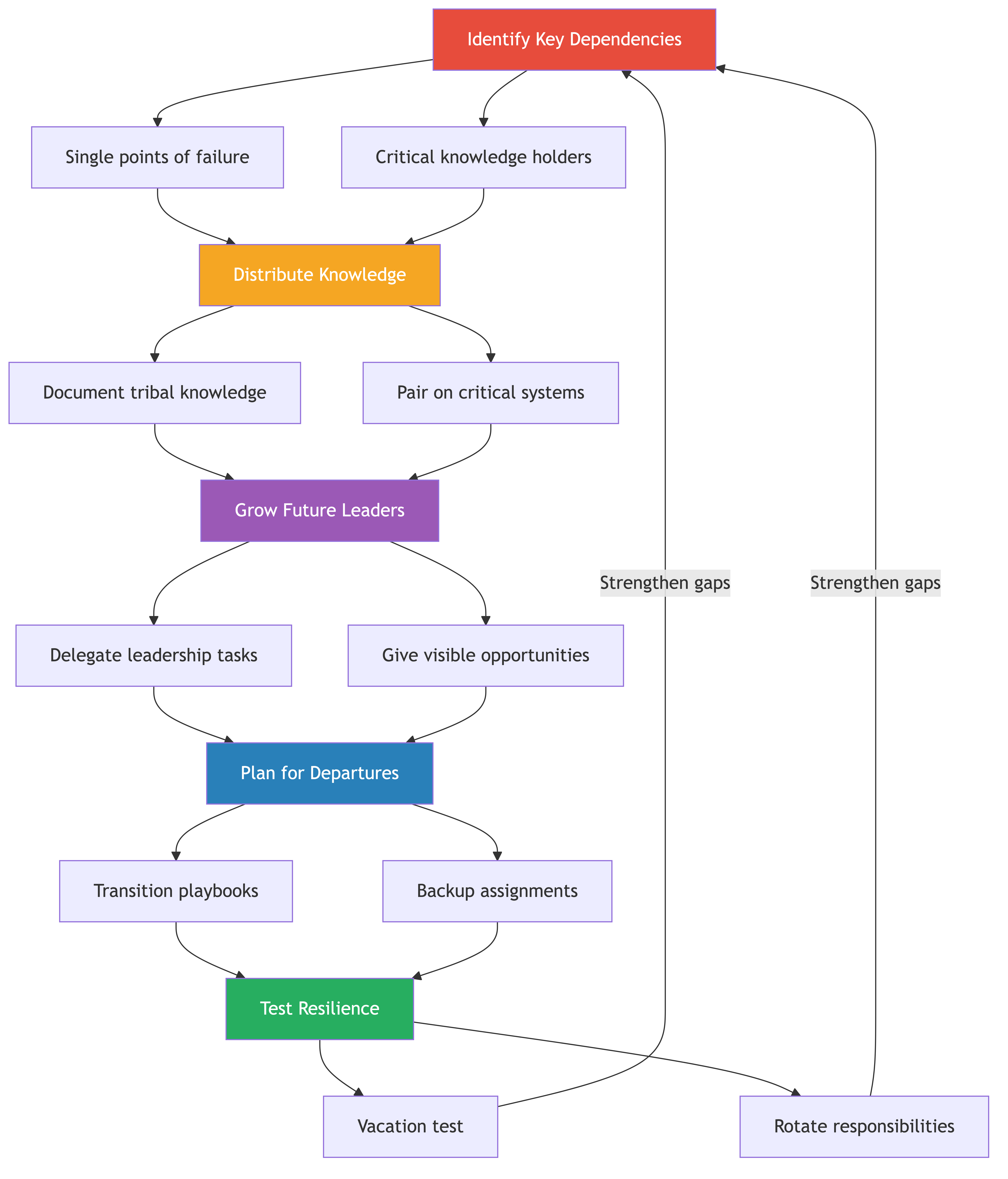
Succession Planning
Let me start with a question that will make you uncomfortable: if you got hit by a bus tomorrow, what would happen to your team?
