Identifying & Escalating Risks
You are going to be wrong about timelines. Features will turn out harder than expected. Dependencies will break. People will get sick at the worst possible time. None of that makes you a bad leader. What makes you a bad leader is pretending none of it is happening until it blows up.
Risk management at the team level is not about spreadsheets and probability matrices. It is about developing the instinct to say "something feels off here" and then doing something about it before it becomes a real problem.
1. What Are Risks at the Team Level
Forget everything you have heard about formal risk registers and red-amber-green dashboards. At your level, a risk is simply this:
"This might go wrong, and here is why I am worried."
That is it. A risk is a thing that has not happened yet but could happen, and if it does, it will hurt your team, your timeline, your quality, or your people. You do not need a framework to identify risks. You need to pay attention and be honest about what you see.
Some examples of what risks look like in practice:
- "We are betting on a new library that nobody on the team has used before."
- "The designer has not signed off on the final mocks and we start building on Monday."
- "Sarah is the only person who understands the billing service and she mentioned she is interviewing."
- "The product spec keeps changing every standup."
None of these are crises yet. All of them could become crises if you ignore them. Your job is to notice them, name them, and decide what to do about them before they bite you.
2. Common Risks for Engineering Teams
After a while, you will start seeing the same risks show up over and over. Here are the ones that hit engineering teams the hardest.
Key Person Dependency
One person holds all the knowledge for a critical system. If they go on vacation, get sick, or leave the company, you are stuck. This is sometimes called the "bus factor" and it is one of the most common risks in engineering. You will be shocked how often an entire team's delivery depends on a single person's availability.
Unclear Requirements
The product spec says "users should be able to manage their settings" but nobody has defined what "manage" means. Does it include deletion? Bulk operations? Role-based access? When requirements are vague, engineers fill in the gaps with assumptions. Different engineers make different assumptions. You end up building the wrong thing.
Tight Deadlines
Someone committed to a date without consulting the team. Or the original estimate was reasonable but scope grew while the deadline stayed fixed. Tight deadlines are not inherently bad, but unrealistic ones create a pressure cooker where quality, morale, and sometimes both collapse.
External API Dependencies
Your feature depends on another team's API, or worse, a third-party vendor's API. You have no control over their timeline, their quality, or their priorities. If their service goes down or their contract changes, you are exposed.
Technical Unknowns
You are using a technology the team has not worked with before. Or you are integrating with a system nobody fully understands. Or the architecture requires a pattern you have never tried at this scale. Unknown unknowns are the scariest risks because you do not even know what questions to ask yet.
Scope Creep
The project started as "add a simple search feature" and now includes faceted filtering, saved searches, search analytics, and an admin dashboard. Each addition seemed small. Together they doubled the work. Scope creep is death by a thousand paper cuts.
Team Burnout
Your team has been sprinting for three months straight. People are working late. PTO requests have stopped. The quality of code reviews is declining. Burnout does not show up on a Jira board, but it is one of the highest-impact risks you will face because it compounds. A burned-out team ships slower, makes more mistakes, and eventually people start leaving.
3. Spotting Risks Early
The best time to catch a risk is before it becomes obvious. Here are the patterns to watch for.
PRs Taking Too Long
If pull requests that should take a day to review are sitting open for a week, something is wrong. Maybe the code is too complex. Maybe the reviewer does not understand the system. Maybe the team is overloaded. Whatever the cause, slow PRs are a leading indicator that delivery is about to slow down.
Estimates That Keep Growing
"It is a two-day task" becomes "probably a week" becomes "I am not sure, it is more complicated than I thought." When estimates grow, it means the team is discovering complexity they did not anticipate. That is not a failure of estimation; it is a signal that the technical unknowns are bigger than expected.
One Person Doing All the Critical Work
Look at your commit history. Look at who is reviewing the important PRs. Look at who gets pulled into every incident. If one name keeps showing up, you have a key person dependency forming in real time.
"It Should Be Fine" With No Evidence
This is the phrase that should make your ears perk up. When someone says "it should be fine" but cannot explain why it will be fine, they are hoping, not planning. Ask follow-up questions. "What makes you confident? What could go wrong? Have we tested this assumption?" If the answers are vague, you have a risk.
Silence in Standups
When people stop sharing blockers or concerns in standup, it does not mean everything is going well. It often means they have given up on raising issues because nothing happens when they do. Or they are too deep in a hole to articulate the problem yet.
