Delivery Management & Time-to-Market
Why This Matters
Here is a truth that many engineering managers learn the hard way: the best code in the world is worthless if it never ships. Or if it ships six months late. Or if it ships after your competitor already ate your lunch.
Delivery management is not project management with a fancier title. It is the discipline of turning your team into a reliable, predictable shipping machine — one that consistently gets valuable software into the hands of customers. And time-to-market is the metric that tells you whether you are actually doing it well.
This is one of the areas where an EM earns their keep. Individual contributors write the code. You make sure that code becomes a product that reaches users when it needs to.
1. Speed Is a Competitive Advantage
Let me be blunt: the company that ships faster wins. Not always. Not in every market. But often enough that you should treat speed as a first-class concern.
Here is why speed compounds:
- Faster shipping means faster learning. You do not actually know if your feature is good until real users touch it. Every week you delay shipping is a week you are flying blind on assumptions.
- Faster iteration means faster improvement. Ship version one, learn, ship version two. The team that does this in four-week cycles will outpace the team doing it in four-month cycles — not by a little, but dramatically.
- Speed attracts talent. Engineers want to work on teams where their work sees the light of day. Nobody wants to spend six months on a project that gets shelved or "reprioritized."
- Speed builds momentum. Teams that ship regularly feel good. Teams stuck in endless development cycles get demoralized.
Your job as an EM is not to crack the whip and demand people work faster. That is the amateur move, and it backfires every time. Your job is to remove the friction, eliminate the waste, and create the conditions where your team can ship at a sustainable, fast pace.
Think about it like this: you are not making people run faster. You are paving the road, removing the potholes, and taking down the unnecessary stop signs.
What Slows Teams Down
Before you can speed things up, you need to understand what actually slows teams down. It is rarely that engineers are writing code too slowly. The usual culprits:
- Unclear requirements. Engineers build the wrong thing, then rebuild.
- Excessive process. Three rounds of review, two approval committees, a change advisory board — all for a button color change.
- Poor tooling. Slow CI/CD pipelines, painful deployment processes, flaky test suites.
- Context switching. Engineers juggling five things at once finish none of them.
- Decision bottlenecks. Everything waits on one person to approve, review, or decide.
- Scope creep. The project keeps growing while the deadline stays fixed.
Your leverage as an EM is in fixing these systemic issues. That is how you make your team fast.
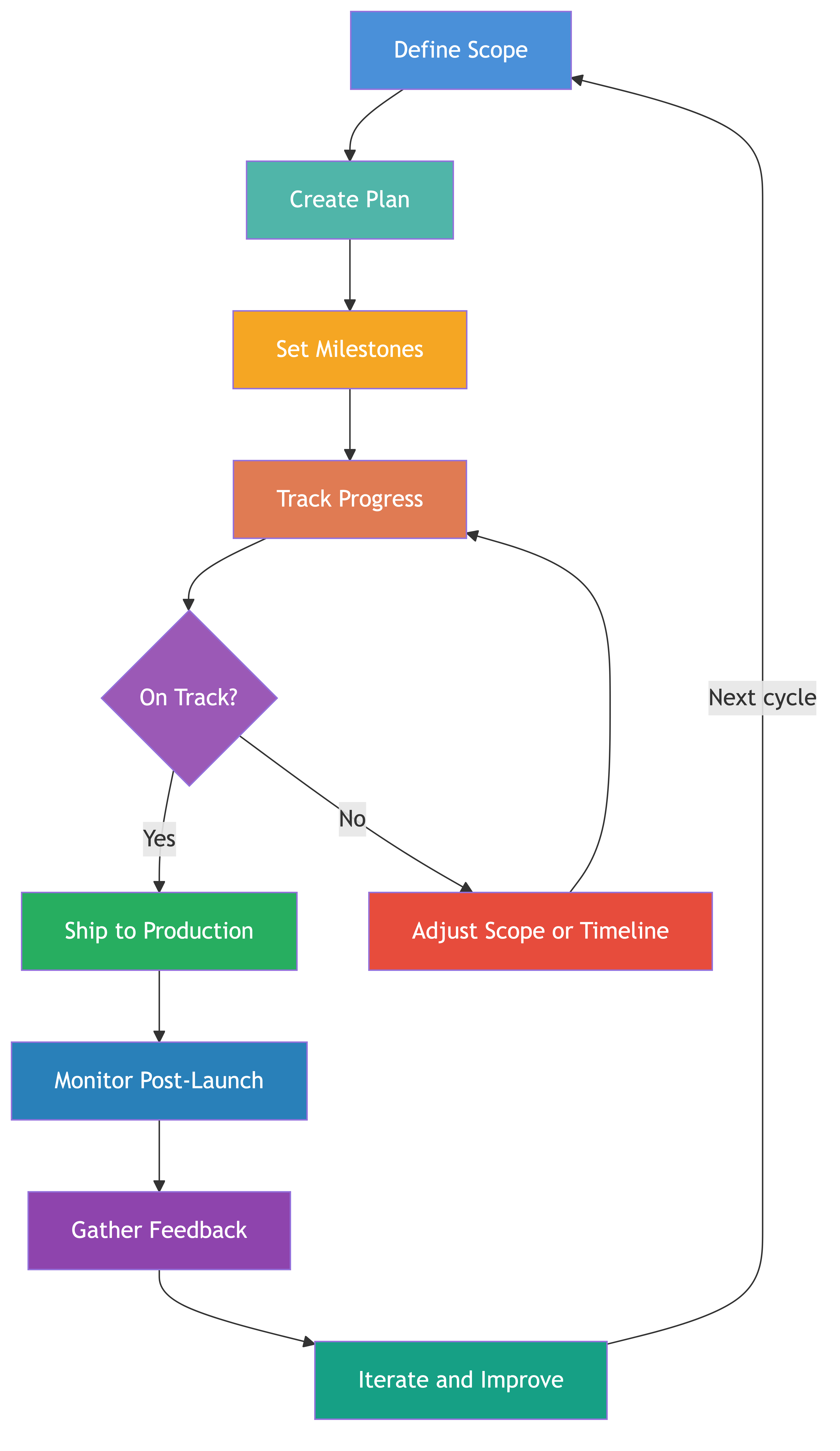
2. Project Planning at EM Level