Not "would they be sad." I mean operationally. Would they know what to do? Could they ship? Could they deploy? Would they know which stakeholders to talk to, which systems are fragile, which decisions are pending? Or would everything grind to a halt while people scramble to figure out what you knew that nobody else does?
Now ask the same question about every person on your team. If your senior engineer who built the billing system quits tomorrow, what breaks? If your tech lead who is the only person who understands the deployment pipeline goes on parental leave for three months, can the team still ship?
If the answer to any of these questions is "things would fall apart," you do not have a team. You have a collection of single points of failure held together by luck. And luck is not a strategy.
Succession planning is about fixing that. It is not an HR exercise. It is not something you do once a year in a spreadsheet that nobody reads. It is a continuous, deliberate effort to make sure your team can survive — and thrive — regardless of who walks out the door.
The Bus Factor
The bus factor is the number of people who would need to be "hit by a bus" (or quit, or go on extended leave, or get poached by a competitor) before your team can no longer function. If that number is one, you are in serious trouble.
Every team has some degree of key-person dependency. That is natural. People specialize. People become experts. The problem is not that someone knows more about a system than anyone else. The problem is when only one person knows about a system and nobody else can even begin to operate it.
Here is a simple test. For each critical system, process, or piece of knowledge your team owns, ask: "If the person who knows this best disappeared tomorrow, could someone else pick it up within a week?" If the answer is no, your bus factor for that area is one.
Common places where bus factor equals one:
- Deployment processes that only one person knows how to run
- Legacy systems that one engineer built five years ago and nobody else has touched since
- Vendor relationships where one person is the sole contact
- Domain knowledge about business rules that live in one person's head
- On-call runbooks that do not exist because one person "just knows" what to do
- Infrastructure configuration that was set up once and never documented
A bus factor of one is not a personnel problem. It is a business risk. And it is your job as the engineering manager to identify it, measure it, and fix it.
Why EMs Need Succession Plans
Some managers think succession planning is something that happens at the VP level. Directors plan for their replacements. C-suite executives have succession plans mandated by the board. Why would an engineering manager managing six to ten engineers need a succession plan?
Because you are responsible for team continuity. Full stop.
Your team is a living system. People join and people leave. That is not a failure — it is a fact. The average tenure at a tech company is somewhere between two and four years. That means over a four-year period, you should expect most of your team to turn over. If your team cannot handle that natural churn without major disruption, you have built something fragile.
Here is what succession planning actually covers for an EM:
Your own role. If you leave, who steps in? Have you developed anyone who could take over your responsibilities? If not, you are a single point of failure, and that is a failure of leadership.
Key technical roles. Your senior engineer, your tech lead, your infrastructure expert. Who is being developed to fill those roles if they open up? Do you have people growing into those positions, or will you have to do a frantic external hire?
Critical knowledge. Not just who holds it, but how it is being transferred. Is knowledge flowing from the people who have it to the people who need it? Or is it being hoarded — intentionally or not?
Process continuity. Can your team run its own ceremonies, make its own decisions, and resolve its own conflicts without you in the room? If everything requires your approval or your presence, you have built a bottleneck, not a team.
The reason this is your job and not someone else's is simple: you are the person closest to the team who has the authority and the context to do something about it. Your skip-level manager does not know the day-to-day well enough. Your team members do not have the organizational perspective. You are the one who can see both the people and the system, and you are the one who can shape how knowledge flows, how responsibilities are shared, and how leadership is developed.
Identifying Key-Person Dependencies
Before you can fix single points of failure, you have to find them. This requires honest assessment, and sometimes the results are uncomfortable.
The Knowledge Map
Sit down and make a list of every critical area your team owns. Systems, processes, relationships, domain knowledge. Then next to each one, write down who knows it well enough to operate independently. Not "who has heard of it." Who can actually do the work without help.
Here is a template:
| Critical Area | Primary Expert | Backup(s) | Risk Level |
|---|---|---|---|
| Payment processing system | Sarah | Nobody | Critical |
| CI/CD pipeline | James | Sarah (partial) | High |
| Customer data migration | Alex | James, Maria | Low |
| Vendor relationship (Stripe) | Sarah | You | High |
| Sprint planning / stakeholder comms | You | Nobody | Critical |
When you see "Nobody" in the backup column, that is your problem. When you see your own name as the only primary or backup, that is also your problem.