Sudden Changes in Team Behavior
Someone who was engaged and vocal goes quiet. A reliable contributor starts missing deadlines. The team stops pushing back on unreasonable asks. These behavioral shifts are often symptoms of deeper problems. Pay attention to them.
External Signals
Your product manager seems stressed about a stakeholder meeting. Another team mentions they are "reprioritizing." The company announces a reorg. These are all signals that your team's context might be about to change in ways that affect your plans.
4. The Difference Between Risks and Issues
This distinction matters because the response is different for each.
A risk is something that might happen. You can still prevent it or reduce its impact. The building is not on fire yet, but you can smell smoke.
An issue is something that is already happening. Prevention is off the table. Now you are in response mode. The building is on fire and you need to put it out.
Here is why this matters for you as a team leader:
| Risk | Issue | |
|---|---|---|
| Status | Has not happened yet | Already happening |
| Response | Prevent, mitigate, plan around | Respond, contain, recover |
| Urgency | You have time to be strategic | You need to act now |
| Communication | "This could happen, here is my plan" | "This is happening, here is what I need" |
| Tone | Proactive, calm | Urgent, focused |
The danger zone is when a risk becomes an issue and you are still treating it like a risk. If your key person just gave their two-week notice, you are not "at risk of key person dependency" anymore. You are in a key person dependency crisis and need to act accordingly.
A good practice is to regularly ask yourself: "Is this still a risk, or has it become an issue?" The answer changes what you should do next.
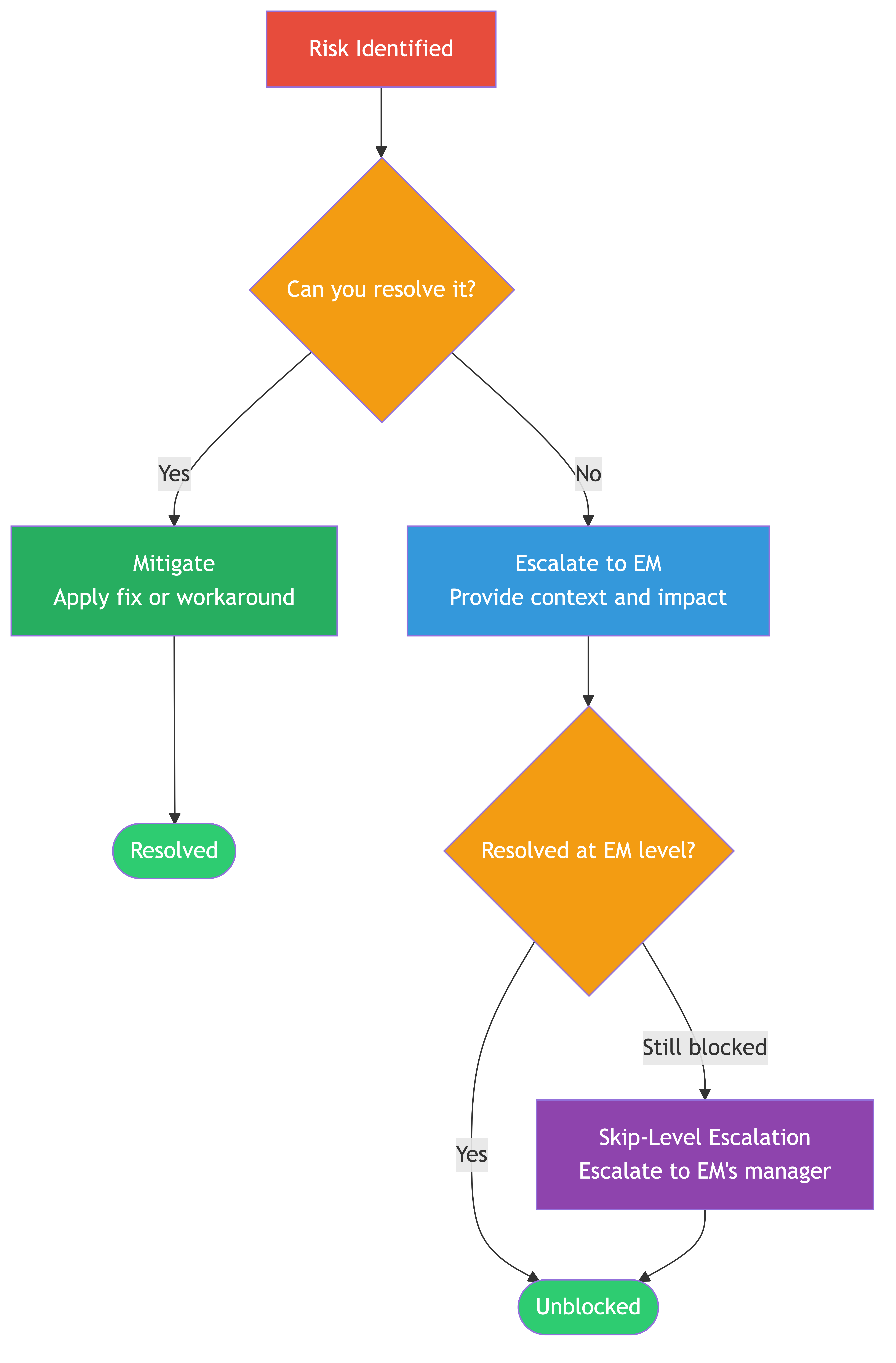
5. When to Escalate
Here is a hard truth: you cannot solve everything yourself, and you should not try. Escalation is not a sign of weakness. It is a sign that you understand the limits of your authority and influence.
