It is less effective for paying down large, concentrated debt.
The Dedicated Sprint
Sometimes you need a focused push. "We are going to spend the next two sprints entirely on infrastructure and debt in the billing system." This is the hardest to negotiate but sometimes the only option when debt has concentrated in one area to the point where incremental improvement is not enough.
Save this for when you have strong data and a clear business case. Use it sparingly or you will lose credibility.
Prioritizing Which Debt to Pay
You will never pay down all your debt. You don't need to. You need to pay down the debt that matters.
Prioritize by these factors:
Frequency of change. Debt in code that nobody touches is annoying but harmless. Debt in code that your team modifies every sprint is actively slowing you down. Focus on the hot paths.
Risk of failure. Some debt is ugly but stable. Other debt is a ticking time bomb — one bad deploy away from a production incident. The risky stuff gets priority.
Developer pain. If your team dreads working in a particular area, that is a signal. Developer pain correlates with bugs, slow delivery, and attrition. Pay attention to where people groan.
Customer impact. Debt in your core user-facing flows matters more than debt in internal tools. If a slow, fragile checkout process is losing you customers, that debt has a dollar sign attached to it.
A simple scoring matrix works well. Rate each debt item on these four dimensions, add the scores, and sort. You will have a prioritized list that you can defend in any meeting.
Making the Case to Your EM and PM
Walk in with a concrete proposal, not a vague complaint.
Bad: "We have a lot of technical debt and need time to address it."
Good: "I have a proposal. The notification service has caused four incidents in the last two months and adds an average of three days to any feature that touches it. If we spend three sprints on a focused cleanup — specifically rewriting the event pipeline and adding integration tests — I project we will reduce incident rate in that area by seventy percent and cut feature delivery time for notification-related work in half. Here is the data that supports this."
Structure your pitch:
- The problem, in business terms. Time lost, incidents caused, customer impact.
- The proposed investment. How many sprints, which engineers, what specifically will be done.
- The expected return. Faster delivery, fewer incidents, happier developers. Be specific, even if your numbers are estimates.
- The cost of inaction. What happens if you don't do this. More incidents? Slower velocity? People leaving?
If your EM or PM says no, ask what evidence would change their mind. Sometimes the answer is "wait until it gets worse," and that is a valid business decision. Document it, revisit it in a quarter, and come back with updated data.
Real-World Examples
The Team That Managed Debt and Stayed Fast
A platform team at a mid-size company dedicated every fourth sprint entirely to debt and infrastructure work. They called it "health week." Product knew about it, planned around it, and accepted it as the cost of having a team that consistently delivered on their commitments the other three sprints.
During health weeks, the team tackled their highest-priority debt items, upgraded dependencies, improved test coverage, and fixed things that had been bugging them. The result: their velocity stayed remarkably consistent over two years. While other teams in the company were slowing down and dealing with increasing incidents, this team kept shipping at the same pace. They had the lowest attrition rate in the engineering org. New engineers onboarded faster because the codebase was well-maintained. The "lost" twenty-five percent of sprint capacity paid for itself many times over.
The Team That Never Paid Debt and Ground to a Halt
A feature team at a fast-growing startup was under constant pressure to ship. Every sprint was packed with feature work. The tech lead raised concerns about accumulating debt multiple times, but the PM always said "we'll address it next quarter." Next quarter never came.
After eighteen months, the situation was dire. Simple features took weeks because every change required navigating a maze of workarounds. The CI pipeline took forty-five minutes because the test suite was tangled and flaky. On-call was miserable — three or four incidents a week, mostly in areas everyone was afraid to touch. Two senior engineers left within a month of each other, citing frustration with the codebase. The team eventually had to pause feature work for an entire quarter just to stabilize the system. They lost far more time than they would have spent on incremental maintenance.
The Team That Over-Invested and Shipped Nothing
An infrastructure team was given broad latitude to "do things right." They spent months building the perfect abstraction layer, rewriting services that worked fine but were not architecturally pure, and chasing test coverage numbers without considering which tests actually mattered.
Meanwhile, the business needed features. Other teams were blocked waiting for infrastructure changes. Leadership started asking what the team was actually delivering. The team had gold-plated their systems but had no business impact to show for it. The team lead was eventually moved to another role, and the new lead had to pivot the team back toward delivering value. Several of the "perfect" systems they built were later replaced anyway because business requirements changed.
The lesson: debt paydown is a means to an end, not an end in itself.
Common Mistakes
Gold Plating Disguised as Debt Paydown
"We need to refactor this" can mean "this code is causing real problems" or "I don't like the way this looks." Learn to tell the difference, both in yourself and in your team. Every debt item should have a concrete impact statement. If you cannot articulate what problem the debt is causing in terms of velocity, reliability, or maintainability, it might not be debt — it might be preference.
Not Tracking Debt
If your debt is not written down somewhere, it does not exist as far as planning is concerned. Maintain a backlog of debt items, even if it is just a label in your issue tracker. Each item should describe what the debt is, why it matters, and roughly how much effort it would take to address. Without this, you are negotiating from memory, which is a losing position.
The All-or-Nothing Approach
"We need to stop everything and rewrite the billing system" is almost always the wrong answer. Big rewrites are risky, demoralizing, and frequently fail to deliver on their promises. Prefer incremental improvement. Strangle the old system piece by piece. Ship value along the way.