Questions to Ask
Walk through these for every person on your team:
- What would we lose if this person left tomorrow?
- What do they know that nobody else knows?
- What do they do that nobody else can do?
- Are there systems only they can access?
- Are there processes only they understand?
- Are there relationships only they maintain?
Watch for Hidden Dependencies
Some key-person dependencies are not obvious. They are not about technical knowledge — they are about soft skills, institutional memory, or social capital.
The engineer who is the only one who knows how to talk to the difficult product manager. The person who remembers why a particular architectural decision was made three years ago and why the obvious "improvement" will actually cause a regression. The team member who informally mentors new hires and is the reason your onboarding actually works.
These dependencies are harder to see and harder to transfer. But they matter just as much.
The Honest Conversation
Sometimes you need to just ask directly. In a one-on-one, try: "Hey, I am thinking about team resilience. If you had to take a three-month leave starting next week, what would the team struggle with the most?" People usually know exactly where the risks are. They have just never been asked.
Knowledge Distribution
Once you have identified your key-person dependencies, the next step is to spread knowledge deliberately. This does not happen by accident. If you leave it to chance, knowledge will continue to concentrate in the same people who already hold it.
Pair Programming and Pairing
Pair programming is not just a code quality tool. It is a knowledge transfer mechanism. When your senior engineer who built the billing system pairs with a mid-level engineer on billing-related work, knowledge flows naturally. No documentation required. No formal training session. Just two people working together.
The key is to be intentional about who pairs with whom. If Sarah is your only billing expert, do not let her work on billing alone. Every billing task should involve someone else. Yes, it is slower in the short term. But in the long term, it is the difference between a team that functions and a team that collapses when Sarah leaves.
Documentation
I know. Nobody likes writing documentation. But some things need to be written down. Not everything — you do not need a document for how to write a for loop. But you do need documentation for:
- How to deploy. Step by step. Screenshots if needed. A new engineer should be able to follow it.
- System architecture. Not a novel. A diagram and a few paragraphs explaining why the system is shaped the way it is.
- Runbooks for incidents. When the system breaks at 2 AM, what do you do? If the answer is "call Alex," that is not a runbook.
- Business rules and domain logic. Why does the pricing system have seventeen edge cases? Write it down before the person who knows leaves.
- Decision records. Why did we choose Postgres over DynamoDB? Why is the auth service separate from the user service? Write it down so the next person does not reverse a good decision out of ignorance.
The best time to write documentation is when the knowledge is fresh. The second best time is now. Make documentation a part of the work, not an afterthought.
Rotation of Responsibilities
If the same person always handles deployments, only that person learns deployments. If the same person always runs the sprint retrospective, only that person learns facilitation. Rotate.
Some things to rotate:
- On-call responsibility. Everyone should do on-call. Not just the senior engineers. Yes, junior engineers will need more support. That is how they learn.
- Code review for critical systems. If only one person reviews billing code, expand who reviews it.
- Sprint facilitation. Let different people run standups, retros, and planning sessions.
- Stakeholder communication. Bring other engineers into meetings with product managers and leadership. Do not be the sole translator between your team and the rest of the organization.
- Incident response. Rotate the incident commander role. Give people practice making decisions under pressure.
Cross-Training
Cross-training is more structured than pairing. It is deliberately teaching someone a new area so they can operate independently. This takes time and investment, but it pays off enormously.
A practical approach: identify your top three key-person dependencies. For each one, assign a "backup" person. Give that backup person dedicated time — maybe 20 percent of their sprint capacity — to learn the area. Have the primary expert mentor them. Set a goal: in three months, the backup should be able to handle routine work independently. In six months, they should be able to handle most work.
This is not free. It costs velocity in the short term. But it is insurance, and insurance costs money. The alternative is hoping nobody leaves, and hope is not a strategy.
Growing Your Replacement
Here is a truth that some managers resist: the best leaders make themselves replaceable.