Escalate when:
The Impact Is Beyond Your Team
If the risk or issue affects other teams, other products, or company-level commitments, your manager needs to know. You might not even have visibility into how far the blast radius extends.
You Need Resources You Do Not Have
Maybe you need another engineer. Maybe you need a decision from someone two levels above you. Maybe you need legal to review something. If the solution requires resources outside your control, escalate.
The Timeline Is Genuinely at Risk
Not "we might be a day late" (handle that yourself), but "we are going to miss the launch window by two weeks and marketing has already committed to the date." When the timeline impact is significant enough that other teams need to adjust their plans, escalate.
You Have Tried and Failed
You identified the risk. You came up with a mitigation plan. You executed the plan. It did not work. Now what? Escalate. You have done your due diligence and you need help. There is no shame in that.
Your Gut Says Something Is Really Wrong
Sometimes you cannot fully articulate why you are worried, but the feeling is persistent. Trust that instinct. It is better to escalate something that turns out to be fine than to stay silent about something that turns into a disaster. Your manager would much rather hear "I might be wrong, but I am worried about X" than discover X has been a problem for weeks.
6. How to Escalate Without Blame
The way you escalate matters as much as whether you escalate. A bad escalation creates conflict and defensiveness. A good escalation creates clarity and action.
Here is the framework. Memorize it.
The Escalation Template
- Here is the situation. State the facts. What is happening or what might happen. No editorializing.
- Here is the impact. What will this affect? Timeline, quality, cost, people, customers.
- Here is what I have tried. Show your work. What have you already done to address this?
- Here is what I need. Be specific. A decision? Resources? Air cover? A conversation with another team?
Example of a Good Escalation
"I want to flag something about the payments migration. We discovered that the legacy API has undocumented rate limits that are going to affect our migration speed. At the current rate, the migration will take three weeks instead of one, which puts us past the deprecation deadline. I have already talked to the legacy team and they confirmed they cannot raise the limits. I need your help getting a conversation with their director to explore alternatives, or we need to push the deprecation deadline back."
Example of a Bad Escalation
"The payments team is blocking us again. They refuse to help with the migration and now we are going to miss the deadline. Someone needs to tell them to fix their API."
See the difference? The first one is factual, specific, and solution-oriented. The second one is blaming, vague, and emotionally charged. The first one makes your manager want to help you. The second one makes your manager wonder if there is another side to the story.
Rules for Blame-Free Escalation
- Use "we" language, not "they" language. "We have a dependency that is at risk" instead of "They are not delivering."
- Describe behaviors, not character. "The response time on our requests has been two weeks" instead of "They do not care about our project."
- Own your part. If you could have caught this earlier, say so. It builds trust.
- Propose solutions, not just problems. Even if your proposed solution is wrong, it shows you are trying to move forward.
7. Escalation Levels
Not every risk needs to go to the CEO. Matching the escalation to the severity is a skill you will develop over time, but here are some guidelines.
Level 1: Your Engineering Manager
This is your first stop for most escalations. Use this when:
- The risk is contained to your team but you need guidance.
- You need help prioritizing or making a tradeoff.
- You want a gut check on whether something is worth worrying about.
- You need your manager to have context in case things get worse.