Project planning as an EM is fundamentally different from project planning as an IC or a traditional project manager. You are not writing Jira tickets and assigning story points. You are operating at a higher altitude.
Scoping
Good scoping is the single biggest determinant of whether a project will ship on time. Get the scope wrong and everything downstream falls apart.
Your job in scoping:
- Define the outcome, not just the output. "Build a notification system" is output. "Reduce user churn by alerting users before their trial expires" is an outcome. The outcome tells you when you have done enough.
- Draw the boundary clearly. What is in scope? What is explicitly out of scope? Write it down. Get agreement. Refer back to it when scope creep shows up — and it will show up.
- Identify the MVP. What is the smallest thing you can ship that delivers value? Start there. You can always add more later, but you cannot un-waste three months of over-building.
- Involve your engineers in scoping. They know what is technically complex and what is straightforward. If you scope without them, you are guessing.
Milestone Setting
A project without milestones is a project without accountability. You will not know if you are on track until you are either done or very late.
Good milestones are:
- Concrete and verifiable. "Backend API complete and tested" is a milestone. "Making good progress on backend" is not.
- Spaced regularly. For a three-month project, you want milestones every one to two weeks. Longer gaps and you lose visibility.
- Meaningful. Each milestone should represent real, demonstrable progress. Not busy work, not intermediate artifacts nobody cares about.
Resource Allocation
This is where you think about who does what, and whether you have the right people available.
- Match skills to work. Put your strongest database engineer on the complex data migration, not your frontend specialist.
- Account for availability. People take vacation. People get sick. People get pulled into incidents. Plan for this.
- Avoid single points of failure. If only one person can do the critical-path work, you have a risk. Make sure knowledge is shared.
Risk Identification
Every project has risks. The good EMs identify them up front and plan for them. The bad EMs are "surprised" when predictable things go wrong.
Common risks to think about:
- Technical risks: new technology, complex integrations, unclear performance requirements
- People risks: key person leaving, team member overloaded, skill gaps
- Dependency risks: waiting on another team, third-party API, vendor deliverable
- Scope risks: requirements still changing, stakeholder alignment not solid
For each risk, ask: what is the likelihood, what is the impact, and what is the mitigation plan?
3. Milestone Tracking
Setting milestones is step one. Tracking them is where the real work happens.
Define Clear Milestones
Every milestone needs three things:
- A specific deliverable. What exactly will be done?
- A due date. When will it be done?
- Acceptance criteria. How will we know it is actually done?