If you cannot take a two-week vacation without your team struggling, you have not built a team — you have built a dependency on yourself. If you are the only person who can make decisions, resolve conflicts, interface with stakeholders, and unblock engineers, you are a bottleneck, not a leader.
Growing your replacement is not about planning your own exit (though it is useful for that too). It is about building a team that is resilient, capable, and empowered.
What This Looks Like in Practice
Delegate real authority, not just tasks. Do not just ask someone to "run the standup." Give them the authority to make decisions in that standup. Let them resolve disagreements. Let them adjust priorities within the sprint. Give them the room to lead, not just to facilitate.
Share your context. The biggest gap between you and your team is not skill — it is context. You know things they do not because you are in meetings they are not in. Close that gap. Share what you learn from leadership. Explain the business context behind priorities. When you make a decision, explain your reasoning so others can learn to make similar decisions.
Let people fail safely. If you have identified someone who could grow into your role, give them stretch assignments where the stakes are manageable. Let them lead a project. Let them handle a difficult conversation. Let them make a decision you disagree with (within reason). The lessons from small failures are more valuable than any amount of instruction.
Step back visibly. When you are developing someone as a potential successor, physically step back. Let them run the meeting. Let them present to leadership. Let them be the point of contact for a stakeholder. Be available for coaching, but do not be in the room.
The Ego Trap
Some managers resist making themselves replaceable because it feels threatening. If anyone can do my job, why do they need me?
They need you because you chose to develop people. You chose to distribute knowledge. You chose to build a team that does not depend on any single person, including you. That is leadership. If you are doing it well, you will always be needed somewhere — because people who can build resilient teams are rare.
Your value is not in being irreplaceable. Your value is in your ability to build teams that do not need you. That is a skill that scales infinitely.
Leadership Pipeline
Succession planning is not just about replacing people who leave. It is about building a pipeline of future leaders so that when opportunities arise — promotions, new teams, organizational growth — you have people ready to step in.
Identifying Future Leaders
Not every strong engineer wants to be a leader, and not every person who wants to lead will be good at it. Look for these signals:
- They naturally mentor others. Without being asked, they help junior engineers, explain concepts, and review code thoughtfully.
- They think about the team, not just themselves. They care about team processes, team health, and team outcomes — not just their own work.
- They communicate well across audiences. They can explain a technical problem to a product manager and a business problem to an engineer.
- They handle ambiguity. When the requirements are unclear, they do not freeze. They ask good questions, make reasonable assumptions, and move forward.
- They take ownership beyond their immediate scope. They notice problems and fix them even when it is not "their job."
Developing Future Tech Leads
A tech lead is an engineer who takes on coordination, technical direction, and some degree of people leadership while still being hands-on with code. It is often the first step toward engineering management, though many great tech leads stay in that role permanently.
To develop future tech leads:
- Give them ownership of a project. Not just the coding — the planning, the stakeholder communication, the technical decisions, the delivery.
- Have them lead design reviews. Let them be the one presenting architecture to the team and defending decisions.
- Put them in charge of a workstream. Give them two or three engineers to coordinate with. Let them practice prioritization and delegation.
- Include them in your meetings. Bring them to cross-team syncs, planning sessions, and stakeholder meetings so they see what the role actually involves.
- Coach them on soft skills. Technical skills got them to senior engineer. Communication, influence, and conflict resolution will get them to tech lead.
Developing Future EMs
If someone on your team is interested in engineering management, help them explore the role honestly. Do not sugarcoat it — management is not a promotion. It is a career change. Make sure they understand what they are signing up for.
To develop future EMs:
- Have them run one-on-ones with interns or new hires. This gives them a taste of people management without high stakes.
- Let them lead hiring. Have them own a hiring loop — writing the job description, designing the interview, making the recommendation.
- Give them a conflict to resolve. When there is a disagreement on the team (technical or otherwise), let them mediate instead of stepping in yourself.
- Have them own a process. Let them redesign the team's sprint process, or own the on-call rotation, or drive a team retro series.
- Talk openly about your own role. Share the parts of management that are hard. Share how you make decisions. Share the things you struggle with. Demystify the role.