Most of your escalations should stay at this level. Your EM has context you do not and can often unblock things with a single conversation that would take you days of emails.
Level 2: Skip-Level (Your Manager's Manager)
This is for when your EM cannot solve it or when the urgency warrants going higher. Use this when:
- The risk affects multiple teams and needs coordination at a higher level.
- Your EM has tried and failed to resolve a cross-team dependency.
- The impact is significant enough that leadership needs to be aware for strategic reasons.
- There is a timeline commitment to an executive or external customer.
Important: Almost always loop in your EM before going skip-level. Going around your manager without telling them erodes trust fast. The exception is if the issue involves your manager, in which case skip-level is the right path.
Level 3: Cross-Team Escalation
Sometimes the risk involves another team directly. Use this when:
- You have a hard dependency on another team's deliverable.
- There is a disagreement about technical approach that affects both teams.
- Shared resources (infrastructure, data, services) are at risk.
For cross-team escalations, start peer-to-peer. Talk to the other team's lead first. If that does not resolve it, both of you escalate to your respective managers. If that does not resolve it, it goes up another level. This is the "escalation ladder" and it works because each level has more authority and broader context.
Matching Severity to Level
| Severity | Example | Escalation Level |
|---|---|---|
| Low | "We might be a day or two late on this feature" | Mention to your EM in your 1:1 |
| Medium | "We are going to miss the sprint goal and it affects the quarterly target" | Direct conversation with your EM, this week |
| High | "We cannot deliver the launch commitment without help from another team" | EM plus cross-team escalation |
| Critical | "We have a security vulnerability in production" | Skip-level, immediately, plus incident process |
8. Creating a Culture of Raising Risks
Here is the thing about risk identification: you are one person. You see a fraction of what your team sees. If your engineers do not feel safe saying "I am worried about this," you will only ever catch the risks you personally stumble across.
Make It Safe to Raise Concerns
The first time someone raises a risk on your team, your reaction sets the tone for everything that follows. If you dismiss it, minimize it, or react with frustration, they will not raise the next one. And the next one might be the one that matters.
What to do instead:
- Thank them. Literally say "Thank you for raising this." Every time.
- Ask questions, do not interrogate. "Tell me more about what worries you" instead of "Why didn't you think of this sooner?"
- Follow up. If someone raises a risk, come back to them later with what you did about it. Nothing kills a risk-raising culture faster than raising something and watching it disappear into a void.
Normalize Risk Conversations
Build risk identification into your regular rituals:
- In standups: Add "anything you are worried about?" as a regular prompt.
- In retros: Discuss risks that materialized and risks that were caught early. Celebrate the catches.
- In planning: Explicitly ask "what could go wrong?" during sprint planning or project kickoffs. Make it a required part of the conversation, not an afterthought.
- In 1:1s: Ask each person "what is keeping you up at night about the project?" You will be surprised what comes out when people have a private, safe space.
Model the Behavior
If you want your team to raise risks, you have to raise risks yourself. Share your own concerns openly. Say "I am worried about X and here is what I am doing about it." When your team sees that their leader is comfortable being uncertain and proactive about it, they will follow.
Reward Early Warnings
When someone catches a risk early and it saves the team from a problem, call it out publicly. "Jamie flagged last week that the API contract was ambiguous, and because she raised it early, we caught a misalignment that would have cost us a week of rework." This is the behavior you want to reinforce.
9. Real-World Examples
Scenario 1: The Risk Caught Early
Situation: During sprint planning, a junior engineer mentions that the third-party geocoding API the team is integrating has a rate limit of 1,000 requests per hour. The feature they are building will need to geocode 50,000 addresses during the initial data migration.
What the team leader did: Flagged it immediately. Worked with the engineer to calculate the actual throughput needed. Reached out to the vendor about higher rate limits (which cost more money). Escalated to their EM with a clear ask: "We need budget approval for the higher-tier API plan, or we need to redesign the migration to run over five days instead of one. Here are the tradeoffs."
Outcome: The EM approved the budget increase. The migration ran on schedule. Total cost of early detection: one conversation and a slightly higher vendor bill. If they had discovered this during the migration itself, the launch would have slipped by a week while they scrambled for a workaround, and the customer commitment would have been missed.
Scenario 2: The Risk Hidden Until Crisis
Situation: A senior engineer was building a critical data pipeline. During standups, they reported everything was "on track." In reality, they had hit a fundamental architectural issue two weeks in but were embarrassed to admit that their original design would not work. They kept trying to make it work, rewriting sections, working late, hoping they could power through.