That last one is critical. Without clear acceptance criteria, you get the dreaded "we are 90% done" status that lasts for three weeks. If you have heard that before — and you have — it is because "done" was never defined.
Track Progress
How you track depends on your team and context, but some principles are universal:
- Check in regularly. Weekly at minimum for multi-week projects. Daily standups can help but only if they are focused on blockers, not status recitation.
- Use leading indicators, not lagging ones. Do not wait until a milestone is missed to realize you are behind. Look at velocity, blockers, open questions. Are engineers stuck? Are dependencies coming in late? These are early warning signs.
- Make progress visible. A simple dashboard, a weekly email, a shared doc — whatever works for your team. The point is that everyone, including stakeholders, can see where things stand without having to ask.
Identify Slippage Early
Here is the key insight: slippage is almost never sudden. Projects do not go from "on track" to "three weeks late" overnight. They slip gradually — a day here, two days there — and if you are not watching closely, the small slips accumulate into a big miss.
Signs of slippage:
- Tasks taking longer than estimated
- Engineers discovering unexpected complexity
- Dependencies not arriving on time
- Scope quietly expanding
- Team members getting pulled to other work
When you see these signs, act immediately. Do not wait and hope things will get better. They will not.
Communicate Proactively
When a milestone is at risk, communicate immediately. Tell your stakeholders before they have to ask. This is hard because nobody likes delivering bad news, but it builds trust.
A good status update when things are off track:
- Here is where we are
- Here is where we expected to be
- Here is why there is a gap
- Here is what we are doing about it
- Here is the revised timeline
That is it. No excuses, no finger-pointing. Just facts, impact, and plan.
4. Shipping on Time
Shipping on time is not magic and it is not luck. It is the result of disciplined planning, honest estimation, and the willingness to make hard trade-offs.
Clear Scope
We covered this in planning, but it bears repeating: unclear scope is the number one reason projects ship late. If your team is building something and the "something" keeps changing, you are not late — you are chasing a moving target.
Lock the scope. If new requirements come in after you have started, they go into the next phase, not this one. Be friendly but firm about this.
Good Estimation
Estimation is hard. Software estimation is especially hard. But there are ways to be less wrong:
- Break work into small pieces. Estimating a one-week task is much more accurate than estimating a three-month project.
- Use historical data. How long did similar work take last time? That is your best predictor.
- Add buffer for unknowns. The rule of thumb: take your best estimate and add 30-50%. This is not padding — this is accounting for reality. Things always take longer than expected.
- Get multiple perspectives. Have the person doing the work estimate, but also get input from others. Anchoring bias is real.
- Estimate in ranges, not points. "This will take 2-3 weeks" is more honest and more useful than "this will take 2.5 weeks."
The Iron Triangle
You have heard this before, but it bears repeating because many people still do not internalize it:
Scope, Time, Quality — pick two.
- Want it fast with full scope? Quality will suffer.
- Want it high quality with full scope? It will take longer.
- Want it fast and high quality? You need to cut scope.
In practice, quality should almost never be the thing you sacrifice. Technical debt compounds, bugs erode user trust, and cutting corners now means paying double later.
So the real choice is usually between scope and time. And the right answer is almost always: cut scope, not time. Ship something smaller but complete, rather than something large but half-baked.
This means having honest conversations with stakeholders about what is essential versus what is nice-to-have. The MVP mindset is your friend here.
Buffer for Unknowns
Every project has unknowns. Things you did not anticipate. Bugs that are harder to fix than expected. Integration issues that surface late.
Build buffer into your timeline. Not hidden buffer — explicit buffer. Tell stakeholders: "We estimate three weeks of development work, and we are planning for a four-week timeline to account for unknowns." This is not sandbagging. This is responsible planning.
5. Time-to-Market
Time-to-market is the total elapsed time from "we have an idea" to "customers are using it." It is broader than just development time, and that is exactly why so many teams optimize the wrong thing.
The Full Pipeline
Think about every step an idea goes through:
- Ideation and prioritization — Someone has an idea. It gets discussed, evaluated, prioritized.
- Planning and design — Requirements are written. Designs are created. Technical approach is decided.
- Development — Code is written.
- Code review — Code is reviewed and approved.
- Testing — QA, automated tests, manual testing.
- Deployment — Code goes to production.
- Rollout — Feature is enabled for users.
- Measurement — Impact is assessed.