Not Measuring the Impact of Paydown
You spent three sprints paying down debt. Did it help? If you cannot answer that question with data, you will have a much harder time making the case for the next round of debt work. Track your before-and-after metrics: deployment frequency, incident rate, time-to-complete for similar tasks, developer satisfaction. Show the return on the investment.
Treating All Debt as Urgent
Some debt is fine to live with. That slightly awkward API in an internal tool that three people use? Probably not worth fixing. That duplicated logic in a service that ships changes twice a week? Worth fixing now. Urgency should be proportional to impact.
Business Value of Technical Debt Management
This is the section you bring to meetings with people who control budgets and roadmaps.
Velocity Preservation
A well-maintained codebase delivers features at a consistent rate. An unmaintained codebase delivers features at a decreasing rate. Over a twelve-month horizon, the team that spends twenty percent of its time on maintenance will typically ship more total features than the team that spends one hundred percent of its time on features. This is counterintuitive but consistently true. The interest payments on unmanaged debt eventually consume more time than proactive maintenance would have.
Incident Reduction
Every production incident has a cost: engineer time to investigate and fix, customer impact, potential revenue loss, and the hidden cost of context-switching the team away from planned work. Paying down debt in high-risk areas directly reduces incident frequency. Track your incident rate before and after debt work, and you will have a compelling number to share.
Developer Retention
Replacing an engineer costs six to nine months of their salary when you account for recruiting, onboarding, and the productivity ramp. Developers leave teams with unmanaged debt at higher rates. They have options, and they will go somewhere that respects their time and sanity. Every senior engineer you retain because the codebase is well-managed is worth more than several sprints of feature work.
Concrete ROI
Here is how to build a simple ROI case. Say your team of six engineers spends an average of thirty percent of their time working around debt — navigating workarounds, debugging fragile code, dealing with incidents. That is roughly 1.8 engineer-equivalents of wasted capacity. If a focused debt paydown effort costing two sprint's worth of one engineer's time can reduce that waste to fifteen percent, you have recovered 0.9 engineer-equivalents of capacity. That is the equivalent of hiring almost one more engineer, for the cost of a few weeks of focused work.
Run the numbers for your own team. The math almost always favors managing debt proactively.
Putting It All Together
Technical debt negotiation is not about winning an argument. It is about building a shared understanding between engineering and product that the codebase is a shared asset that requires maintenance, just like any other asset. Your job is to make the invisible visible, to translate engineering concerns into business language, and to propose solutions that balance shipping features with keeping the system healthy.
Start small. Track your debt. Show the data. Make concrete proposals. Measure the results. Over time, you will build the credibility and the track record to make these conversations easy instead of adversarial.
The best teams do not argue about whether to pay down debt. They argue about which debt to pay down first. Get your team to that point, and you are doing this right.
Common Pitfalls
- Framing debt in technical terms instead of business language. Saying "the code is messy and we need to refactor" fails to resonate with product and business partners. Speak in time lost, incidents caused, revenue at risk, and customer impact.
- Not tracking debt in a visible, prioritized backlog. If your debt items are not written down with descriptions of impact and estimated effort, they do not exist as far as planning is concerned. You cannot negotiate from memory.
- Pursuing gold-plating disguised as debt paydown. "We need to refactor this" can mean the code is causing real problems or simply that someone does not like how it looks. Every debt item needs a concrete impact statement; without one, it might be preference, not debt.
- Proposing all-or-nothing rewrites instead of incremental improvement. Big rewrites are risky, demoralizing, and frequently fail to deliver on promises. Prefer strangling the old system piece by piece and shipping value along the way.
- Not measuring the impact of debt paydown. If you spend three sprints paying down debt and cannot show before-and-after metrics like deployment frequency, incident rate, or time-to-complete, you will have a much harder time making the case for the next round.
- Treating all debt as equally urgent. Some debt is ugly but stable and harmless. Other debt is in hot-path code touched every sprint and actively slowing delivery. Prioritize by frequency of change, risk of failure, developer pain, and customer impact.
Key Takeaways
- Technical debt works exactly like financial debt: you borrow against the future to get something now, and you pay interest every time someone touches the affected code. The problem is never the existence of debt but untracked, unmanaged debt.
- Not all debt is bad. Intentional, strategic debt taken with awareness and a plan to pay it back is a reasonable trade-off. Unintentional, accumulating debt with no tracking is where teams get into trouble.
- Product and business partners cannot see debt. They only notice when velocity drops, incidents increase, or developers quit. Your job is to make the invisible visible before the crisis.
- Frame debt in business terms: time, money, risk, and customer impact. Show data on declining velocity, incident frequency, and the multiplier effect of working around known problems.
- Choose a negotiation strategy that fits your team: the 20% rule, the tax model, bundling with feature work, the boy scout rule, or dedicated sprints. Different approaches work for different organizational cultures.
- Prioritize debt paydown by frequency of change, risk of failure, developer pain, and customer impact. Focus on the hot paths where your team works every sprint, not stable corners nobody touches.
- The math almost always favors proactive maintenance. A team spending 20% of its time on upkeep will ship more total features over twelve months than one spending 100% on features, because the interest payments on unmanaged debt eventually consume more capacity than maintenance would have.