What happened: Two days before the deadline, the engineer finally admitted the pipeline could not handle the required data volume. The team had to completely redesign the approach. The project slipped by six weeks. The engineer, who had been working 12-hour days trying to fix it alone, burned out and took a leave of absence.
What the team leader missed: The signs were there. The engineer stopped participating in code reviews. Their commits went from steady daily pushes to sporadic large dumps. They declined a pairing session. The team leader did not ask enough questions when "on track" was the only update for two straight weeks.
Lesson: "On track" with no detail is not a status update. It is a red flag.
Scenario 3: The Escalation That Prevented a Customer Impact
Situation: A team leader noticed that the platform team's new authentication service, which their team depended on for an upcoming launch, kept failing intermittent integration tests. The platform team said it was "a known flaky test, not a real issue."
What the team leader did: Instead of accepting that answer, they dug into the test failures themselves and found that the flakiness was actually a race condition that would affect roughly 2% of login attempts under load. They documented the findings, wrote up the potential customer impact (2% of logins failing during peak traffic means roughly 400 users per hour seeing errors), and escalated to their EM with a clear request: "I need us to jointly escalate this with the platform team's manager because I believe this is a real bug, not a flaky test."
Outcome: The joint escalation led to the platform team investigating properly. They confirmed the race condition, fixed it in two days, and the launch went smoothly. Without the escalation, the bug would have hit production and affected thousands of users on launch day.
10. Common Mistakes
Escalating Too Late
This is the most common mistake by far. New team leaders tend to be optimistic. They think they can handle it. They wait one more day, then one more, then one more. By the time they escalate, the risk has become an issue and the issue has become a crisis.
The fix: Set a personal rule. If a risk has not improved in two status checks (standups, weekly syncs, whatever your cadence is), escalate. Do not wait for certainty. Escalate on trajectory.
Escalating Everything (The Cry Wolf Problem)
The opposite problem. If you escalate every small concern to your manager, two things happen. First, they stop taking your escalations seriously. Second, they start wondering if you can handle the job. Not every risk needs to be escalated. Some you can mitigate yourself. Some are low-impact enough to simply monitor.
The fix: Before escalating, ask yourself: "Can I handle this with the resources and authority I already have?" If yes, handle it and inform your manager afterward. If no, escalate.
Not Following Up
You escalate a risk. Your manager says they will look into it. A week passes. Nothing happens. You assume it is handled. It is not. Now the risk has grown and nobody owns it.
The fix: When you escalate, agree on a follow-up date. Put it in your calendar. If you have not heard back, ask. Escalation without follow-up is just venting.
Blaming in Escalations
"The backend team is incompetent" is not an escalation. It is a complaint. Even if the backend team is genuinely dropping the ball, framing it as blame makes you look unprofessional and makes it harder for your manager to help.
The fix: Stick to the template from Section 6. Situation, impact, what you have tried, what you need. Facts, not feelings.
Treating All Risks as Equal
A risk of being one day late on an internal tool is not the same as a risk of shipping a security vulnerability. But some team leaders treat every risk with the same urgency (or the same indifference). This leads to either panic fatigue or complacency.
The fix: Get in the habit of asking two questions about every risk: "How likely is this?" and "How bad would it be if it happened?" High likelihood and high impact means act now. Low likelihood and low impact means monitor and move on.
Not Documenting Risks
You mentioned a risk in standup on Tuesday. By Friday, nobody remembers. The risk materializes the following week and everyone acts surprised.
The fix: Write risks down. It does not need to be a fancy system. A section in your team's project doc, a pinned message in Slack, a recurring agenda item in your team meeting. The point is that risks should be visible and tracked, not just mentioned in passing.
Business Value
Risk management is not just a feel-good leadership practice. It has direct, measurable impact on the business.
The Cost of Late Discovery
Study after study in software engineering confirms that the cost of fixing a problem increases dramatically the later you find it. A requirement misunderstanding caught in planning costs a conversation. The same misunderstanding caught in production costs an incident, a hotfix, customer support tickets, and sometimes lost customers.
Here are some concrete numbers to think about:
- A one-week project delay typically costs the business the equivalent of the fully loaded salary of every engineer on the project for that week. For a team of five, that is easily 50,000 in direct cost alone, not counting opportunity cost.