Most teams focus on step 3 — making development faster. But often the biggest wins are in the other steps. If your planning phase takes three weeks and development takes two, cutting development time in half saves you one week. Cutting planning time in half saves you one and a half weeks.
Where to Look for Speed
Planning time. Are you over-planning? Do you really need three rounds of design review for every feature? Sometimes you do. Often you do not. Right-size the planning to the risk level of the work.
Development time. Good tooling, clear requirements, minimal context switching. These are the levers. Not working more hours.
Review time. How long do pull requests sit before someone reviews them? If the answer is "days," that is a problem. Set expectations: reviews happen within hours, not days. Consider smaller PRs that are easier and faster to review.
Testing time. Invest in automated testing. Manual testing cycles are slow and do not scale. A good CI pipeline should give you confidence in minutes, not days.
Deployment time. How long does it take to deploy to production? If the answer is more than an hour, invest in improving it. Teams that can deploy in minutes ship much more frequently than teams where deployment is a half-day ordeal.
Rollout time. Feature flags let you decouple deployment from release. Deploy the code, then turn on the feature when you are ready. This removes deployment as a bottleneck from your release timeline.
Measuring Time-to-Market
You cannot improve what you do not measure. Track:
- Lead time: Time from work starting to work reaching production
- Cycle time: Time from first commit to production deployment
- Deployment frequency: How often you deploy to production
These are DORA metrics, and they are well-established indicators of delivery performance. Track them. Trend them. Improve them.
6. Release Management
Shipping is not just pushing code to production and hoping for the best. Good release management is what separates confident shipping from reckless shipping.
Release Cadence
How often should you release? The answer is: as often as you can do it safely.
- Continuous deployment is the gold standard. Every merged commit goes to production automatically. This requires excellent automated testing and monitoring, but the payoff is enormous.
- Daily or weekly releases are a good middle ground for many teams. Regular enough to keep the feedback loop tight, structured enough to coordinate.
- Monthly or quarterly releases are a red flag for most web-based products. The feedback loop is too long, the releases are too big, and the risk per release is too high.
Smaller, more frequent releases are almost always better than larger, less frequent ones. Each release carries less risk, is easier to debug if something goes wrong, and gets value to customers sooner.
Feature Flags
Feature flags are one of the most powerful tools in your delivery toolkit. They let you:
- Deploy code without releasing features. The code is in production but the feature is off. You can turn it on when you are ready.
- Do gradual rollouts. Enable for 1% of users, then 10%, then 50%, then 100%. Monitor at each stage.
- Run experiments. A/B test new features against the current experience.
- Kill switch. If something goes wrong, turn off the feature without deploying new code.
If your team is not using feature flags, investing in that infrastructure is one of the highest-leverage things you can do.
Staged Rollouts
Do not release to 100% of users on day one unless you have to. A staged rollout looks like this:
- Internal dogfooding. Your team and company use it first.
- Beta users. A small group of willing external users.
- Percentage rollout. Gradually increase the percentage of users who see the feature.
- Full rollout. Everyone gets it.
At each stage, monitor for issues. If something is wrong, you have caught it before it affects everyone.
Rollback Plans
Before every release, know the answer to this question: "If this goes wrong, how do we undo it?"
- Can you roll back the deployment?
- If there are database migrations, are they reversible?
- Do you have feature flags that can disable the new functionality?
- What is the expected rollback time?
Having a rollback plan is not pessimism. It is professionalism.
7. Handling Slippage
Projects will slip. Not every project, not every time, but often enough that you need a playbook for dealing with it. The measure of a good EM is not whether slippage happens — it is how you handle it when it does.
Detect Early
This is where your milestone tracking pays off. If you have clear milestones with clear dates and clear acceptance criteria, you will know quickly when things are falling behind.
Watch for:
- Milestones being missed or pushed back
- Engineers expressing concern or frustration
- Blockers that are not getting resolved
- Scope expanding without timeline adjusting
- The "almost done" status that does not change for days
Trust your gut, too. If something feels off, dig in. Ask questions. Look at the work. Experienced EMs develop a sense for when a project is in trouble, even before the metrics show it.
Communicate Immediately
The moment you know a project is at risk, communicate it. Do not wait until you have a solution. Do not wait until the milestone is officially missed. Do not wait until someone asks.
Tell your manager. Tell your stakeholders. Tell them:
- What is happening
- Why it is happening
- What the impact is
- What you are doing about it
The worst thing you can do is hide slippage. It always comes out eventually, and when it does, you have lost trust on top of losing time.