Handling Departures
Someone key is leaving. Maybe they gave two weeks' notice. Maybe you are lucky and they gave a month. Either way, the clock is ticking and you need a plan.
The First 24 Hours
When a key person gives notice, your first reaction matters. Be human — thank them, wish them well, ask about their plans. Do not make them feel guilty. Do not panic visibly. Then, within 24 hours, start planning.
Assess the blast radius. What does this person own? What knowledge lives only in their head? What relationships do they maintain? Go back to your knowledge map (you made one, right?) and look at everything in the "Critical" and "High" risk columns that has their name on it.
Prioritize knowledge transfer. You cannot transfer everything in two weeks. Pick the top three to five things that absolutely must be documented or taught before they leave. Be ruthless about priority.
Identify the receivers. Who will take over each responsibility? Do not spread it across six people — that means nobody owns it. Pick one or two people for each area and make it explicit.
The Knowledge Transfer Plan
Structure the remaining time deliberately:
Week 1: Document and pair. The departing person writes down everything critical — architecture decisions, system quirks, operational procedures, contacts. At the same time, they pair with their successors on hands-on work.
Week 2: Shadow and solo. The successor takes the lead. The departing person watches, answers questions, fills gaps. By the end of the second week, the successor should be able to operate independently, even if not at the same level.
Before the last day: Make sure the successor has all necessary access — repository permissions, cloud console access, vendor contacts, meeting invites. These logistical details are easy to forget and painful to sort out after someone is gone.
The Documentation Sprint
If your departing team member has not been documenting as they go (and let us be honest, they probably have not), the notice period is your last chance. Set up dedicated time for documentation. Treat it like any other sprint task — put it on the board, assign story points, review it.
Focus on:
- System architecture and data flow for anything they own
- How to deploy the things they deploy
- How to debug the things that break
- Why things are the way they are — the decisions and context that are not obvious from the code
- Who to contact for external dependencies
After They Leave
The first month after a key person departs is when the real gaps show up. Things you thought were documented turn out to be incomplete. Systems break in ways you did not anticipate. Processes stall because of tribal knowledge you did not know existed.
This is normal. Do not panic. Treat each gap as a learning opportunity and a signal about where your succession planning needs to improve. Keep a running list of "things we did not know we did not know" and use it to improve your knowledge map for the future.
Real-World Examples
The Team That Survived
A payments team at a mid-size e-commerce company had invested heavily in knowledge distribution. Their principal engineer, who had built most of the payment processing system, had been pairing with two other engineers on every major change for over a year. They had comprehensive runbooks, architecture docs, and decision records. When the principal engineer left for a startup with three weeks' notice, the transition was smooth. The two backup engineers split ownership of the system. There was a brief dip in velocity while they got comfortable, but no outages, no missed commitments, and no fire drills. The team's on-call rotation continued without interruption.
What made this work: the investment happened before anyone knew the principal engineer was leaving. By the time the departure happened, the knowledge was already distributed. The notice period was used for polishing, not for panicking.
The Team That Collapsed
A platform infrastructure team at a Series B startup had one engineer — call him Dev — who had single-handedly built the CI/CD pipeline, the cloud infrastructure, the monitoring stack, and the deployment automation. Dev was brilliant, fast, and productive. He was also the only person who understood any of it. When Dev quit with two weeks' notice after a disagreement about compensation, the team was in immediate crisis. Deployments stalled because nobody knew how to run them. When the monitoring system broke, nobody could fix it. The team spent three months rebuilding knowledge that had walked out the door, during which they shipped almost nothing. Two other engineers quit during that period because they were frustrated with the chaos. The total cost, including lost productivity, additional hiring, and delayed product launches, was estimated at over half a million dollars.
What went wrong: Dev was allowed to become a single point of failure because he was productive and nobody wanted to "slow him down" with pairing or documentation. The short-term efficiency was not worth the long-term risk. The EM knew it was a problem but kept postponing the fix because there was always something more urgent. There is always something more urgent. Until there is not.
The EM Who Built a Pipeline
An engineering manager at a large financial services company made succession planning a core part of her management philosophy. Every quarter, she reviewed her team's knowledge map and bus factor analysis. She maintained a "leadership development" track for three engineers who had expressed interest in growing into tech lead and management roles. She gave them stretch assignments: one led a cross-team initiative, another ran the team's quarterly planning process, and the third took over stakeholder management for a key project.