- A missed launch window for a revenue-generating feature delays revenue. If the feature is projected to generate 100,000 in lost revenue.
- A production incident caused by an unmitigated risk costs engineering time to fix, customer support time to handle tickets, potential SLA penalties, and brand damage that is hard to quantify but very real.
- Employee turnover from burnout (a risk you could have caught) costs 50-200% of the departing employee's annual salary when you factor in recruiting, onboarding, and ramp-up time.
The ROI of Early Risk Detection
Teams that consistently identify and mitigate risks early see measurable improvements:
- 20-30% fewer project delays. Most delays are caused by risks that were known but not addressed. Simply tracking and acting on risks eliminates a significant chunk of slippage.
- Reduced incident frequency. When teams catch technical risks during development instead of production, incident rates drop. Fewer incidents mean less unplanned work, which means more time building features.
- Higher team retention. When engineers feel heard and see that their concerns are acted on, engagement goes up and turnover goes down. A team that loses one fewer engineer per year saves the company 400,000.
- Better stakeholder trust. When you consistently flag risks early and manage them proactively, your stakeholders trust your estimates and your judgment. That trust translates into more autonomy, better project selection, and less micromanagement.
Measurable Outcomes to Track
If you want to demonstrate the value of your risk management to your leadership, track these:
- Number of risks identified before they became issues. This is your "catches" metric. Higher is better.
- Average time from risk identification to mitigation. This tells you how quickly you act on what you find.
- Project delivery variance. Compare estimated vs. actual delivery dates. Teams with good risk management have smaller variances.
- Unplanned work percentage. How much of your team's time goes to firefighting vs. planned work? Good risk management reduces unplanned work over time.
The bottom line: every risk you catch early saves the business money, time, and trust. Every risk you miss costs multiples of what it would have cost to address proactively. As a team leader, risk management is one of the highest-leverage activities you can invest in.
Wrapping Up
Risk management at the team level comes down to three things: paying attention, speaking up, and following through. You do not need a certification or a framework. You need to watch for the signals, have the courage to name what you see, and take action before problems grow.
The teams that deliver reliably are not the ones that never encounter risks. They are the ones that surface risks early, escalate effectively, and treat risk identification as everyone's job. Build that culture, and you will be amazed at how many crises you simply never have.
Common Pitfalls
- Escalating too late because of optimism. New team leaders tend to believe they can handle it and wait one more day, then one more. By the time they escalate, the risk has become a crisis. If a risk has not improved in two check-ins, escalate on trajectory, not certainty.
- Escalating everything and losing credibility. The opposite extreme: flagging every minor concern to your manager trains them to stop taking your escalations seriously and makes them wonder if you can handle the job. Before escalating, ask whether you can resolve it with the resources and authority you already have.
- Not following up after escalating. Raising a risk and then assuming someone else is handling it leads to situations where nobody owns the problem. Always agree on a follow-up date and check back if you have not heard.
- Using blame in escalation language. Framing escalations as "they are not delivering" instead of "we have a dependency at risk" makes you look unprofessional and makes it harder for your manager to help. Stick to facts, impact, and what you need.
- Treating all risks as equally urgent. A risk of being one day late on an internal tool is not the same as a risk of shipping a security vulnerability. Get in the habit of asking both "how likely is this?" and "how bad would it be?" to calibrate your response appropriately.
- Not documenting risks anywhere. Mentioning a risk in standup on Tuesday and having nobody remember by Friday means the risk was never truly tracked. Write risks down in a visible, trackable location.
Key Takeaways
- A risk is simply something that might go wrong. You do not need a framework to identify risks. You need to pay attention and be honest about what you see.
- The most common risks for engineering teams are key person dependencies, unclear requirements, tight deadlines, external API dependencies, technical unknowns, scope creep, and burnout.
- Early detection is everything. Watch for PRs taking too long, estimates that keep growing, one person doing all the critical work, "it should be fine" without evidence, and silence in standups.
- Know the difference between risks (things that might happen) and issues (things already happening). The response is different for each, and the danger zone is treating an active issue as if it were still just a risk.
- Escalate when the impact is beyond your team, when you need resources you do not have, when the timeline is genuinely at risk, or when your gut says something is really wrong.
- Use blame-free escalation: state the situation, describe the impact, show what you have tried, and specify what you need.
- Build a culture where raising risks is celebrated rather than punished. Thank people for early warnings, follow up on reported risks, and model the behavior by sharing your own concerns openly.