Re-scope If Needed
When a project is behind, you have a few options:
- Add time. Push the deadline back. This is sometimes the right call, but be honest about the new timeline.
- Cut scope. Remove features or simplify requirements to hit the original date. This is often the best option.
- Add people. Usually the wrong call. Brooks's Law is real: adding people to a late project makes it later. There are exceptions, but they are rare.
- Reduce quality. Almost never the right call. You will pay for it later.
The best approach is usually to cut scope. Go back to your MVP definition. What is the smallest thing you can ship that still delivers value? Ship that, then follow up with the rest.
Learn for Next Time
After every significant slippage, do a lightweight retrospective:
- Why did we slip?
- When did we first know we were at risk?
- Could we have detected it earlier?
- What would we do differently next time?
This is not about blame. It is about getting better. Every slip is a learning opportunity, but only if you actually take the time to learn.
8. Post-Launch
Too many teams treat shipping as the finish line. It is not. Shipping is the starting line for learning.
Monitor
The first hours and days after launch are critical. You should be watching:
- Error rates. Are errors spiking? Are there new error types?
- Performance. Is latency increasing? Are response times degrading?
- User behavior. Are users actually using the new feature? Are they using it the way you expected?
- System health. CPU, memory, database connections — is anything stressed?
Have dashboards set up before you launch. Know what "normal" looks like so you can spot "abnormal" quickly.
Measure
Once the initial launch dust settles, measure the impact:
- Feature adoption. What percentage of users are using the new feature? Is adoption growing or flat?
- Business metrics. Did the feature move the needle on the metric you were targeting? Revenue, engagement, retention — whatever the goal was.
- User satisfaction. Are users happy with the feature? NPS scores, support tickets, app store reviews — look at the signals.
If you shipped without a clear success metric, that is a process problem to fix for next time. Every feature should have a definition of success before development starts.
Iterate
Based on what you learn, iterate:
- Fix bugs that users report
- Improve UX based on observed behavior
- Add capabilities that users are asking for
- Remove or simplify things that are not being used
This is the learning loop: ship, measure, learn, improve, ship again. The faster you go around this loop, the better your product gets.
Bug Reports and Customer Feedback
Set up channels to collect and triage feedback:
- Monitor support tickets related to the new feature
- Watch social media and community forums
- Talk to your customer-facing teams — support, sales, customer success
- If possible, talk directly to users
Not every piece of feedback requires action, but every piece of feedback contains information. Your job is to synthesize it and decide what to do next.
9. Real-World Examples
Scenario 1: The Team That Shipped a Major Feature on Time
A payments team needed to launch a new checkout flow in eight weeks to support a major partnership launch. The EM did several things right:
Clear scoping from day one. The EM sat down with product and engineering leads and defined exactly what "launch" meant. They identified twelve features that were requested and classified them as must-have (five features), should-have (four features), and nice-to-have (three features). Only the must-haves were in scope for the eight-week timeline.
Weekly milestones. Every Friday, the team demoed progress against the milestone. Stakeholders could see exactly where things stood. No surprises.
Risk identification and mitigation. In week two, they identified that the payment processor's sandbox environment was unreliable, which could slow integration testing. The EM escalated to the vendor immediately and also had the team build a mock service as a backup. When the sandbox went down for three days in week five, they were ready.
Scope discipline. In week four, a stakeholder requested adding support for a fourth payment method. The EM said: "We can absolutely do that in phase two. Adding it now puts the launch date at risk." The stakeholder was initially unhappy but understood when the EM showed the timeline impact.
They launched on day one of week eight. The five must-have features worked flawlessly. Phase two, with the remaining features, shipped four weeks later.
Scenario 2: The Project That Slipped Three Months
A platform team was building a new internal service to replace a legacy system. Estimated timeline: three months. Actual timeline: six months.
What went wrong:
The scope was never clearly defined. The requirements doc said "replicate existing functionality," but nobody had a complete inventory of what the existing system actually did. Engineers kept discovering edge cases and undocumented behaviors that had to be replicated.
There were no milestones. The team had a start date and an end date, with nothing in between. For the first two months, status updates were some variation of "making good progress." By the time anyone realized they were behind, they were already six weeks off track.
The EM did not push back on scope. When stakeholders added requirements — "while you are at it, can you also..." — the EM said yes without adjusting the timeline. By month two, the project had grown 40% from the original scope with no change to the deadline.