Over two years, two of those engineers were promoted — one to tech lead on the same team, one to engineering manager of a newly formed team. When the EM herself was promoted to director, the new tech lead was ready to step into the EM role with minimal disruption. The team barely noticed the transition.
What made this work: succession planning was not a one-time event. It was a continuous practice. The EM invested consistently in developing people, distributing knowledge, and creating opportunities for growth. When the transitions happened, they felt natural rather than chaotic.
Common Mistakes
Not Planning Until Someone Gives Notice
This is the most common mistake. Everything is fine, nobody is leaving, so why bother with succession planning? Then someone gives notice and you have two weeks to transfer two years of knowledge. That math does not work.
Succession planning is like insurance. You buy it before you need it. If you wait until the house is on fire to get fire insurance, you are too late.
Knowledge Hoarding
Sometimes knowledge concentration is not accidental. Some people hoard knowledge deliberately because it makes them feel indispensable. They resist documentation, they resist pairing, and they resist cross-training. They want to be the only person who can do the thing because it gives them job security and leverage.
This is a management problem, not a technical problem. If someone on your team is hoarding knowledge, you need to address it directly. Make knowledge sharing an explicit expectation. Include it in performance reviews. Make it clear that being a single point of failure is not a strength — it is a risk that you need to mitigate.
Be compassionate about it. Sometimes people hoard knowledge because they are insecure about their value. Help them see that their value is not in what they know but in what they can do, teach, and build. But be firm. Knowledge hoarding cannot be tolerated because it puts the team and the business at risk.
Single Points of Failure in Process
It is not just people who can be single points of failure. Processes can be too. If deploying requires a specific person's approval, that is a process bottleneck. If only one person has admin access to the production database, that is a process risk. If all cross-team communication goes through you and nobody else, that is a process problem.
Audit your processes for single points of failure just like you audit your people. Wherever possible, make sure at least two people can perform any critical process.
Not Developing Future Leaders
Some managers are so focused on execution that they never invest in developing the next generation of leaders. Every sprint is about shipping features. There is no time for stretch assignments, no time for mentoring, no time for career development conversations.
This is shortsighted. If you do not develop leaders on your team, you will always be scrambling when leadership roles open up. You will always be hiring externally for tech leads and managers, which is more expensive, slower, and riskier than promoting from within. And your best people will leave because they do not see a growth path.
Make leadership development a part of your regular work, not something you do "when there is time." There is never time unless you make time.
Confusing Succession Planning with Replacement Planning
Succession planning is not just "who takes over if someone leaves." That is replacement planning, and it is only one piece. True succession planning is about building organizational resilience. It includes knowledge distribution, leadership development, process documentation, cross-training, and building a culture where no single person's departure is catastrophic.
If your succession plan is just a spreadsheet with names next to roles, you are doing replacement planning, not succession planning. The spreadsheet is necessary but not sufficient.
Business Value
If your leadership team asks why you are spending time on succession planning instead of shipping features, here is what you tell them.
Business Continuity
When a key person leaves a team without succession planning, the average recovery time is three to six months. During that time, velocity drops, commitments are missed, and other team members burn out picking up the slack. In the worst case, systems go down and nobody knows how to fix them. Succession planning is business continuity insurance. The cost of prevention is a fraction of the cost of recovery.
Reduced Risk
Key-person dependencies are a business risk that should be tracked just like technical debt, security vulnerabilities, or compliance gaps. A team with a bus factor of one is a team where a single resignation can cause a material business impact. Executives understand risk. Frame succession planning in those terms and you will get support.
Leadership Development
Companies that invest in developing internal leaders have a significant advantage over companies that always hire externally. Internal promotions are faster, cheaper, and more likely to succeed because the person already understands the culture, the codebase, and the people. A strong succession pipeline means you always have leaders ready when opportunities arise, whether from growth, attrition, or reorganization.