There was no rollback plan. The original plan was a big-bang cutover from old system to new system. When the new system was not ready on time, there was no intermediate option. It was all or nothing.
What should have happened:
A thorough audit of the existing system before scoping. Clear milestones every two weeks. A firm scope boundary with a change request process. A phased migration plan instead of a big-bang cutover.
Scenario 3: The EM Who Reduced Time-to-Market by 40%
An EM at a mid-stage startup noticed that while their team wrote code quickly, features took forever to reach users. She decided to measure the full pipeline.
The findings:
- Average time from idea to production: 47 days
- Planning and design: 12 days
- Development: 10 days
- Code review: 5 days (PRs sat for an average of two days before first review)
- QA and testing: 8 days
- Deployment and rollout: 12 days (deployments happened biweekly, so features often waited)
Development was only 21% of the total time. The rest was waiting, process, and overhead.
The changes:
She implemented a "24-hour review SLA" — all PRs must receive a first review within 24 hours. Code review time dropped from five days to two.
She invested in automated testing and reduced the QA cycle from eight days to three.
She pushed for weekly deployments, then moved to continuous deployment over six months. Deployment wait time dropped from twelve days to less than one day.
She simplified the planning process for small features (less than one week of development) — a one-page brief instead of a full requirements document. Planning time for these features dropped from twelve days to three.
The result: Average time from idea to production dropped from 47 days to 28 days — a 40% reduction. And because the team was shipping more frequently, they were learning faster and building better features.
10. Common Mistakes
No Milestones
Running a multi-week project without milestones is like driving cross-country without a map. You might get there eventually, but you will not know if you are on track until you either arrive or run out of gas.
Set milestones. Track them. It is not bureaucracy — it is navigation.
Optimistic Estimates
Engineers are optimists by nature. "That should only take a couple days" is the most dangerous sentence in software development.
Always ask: "What could go wrong? What are you assuming? Have we done something like this before, and how long did it actually take?" Calibrate estimates against reality, not hope.
Scope Creep Tolerance
Scope creep does not announce itself. It sneaks in through "quick additions," "small tweaks," and "while you are at it" requests. Each one seems harmless individually. Collectively, they blow up your timeline.
Have a change request process. It does not need to be heavy — just a conscious decision: "Yes, we are adding this to scope, and here is the impact on timeline" or "No, that goes in the next phase."
Big-Bang Releases
Saving up three months of work for one massive release is risky, stressful, and unnecessary. If anything goes wrong, debugging is a nightmare because so much changed at once.
Ship small. Ship often. Each release is less risky, easier to debug, and gets value to users sooner.
Not Learning from Past Projects
If you are making the same estimation mistakes, hitting the same kinds of problems, and experiencing the same kinds of slippage project after project, you are not learning.
Run retrospectives. Track your estimation accuracy. Identify patterns. Improve your process. This is how teams get better over time.
Confusing Activity with Progress
A team can be very busy and make no progress. Lots of meetings. Lots of code written. Lots of Jira tickets moved. But no features shipped.
Focus on outcomes, not outputs. The question is not "how busy is the team?" It is "what have we shipped, and what value has it created?"
Ignoring Dependencies
Your timeline means nothing if you are waiting on another team to deliver an API, or a vendor to provision access, or a partner to approve a design. Identify dependencies early, track them actively, and have contingency plans.
Business Value
Delivery management is not just an engineering discipline. It is a business discipline. Here is the direct business impact:
Revenue from Faster Shipping
Every week a revenue-generating feature sits in development instead of in production is a week of lost revenue. If a feature is expected to generate 200K left on the table. This math is simple, and it is compelling.
Faster shipping also means faster experimentation. You can test more ideas, find the winners sooner, and double down. The team that runs twenty experiments per quarter will find more winners than the team that runs five.
Competitive Advantage
In competitive markets, shipping speed is a weapon. The first company to solve a customer problem wins the customer. The first company to respond to a market shift captures the opportunity.
Your competitors are not standing still. If you are slow, they will ship the feature your customers are asking for before you do. And once a customer has switched, getting them back is ten times harder than keeping them in the first place.
Customer Trust
Customers trust companies that deliver on their promises. If you say a feature is coming in Q2 and it ships in Q2, that builds trust. If it slips to Q4, that erodes trust.
Reliable delivery also means you can make commitments to customers — in sales conversations, in contracts, in public roadmaps — with confidence. That is a business superpower.
Reduced Waste
Slow delivery is wasteful. Features that take too long to ship often become irrelevant by the time they launch. Market conditions change. Customer needs evolve. Competitive landscape shifts.
Fast delivery reduces this waste. You ship smaller increments, validate them quickly, and course-correct before you have invested too much in the wrong direction.
Team Retention
Engineers want to work on teams that ship. They want to see their work in production, making a difference for real users. Teams with poor delivery track records have higher attrition, which creates a vicious cycle — losing experienced people makes delivery even harder.
Good delivery management creates a virtuous cycle instead: ship, succeed, attract great people, ship more, succeed more.
Pulling It All Together
Delivery management is where all of your EM skills come together. You need technical judgment to evaluate estimates and risks. You need people skills to motivate the team and manage stakeholders. You need organizational skills to track milestones and dependencies. You need communication skills to report status and escalate issues.
Here is your checklist for every significant project:
- Before starting: Clear scope, defined milestones, identified risks, realistic timeline with buffer
- During development: Track milestones weekly, watch for slippage signals, communicate proactively, protect scope
- Before launch: Rollback plan, monitoring dashboards, staged rollout plan, communication plan
- After launch: Monitor health, measure impact, collect feedback, iterate
And here is the mindset to carry with you: shipping is the goal. Not perfect code, not complete features, not elegant architectures. Shipping valuable software to real users, learning from their response, and shipping again. That is the game, and your job is to make sure your team plays it well.
The best EMs I have worked with are not the ones with the most sophisticated project management tools or the most detailed Gantt charts. They are the ones who relentlessly focus on getting valuable work into customers' hands, who communicate honestly about where things stand, and who keep getting better at it over time.
That is what delivery management is about. Not process for the sake of process. Not tracking for the sake of tracking. Speed and reliability in service of building great products that win in the market.
Common Pitfalls
- Running projects without milestones. A multi-week project without concrete, verifiable checkpoints is like driving cross-country without a map. You will not know if you are on track until you either arrive or run out of gas.
- Accepting optimistic estimates without calibration. Engineers are natural optimists. "That should only take a couple days" is the most dangerous sentence in software development. Always calibrate estimates against historical data and add buffer for unknowns.
- Tolerating scope creep without adjusting timelines. Scope creep sneaks in through "quick additions" and "while you are at it" requests. Each seems harmless individually, but collectively they blow up your timeline. Every scope change should be a conscious decision with an explicit impact assessment.
- Saving up work for big-bang releases. Accumulating three months of changes for a single massive release is risky, stressful, and hard to debug when things go wrong. Small, frequent releases are almost always safer and get value to customers sooner.
- Hiding slippage instead of communicating it immediately. The worst thing you can do when a project falls behind is wait and hope things improve. They will not. Bad news early is manageable and builds trust. Bad news late destroys it.
- Confusing activity with progress. A team can be very busy — lots of meetings, lots of code written, lots of Jira tickets moved — and still make no progress toward shipping. Focus on outcomes and shipped value, not on how busy the team appears.
Key Takeaways
- Speed is a competitive advantage that compounds. Faster shipping means faster learning, faster iteration, faster improvement, and better talent attraction. Your job is to remove friction, not to demand more hours.
- Good scoping is the single biggest determinant of on-time delivery. Define outcomes (not just outputs), draw clear boundaries, identify the MVP, and involve your engineers in the process.
- Set concrete milestones with specific deliverables, due dates, and acceptance criteria. Track them weekly and watch for leading indicators of slippage — tasks taking longer than estimated, engineers expressing concern, dependencies arriving late.
- The Iron Triangle (scope, time, quality) is real. In practice, quality should almost never be sacrificed. The right choice is usually to cut scope, not time — ship something smaller but complete rather than something large but half-baked.
- Time-to-market encompasses the entire pipeline from idea to customer usage. Development is often only 20-30% of total elapsed time. The biggest wins frequently come from reducing planning overhead, review wait times, and deployment friction.
- Feature flags, staged rollouts, and rollback plans are essential tools for confident, safe shipping. They decouple deployment from release and dramatically reduce the risk of each change.
- When slippage occurs, communicate immediately with facts, impact, and a plan. Then re-scope if needed — cut to the MVP, add time honestly, but almost never add people to a late project.
- Post-launch monitoring, measurement, and iteration complete the learning loop. Shipping is not the finish line — it is the starting line for learning what works and what to build next.