Team Resilience
Teams that practice knowledge distribution and cross-training are more resilient, more flexible, and more engaged. Engineers who learn new areas stay challenged and grow faster. Teams that rotate responsibilities develop broader skills and deeper empathy for each other's work. The practices that make succession planning work — pairing, documentation, cross-training, stretch assignments — also make teams better at their day-to-day work.
Talent Retention
People stay where they grow. If your team members see a clear development path, if they are learning new skills, if they are being trusted with increasing responsibility, they are less likely to leave. Ironically, investing in succession planning — preparing for people to leave — is one of the best things you can do to make them stay.
Making It Practical
Succession planning sounds like a big, heavy process. It does not have to be. Here is a lightweight approach you can start this week.
This week: Make your knowledge map. List every critical area your team owns and who knows it. Identify where your bus factor is one.
This month: For your top three risks, assign a backup person and create a plan for knowledge transfer. Start pairing on critical work.
This quarter: Review your team for leadership potential. Identify one or two people who could grow into tech lead or management roles. Give them a stretch assignment.
Every quarter going forward: Revisit your knowledge map. Update your bus factor analysis. Check on your leadership pipeline. Adjust your plans.
In every one-on-one: Ask about knowledge gaps. Ask what your team member would need to take on more responsibility. Ask what they are learning from their pairing and cross-training work.
This is not a one-time project. It is a practice. The teams that do it well do it continuously, as a natural part of how they operate. The teams that do it poorly do it once in a panic and then forget about it until the next crisis.
Build it into your rhythm, and the next time someone leaves — because someone will always leave — your team will absorb the impact and keep moving. That is what resilient teams do. And building resilient teams is what great engineering managers do.
Common Pitfalls
- Not planning until someone gives notice. Waiting until a key person is leaving to start succession planning means you have two weeks to transfer two years of knowledge. That math does not work. Succession planning is insurance you buy before you need it.
- Allowing knowledge hoarding to persist. Some people concentrate knowledge because it makes them feel indispensable. Whether intentional or not, a single person holding all the context for a critical system is a business risk that must be addressed directly through expectations, pairing, and documentation.
- Confusing succession planning with replacement planning. Having a spreadsheet of names next to roles is replacement planning, not succession planning. True succession planning includes knowledge distribution, leadership development, process documentation, cross-training, and building a culture where no single departure is catastrophic.
- Not developing future leaders because execution always comes first. There is never time for stretch assignments, mentoring, or career development conversations unless you make time. Without investing in the next generation of leaders, you will always be scrambling when leadership roles open up.
- Resisting making yourself replaceable. Some managers feel threatened by the idea that anyone could do their job. But your value is not in being irreplaceable — it is in your ability to build teams that do not depend on any single person, including you. That skill scales infinitely.
- Treating key-person dependencies as purely technical risks. Hidden dependencies on soft skills, institutional memory, and social capital — the person who knows how to work with the difficult stakeholder, or who remembers why an architectural decision was made — are harder to see and harder to transfer, but just as critical.
Key Takeaways
- The bus factor — the number of people who would need to leave before your team cannot function — is one of the most important risk metrics you should actively track and improve.
- Succession planning is not an HR exercise or an annual spreadsheet. It is a continuous, deliberate effort to make your team resilient regardless of who walks out the door.
- Start with a knowledge map: list every critical system, process, and piece of domain knowledge, identify who holds it, and flag everywhere the bus factor is one.
- Distribute knowledge deliberately through pair programming, documentation, rotation of responsibilities, and structured cross-training. This costs velocity in the short term but is insurance against catastrophic loss.
- Grow your replacement by delegating real authority, sharing your organizational context, letting people fail safely, and stepping back visibly so others can lead.
- Build a leadership pipeline by identifying future tech leads and EMs, giving them stretch assignments, including them in cross-functional meetings, and coaching them on the soft skills that leadership demands.
- Handle departures with a structured knowledge transfer plan: prioritize the top three to five areas of critical knowledge, assign specific receivers, and use the notice period for deliberate documentation and shadowing.
- The practices that make succession planning work — pairing, documentation, cross-training, stretch assignments — also make teams better at their day-to-day work. Investing in resilience is investing in performance.